admin / 16.09.2018
Elasticsearch vs sphinx
We invite representatives of system vendors to contact us for updating and extending the system information,
and for displaying vendor-provided information such as key customers, competitive advantages and market metrics.
» more
We invite representatives of 3rd party vendors to contact us for presenting information about their offerings here.
PostgreSQL is the DBMS of the Year 2017
2 January 2018, Paul Andlinger, Matthias Gelbmann
Elasticsearch moved into the top 10 most popular database management systems
3 July 2017, Matthias Gelbmann
MySQL, PostgreSQL and Redis are the winners of the March ranking
2 March 2016, Paul Andlinger
show all
The DB-Engines ranking includes now search engines
4 February 2013, Paul Andlinger
show all
150+ Customers Choose SearchBlox to Replace Their Google Search Appliance
15 June 2018, PR Newswire (press release)
Appel d’offres : ARCHITECTE ELASTICSEARCH HDFS
12 June 2018, la Nouvelle République
Could AI Help Reform Academic Publishing?
14 June 2018, Forbes
Service Management Group amplifies its text analytics technology to help brands turn qualitative feedback into …
14 June 2018, PR Newswire (press release)
SMG Announces New and Improved Text Analytics Technologies
15 June 2018, HR Technologist
provided by Google News
The unstoppable fashion force of Beyoncé- and five times she’s mastered the art of style messaging
7 June 2018, Telegraph.co.uk
Sixers take offense to Goran Dragic’s layup in final seconds of Game 2. Dragic: ‘I don’t care’
18 April 2018, Palm Beach Post (blog)
‘Real Puzzles’ Will Offer 100 ‘Monument Valley’ Style Perspective Puzzles on May 30th
3 May 2018, Touch Arcade
The Pirate Bay Alternatives- 10 Best Torrent Sites like TPB (2018)
21 March 2018, Techworm
Defamation via Google search case to be discussed by High Court
20 March 2018, ABC Online
provided by Google News
Программист Python (Django)
НТЦ Вулкан, Москва
PHP разработчик
Мамси, Москва
Linux администратор
Group-IB, Москва
Data Scientist (Cybersecurity)
Group-IB, Москва
Development Team Lead
Kaspersky Lab, Москва
Senior Software Engineer
Under Armour, Austin, TX
Database Administrator
Workbridge Associates, Arlington, VA
jobs by 
Задача поиска по тексту предполагает работу со сложными индексами и большими объемами данных. Поэтому для ее решения образовалась целая группа отдельных инструментов.
Многие базы данных имеют встроенную возможность поиска по тексту, однако всегда это очень ограниченная реализация. В большинстве случаев следует использовать более подходящие технологии.
Содержание
- Устройство полнотекстового индекса
- Sphinx vs ElasticSearch: что выбрать?
- 1. Sphinx
- 2. Solr
- 3. Elastic
- Самое важное
- Сравнение Sphinx и ElasticSearch
- Key features
- Documentation
- Sphinx или ElasticSearch?
- Download
- Bugs
- Sample sites
- System Properties Comparison Elasticsearch vs. Sphinx
- Быстрый поиск на сайте, используя ElasticSearch или Sphinx
- Самое главное
Устройство полнотекстового индекса
Все технологии полнотекстового поиска работают по одному принципу.
Sphinx vs ElasticSearch: что выбрать?
На основе текстовых данных строится индекс, который способен очень быстро искать соответствия по ключевым словам.
Обычно сервис поиска состоит из двух компонент. Поисковик и индексатор. Индексатор получает текст на вход, делает обработку текста (вырезание окончаний, незначимых слов и т.п.) и сохраняет все в индексе. Устройство такого индекса позволяет проводить по нему очень быстрый поиск.  Поисковик — интерфейс поиска по индексу — принимает от клиента запрос, обрабатывает фразу и ищет ее в индексе.
