admin / 23.01.2018
MongoDB — Википедия
Содержание
Установка и начало работы с MongoDB на Windows
Последнее обновление: 28.03.2018
Для установки MongoDB загрузим один распространяемых пакетов с официального сайта https://www.mongodb.com/download-center#community.
Официальный сайт предоставляет пакеты дистрибутивов для различных платформ: Windows, Linux, MacOS, Solaris. И каждой платформы доступно несколько дистрибутивов. Причем есть два вида серверов — Community и Enterprise. В данном случае надо установить версию Community. Хотя Enterprise-версия обладает несколько большими возможностями, но она доступна только в триальном режиме или по подписке.
На момент написания данного материала последней версией платформы была версия 3.6.3. Использование конкретной версии может несколько отличаться от применения иных версий платформы MongoDB.
Для загрузки и установки пакета выберем нужную операционную систему и подходящий тип пакета:
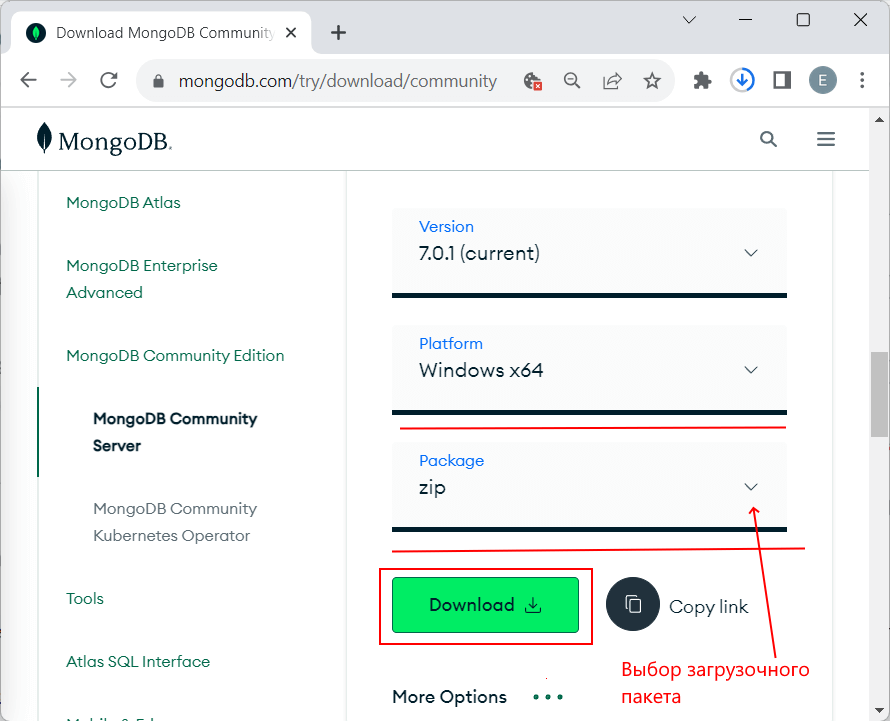
При загрузки дистрибутива для Windows по умолчанию выбран тип Windows Server 2008 R2-bit and later, with SSL support x64. Оставим эту опцию по умолчанию и для загрузки установочного пакета нажмем на кнопку DOWNLOAD (msi).
Для ОС Windows загрузочный пакет поставляется в виде файла установщика с расширением msi.
И после загрузки запустим его:
После принятия лицензионного соглашения нам отобразится окно выбора типа настроек:
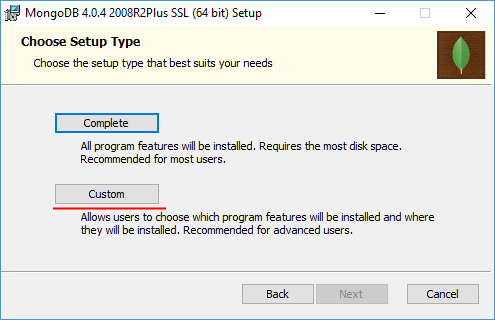
Выберем в нем Custom. По умолчанию все файлы устанавливаются по пути C:\Program Files\MongoDB. И в принципе можно оставить этот каталог по умолчанию. Но в данном случае мы изменим каталог установки. Для этого в начале создадим на диске C новую папку mongodb и затем укажем ее в качестве места установки:
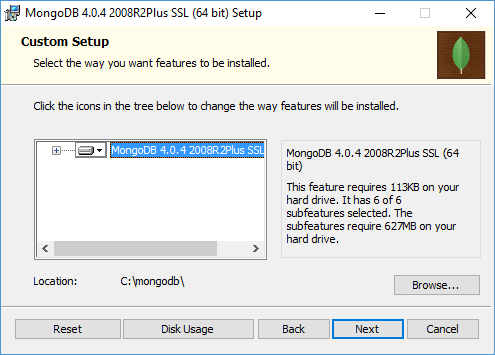
На следующем шаге нам надо отметить, будет ли устанавливаться графический клиент Mongo Compass. Более подробно про него рассказывается в следующей теме. В данном случае не столь важно, будет ли он устанавливаться. Можно снять отметку об установке, а можно и оставить.
И на следующем этапе запустим установку.