Поисковик — интерфейс поиска по индексу — принимает от клиента запрос, обрабатывает фразу и ищет ее в индексе. 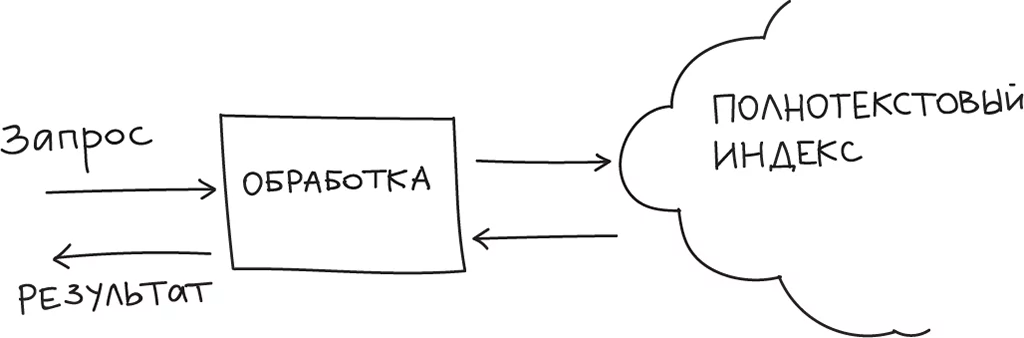
Существует несколько популярных технологий для реализации полнотекстового поиска в приложениях.
1. Sphinx
Супер простое решение, которое подойдет для большинства случаев. По умолчанию поддерживает английский и русский язык. Имеет интерфейс для индексирования таблиц MySQL. Чтобы начать использовать Sphinx достаточно установить его из пакетов, настроить источник данных и запустить индексатор в cron задачу.
Конфигурация делится на source и index для определения источника данных и параметров индекса:
После этого достаточно запустить индексатор в cron, например для переиндексации каждые 5 минут:
В таком режиме максимальная задержка до появления данных в поиске будет составлять 5 минут.
Sphinx поддерживает обычный MySQL протокол для поиска, поэтому чтобы найти в индексе какой-то текст достаточно подключиться к порту 9306 и отправить обычный MySQL запрос:
Например, в PHP:
При больших объемах можно использовать схему Delta индексов для ускорения индексации. Кроме этого, Sphinx поддерживает Real Time индексы, фильтрацию и сортировку результатов поиска и поиск по wildcard условиям.
2. Solr
Solr — не просто поисковый индекс, а еще и хранилище документов. Т.е. в отличие от Sphinx’a, документы сохраняются целиком и их не нужно дублировать в базу данных.
Решение Java-based, поэтому понадобится JVM и сам Solr. Из пакетов можно поставить все вместе:
apt-get install solr-jetty
Либо просто скачать Solr и запустить его:
wget http://apache.cp.if.ua/lucene/solr/5.3.1/solr-5.3.1.tgz tar -xvf solr-5.3.1.tgz cd solr-5.3.1 bin/solr start
После этого сервис станет доступен на порту 8983:
http://127.0.0.1:8983/
Solr работает по текстовому HTTP протоколу. Сразу после установки можно отправлять данные в индекс. Индекс — это что-то вроде таблицы в MySQL, для ее создания нужно выполнить команду:
bin/solr create -c shop
Чтобы добавить документ в индекс, достаточно отправить такой запрос.
curl http://localhost:8983/solr/shop/update -d ‘ [ {"id" : "1", "title_t" : "The Solr And Shit", "author_t" : "Den Golotyuk" } ]’
Теперь можно сделать выборку документа по ID:
curl http://localhost:8983/solr/shop/get?id=1
Чтобы стала доступной возможность поиска по индексу, необходимо запустить перестроение индекса:
curl http://localhost:8983/solr/shop/update?commit=true
После этого можно искать по тексту:
curl http://localhost:8983/solr/demo/query -d ‘q=author_t:Den’
Получим что-то типа этого:
Solr поддерживает масштабирование в кластер, поэтому это решение подойдет для очень больших объемов данных и нагрузок. Кроме обычного текстового поиска этот поисковик может находить неточные соответствия (например, при поиске слов с ошибками).
3. Elastic
Elasticsearch — целая инфраструктура для работы с данными, в том числе полнотекстовым поиском. Построен на основе Apache Lucene.
Установка из кастомного репозитория Debian:
wget -qO — https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add — echo "deb http://packages.elastic.co/elasticsearch/1.4/debian stable main" | sudo tee -a /etc/apt/sources.list apt-get update && apt-get install elasticsearch update-rc.d elasticsearch defaults 95 10 /etc/init.d/elasticsearch restart
После запуска (может занять несколько секунд) нужно проверить доступность:
curl localhost:9200
Индексы (таблицы) создаются автоматически при индексации, а сам индексатор работает в режиме реального времени. Поэтому для добавления документа в индекс нужно сделать только один вызов:
curl -XPUT "http://localhost:9200/shop/products/1" -d’ { "title": "Elastic", "description": "Better than Solr" }’
Чтобы получить документ по id достаточно сделать такой вызов:
curl -XGET "http://localhost:9200/shop/products/1"
Для поиска документов по тексту:
curl -XPOST "http://localhost:9200/shop/products/_search" -d’ { "query": { "query_string": { "query": "Better" } } }’
Elastic имеет мега продвинутую систему хранения данных и протокол запросов. Поэтому во многих случаях его применяют, как движок для Ad-hoc запросов.
Самое важное
Для поиска по тексту следует использовать указанные инструменты, т.к. обычные базы данных весьма ограничены и неэффективны в этом вопросе. Короткая сводка поможет выбрать подходящее решение:
- Sphinx. Простой, быстрый, легкий, используется в связке с базовый данных, поиск по русскому/английскому тексту, wildcard поиск.
- Solr. Большой, мощный, выступает как хранилище, миллион функций, сделать можно практически все, есть неточный поиск и возможность масштабироваться из коробке.
- Elastic. Не только поиск и хранилище, а и другие инструменты (визуализация, сборщик логов, система шифрования и т.п.). Умеет масштабироваться и позволяет выполнять выборки очень сложной формы, что делает это хорошим вариантов для аналитической платформы.
Программы индексирования и пауки поисковых движков – это исключительно мощные программы. Они просматривают сотни миллиардов web-страниц, анализируют контент всех страниц, а также способ связи этих страниц друг с другом. Затем они организуют всю полученную информацию в базы данных, которые в ответ на запрос пользователя могут выдать (в течение нескольких десятых секунды) высоко организованный набор результатов.
Это потрясающее достижение, но оно имеет свои ограничения. Программное обеспечение очень механистично, оно может понять только часть страницы (для большинства web-страниц). Паук поискового движка анализирует HTML-код web-страницы. Если вы хотите понять, как это делается, то сможете увидеть, воспользовавшись вашим браузером для просмотра исходного кода.
Два моментальных снимка экрана на рис. 2.15 показывают, как сделать это в браузере FireFox (левый рисунок) и в браузере Internet Explorer (правый рисунок).

Рис. 2.15.
Сравнение Sphinx и ElasticSearch
Просмотр исходного кода в вашем браузере
При просмотре исходного кода вы видите точный код web-сайта, который web-сервер отправил в ваш браузер. Именно это и видит паук поискового движка (поисковый движок видит также и HTTP-заголовки данной страницы). Паук игнорирует многое из того, что содержится в коде. Например, поисковые движки в основном игнорируют такой код, который показан на рис. 2.16 (поскольку он не имеет отношения к содержимому web-страницы).

Рис. 2.16. Пример исходного кода web-страницы
Паук поискового движка больше всего интересуется той информацией, которая содержится в HTML-тексте страницы. На рис. 2.17 показан пример HTML-текста для web-страницы (использована начальная страница сайта SEOmoz.org).

Рис. 2.17. Пример HTML-текста в исходном коде
Несмотря на то, что на рисунке есть HTML-коды, мы можем ясно видеть в этом коде обычный текст. Это именно тот уникальный контент, который ищет паук.
Кроме того, поисковые движки читают и некоторые другие элементы. Один из этих элементов – заголовок страницы (один из самых главных факторов при ранжировании данной web-страницы). Это текст, который демонстрируется в строке заголовков браузера (синяя полоса над меню браузера).
На рис. 2.18 показан тот код, который видит паук. В качестве примера использован сайт Trip Advisor (http://www.tripadvisor.com).

Рис. 2.18. Метатеги в исходном HTML-коде
Первый красный эллипс на рисунке обозначает тег заголовка страницы. Этот тег часто (но не всегда) используется как заголовок вашей позиции в результатах поискового движка. Исключением из этого правила являются данные вашего сайта, полученные из каталогов Yahoo! или DMOZ. Иногда поисковые движки могут видеть в качестве заголовка вашей страницы то, что было использовано в ваших данных в этих каталогах (а не тег заголовка страницы). Есть также и метатеги, которые позволяют вам блокировать это (такие, как тег noodp (который говорит поисковому движку, что не следует использовать заголовки DMOZ) и тег noydir (который говорит движку Yahoo! что не следует использовать листинг каталогов Yahoo!)).
В любом случае, на рис. 2.19 показано то, что происходит, когда вы ищете stone temple consulting (начальная страница Stone Temple Consulting находится по адресуhttp://www.stonetemple.com). Обратите внимание, что заголовок результатов поиска совпадает с заголовком начальной страницы Stone Temple Consulting.

Рис. 2.19. Результаты поиска, показывающие тег заголовка страницы
В дополнение к заголовкам страниц, поисковые движки читают также и метатег keywords. Это список ключевых слов, которые вы хотите ассоциировать со страницей. Спамеры (люди, которые пытаются манипулировать результатами поисковых движков в нарушение их указаний) много лет назад разрушили ценность этого тега для оптимизации (и поэтому его ценность нынче минимальна). Google вовсе не использует этот тег для ранжирования, но Yahoo! и Bing вроде бы уделяют ему внимание (вы можете прочитать об этом более подробно по адресу http://searchengineland.com/meta-keywords-tag-101-how-to-legally-hide-words-on-your-pages-for-search-engines-12099).
Тратить много времени на метатег keywords не рекомендуется (поскольку в плане оптимизации это вам ничего не даст).
Второй красный эллипс на рис. 2.18 обозначает пример метатега keywords.
Поисковые движки читают также и метатег description (третий красный эллипс на рис. 2.18). Однако метатег description не оказывает никакого влияния на рейтинги поисковых движков (http://searchengineland.com/21-essential-seo-tips-techniques-11580).
Тем не менее метатег description играет ключевую роль, поскольку поисковые движки часто используют его как описание вашей страницы в результатах поиска. Поэтому хорошо написанный метатег description может иметь существенное влияние на количество кликов по вашему элементу в результатах поиска. Потраченное на этот тег время даст ценные результаты. На рис. 2.20 показан поиск по trip advisor, который является примером использования метатега description в качестве описания в результатах поиска.
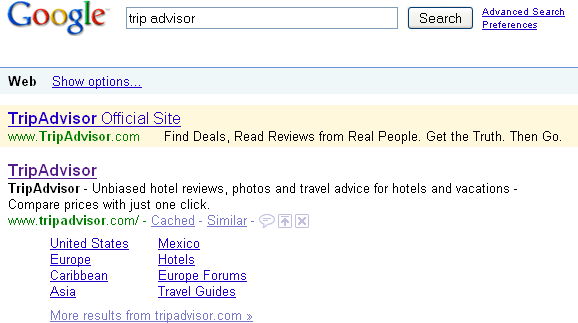
Рис. 2.20. Метатег description в результатах поиска
⇐ Предыдущая17181920212223242526Следующая ⇒
Дата публикования: 2014-11-18; Прочитано: 105 | Нарушение авторского права страницы

DataparkSearch Engine is a full-featured open sources web-based search engine released under the GNU General Public License and designed to organize search within a website, group of websites, intranet or local system.
Key features
- Support for http, https, ftp, nntp and news URL schemes.
- htdb virtual URL scheme for indexing SQL databases.
- Indexes text/html, text/xml, text/plain, audio/mpeg (mp3) and image/gif mime types natively.
- External parsers support for other document types, including Microsoft Word, Excel, RTF, PowerPoint, Adobe Acrobat PDF and Flash.
- Can index multilingual sites using content negotiation.
- Can search all of the word forms using ispell affixes and dictionaries.
- Synonym, acronym and abbreviation query expansion based on editable dictionaries, specified by language and charset.
- Stop-words, synonyms and acronyms lists.
- Options to query with all words, all words near to each others, any words, or Boolean queries. A subset of VQL (Verity Query Language) is supported.
- Popularity Rank based on a neural network model.
- Results can be sorted by relevancy (using vector calculation), popularity rank as "Goo" (adding weight for incoming links), and "Neo" (neural network model), last modified time, and by "importance" (a combination of relevancy and popularity rank).
- Supports wide range of character sets support with automated character set and language detection.
- Offers an accent insensitive search option.
- Provides phrase segmenting (tokenizing) for Chinese, Japanese, Korean and Thai.
- Includes an indexer and a web CGI front-end, as well as a search module for Apache web server (mod_dpsearch).
- Handles Internationalized Domain Names (IDN).
- Summary Extraction Algorithm automatically sums up each document in several sentences.
- Uses If-Modified-Since for efficient transfer of only changed files.
- Can tweak URLs with session IDs and other weird formats, including some JavaScript link decoding.
- Can perform parallel and multi-threaded indexing for faster updating.
- Flexible update scheduling, including options for checking some sections of a site more frequently.
- Handles basic authentication (user name and password) and cookies.
- Stores a compressed text version of the documents for extracting and viewing.
- Can specify a default character set and language for a server or subdirectory, or a list of possible languages.
- Noindex tags: <!—UdmComment—>, <NOINDEX>, <!—noindex—>, Google's special comments <!— google_ad_section_start —>, <!— google_ad_section_start(weight=ignore) —> and <!— google_ad_section_end —> consider as tags to include/exclude.
- Can specify a content body tag.
- Spellchecking for query words with aspell.
- Flexible options and commands to customize search result pages.
- Effective caching gives significant time reduction in search times.
- Query logging stores the query, query parameters and the number of results found.
Documentation
The DataparkSearch documentation is enclosed in the release or snapshot distribution in the doc subdirectory. And it’s also available on-line in English (PDF, bytes) and in Russian.
You can use DataparkSearch group at the Google Groups ( groups.google.com/group/dataparksearch/) to seek an advice on DataparkSearch.
Sphinx или ElasticSearch?
As well you can share your experience using DataparkSearch in this group.
Our old forum is closed for writing but it is still avalable to browse the old records.
DataparkSearch’s: ChangeLog (As a RSS feed); PAD file.
Download
Latest DataparkSearch version released: dpsearch-4.53.tar.bz2, January 2010.
The snapshot of upcoming 4.54 version is updated regularly and available on Google Disk or in Google Code. There you can also download deb and RPM packages built with the latest snapshot.
The source code is available either in SVN repository in Google Code or in git repository on GitHub.
Bugs
You may see all open bug reports or post a new one at Google Code’s home. Or use the similar issue tracking system on GitHub.
Sample sites
Изменить (апрель 2015):
Как многие заметили, мой старый блог теперь не функционирует.
System Properties Comparison Elasticsearch vs. Sphinx
Большинство моих статей были перенесены в блог Elastic и могут быть найдены путем фильтрации моего имени: https://www.elastic.co/blog/author/zachary-tong
Чтобы быть абсолютно честным, лучший источник знаний начинающих теперь Elasticsearch — The Definitive Guide, написанный мной и Клинтоном Гормли.
Он принимает нулевые знания в поисковых системах и объясняет поиск информации первому руководителем в контексте Elasticsearch. Хотя справочные документы касаются поиска точного параметра, который вам нужен, руководство представляет собой повествование, в котором обсуждаются проблемы в поиске и способы их решения.
Лучше всего, книга OSS и бесплатная (если вы не хотите купить бумажную копию, и в этом случае О’Рейли с радостью продаст вам:))
Изменить (август 2013):
Многие из моих статей были перенесены в официальный блог Elasearch , а также новые статьи, которые не были опубликованы на моем личном сайте.
Оригинальное сообщение:
Я также был разочарован изучением ElasticSearch, не имеющим опыта Lucene/Solr. Я медленно документировал то, что я узнал в своем блоге, и до сих пор есть четыре учебника:
Поэтому мне не нужно продолжать редактирование, все будущие учебники в моем блоге можно найти по этой категории.
И это некоторые ссылки, которые я добавил в закладки, потому что они были невероятно полезны так или иначе:
ответ дан Zach 02 авг. '12 в 0:08
источникподелиться
Elasticsearch — поисковая система, основанная на Apache Lucene, которая обеспечивает полнотекстовый поиск и мультиарендность с веб-интерфейсом HTTP и поддержкой без-схемных JSON-документов. 
Среди основных преимуществ системы — сравнительная простота настройки и масштабируемость, большое количество модулей (благодаря API) и возможность весьма гибкого и быстрого поиска (хотя скорость индексации уступает Sphinx).
А еще Elasticsearch весьма легко справляется с поиском неточных соответствий, который работает по немного отличному от wildcard-поиска в Sphinx принципу.
Нечеткие запросы
Fuzzy-запросы используют сходство на основе расстояния Левенштейна для текстовых полей или границу слева-справа для числовых полей и дат.
Для этого используется запрос fuzzy, который генерирует все возможные соответствия, которые находятся в пределах максимального редакционного расстояния (задается параметром ), а затем проверяет словарь терминов для сравнения с существующим индексом.
Создадим простой индекс:
При помощи все того же curl и простого запроса GET можно провести первый поиск:
То есть мы провели fuzzy-поиск «surprize» по нашему индексу. Вывод будет содержать первый и третий документы, так как параметр по умолчанию равен auto:
- редакционное расстояние 0 для строк из 1 или 2 символов;
- редакционное расстояние 1 для строк длиной от 3 до 5 символов;
- редакционное расстояние 2 для строк длиной от 5 символов.
Следующий пример содержит большее количество параметров :
Пройдемся по дополнительным параметрам:
- boost — задает приоритет запроса, то есть можно повысить приоритет точных совпадений, чтобы они занимали первые позиции в поисковой выдаче;
- prefix_length — задает размер префикса, помогает отсеять количество слов при поиске;
- max_expansions — максимальное количество терминов неточного запроса, по умолчанию равно 50.
Учтите, что малое значение и большое значение увеличивают время поиска и нагрузку на сервер.
Запрос match
Неточные совпадения в Elasticsearch также могут использоваться в запросах типа match.
Быстрый поиск на сайте, используя ElasticSearch или Sphinx
К примеру:
Также можно производить неточный поиск по нескольким полям при помощи , а также использовать параметры и .
Самое главное
Fuzzy-запросы помогут расширить результаты поиска. При этом важно учитывать дополнительные параметры, которые увеличивают нагрузку на систему, а также назначать приоритеты, чтобы точные совпадения были выше неточных.
FILED UNDER : IT