Содержимое пакета MongoDB
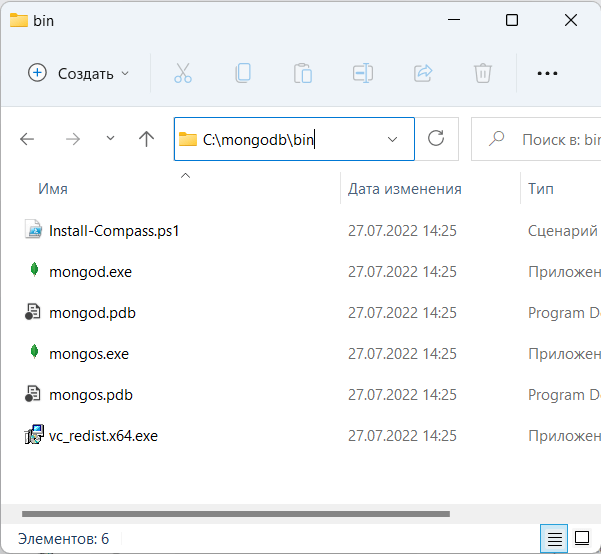
Если после установки мы откроем папку C:\mongodb\bin, то сможем найти там кучу приложений, которые выполняют определенную роль. Вкратце рассмотрим их.
-
bsondump: считывает содержимое BSON-файлов и преобразует их в читабельный формат, например, в JSON
-
mongo: представляет консольный интерфейс для взаимодействия с базами данных, своего рода консольный клиент
-
mongod: сервер баз данных MongoDB. Он обрабатывает запросы, управляет форматом данных и выполняет различные операции в фоновом режиме по управлению базами данных
-
mongodump: утилита создания бэкапа баз данных
-
mongoexport: утилита для экспорта данных в форматы JSON, TSV или CSV
-
mongofiles: утилита, позволяющая управлять файлами в системе GridFS
-
mongoimport: утилита, импорирующая данных в форматах JSON, TSV или CSV в базу данных MongoDB
-
mongooplog: приложение, позволяющее опрашивать удаленные серверы на наличие операций с БД и применять полученные данные к локальному серверу
-
mongoperf: проверяет производительность жесткого диска на предмет операций ввода-вывода
-
mongorestore: позволяет записывать данные из дампа, созданного mongodump, в новую или существующую базу данных
-
mongos: служба маршрутизации MongoDB, которая помогает обрабатывать запросы и определять местоположение данных в кластере MongoDB
-
mongorestat: представляет счетчики операций с бд
-
mongotop: предоставляет способ подсчета времени, затраченного на операции чтения-записи в бд
Создание каталога для БД и запуск MongoDB
После установки надо создать на жестком диске каталог, в котором будут находиться базы данных MongoDB.
В ОС Windows по умолчанию MongoDB хранит базы данных по пути C:\data\db, поэтому, если вы используете Windows, вам надо создать соответствующий каталог. В ОС Linux и MacOS каталогом по умолчанию будет /data/db.
Если же возникла необходимость использовать какой-то другой путь к файлам, то его можно передать при запуске MongoDB во флаге .
Итак, после создания каталога для хранения БД можно запустить сервер MongoDB. Сервер представляет приложение mongod, которое находится в папке bin. Для этого запустим командную строку (в Windows) или консоль в Linux и там введем соответствующие команды. Для ОС Windows это будет выглядеть так:
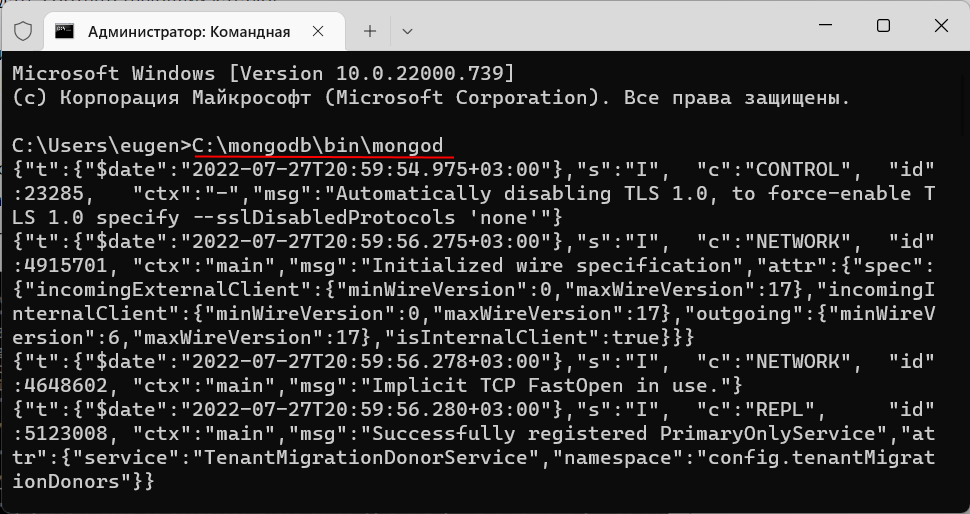
Командная строка отобразит нам ряд служебной информации, например, что сервер запускается на localhost на порту 27017.
Если у вас используется расположение баз данных, отличающееся от настроек по умолчанию, то при запуске можно задать каталог для баз данных следующим образом: . В данном случае предполагается, что базы данных у нас будут находиться в каталоге d:\test\mongodb\data.
И после удачного запуска сервера мы сможем производить операции с бд через оболочку mongo. Эта оболочка представляет файл mongo.exe, который располагается в выше рассмотренной папке установки. Запустим этот файл:
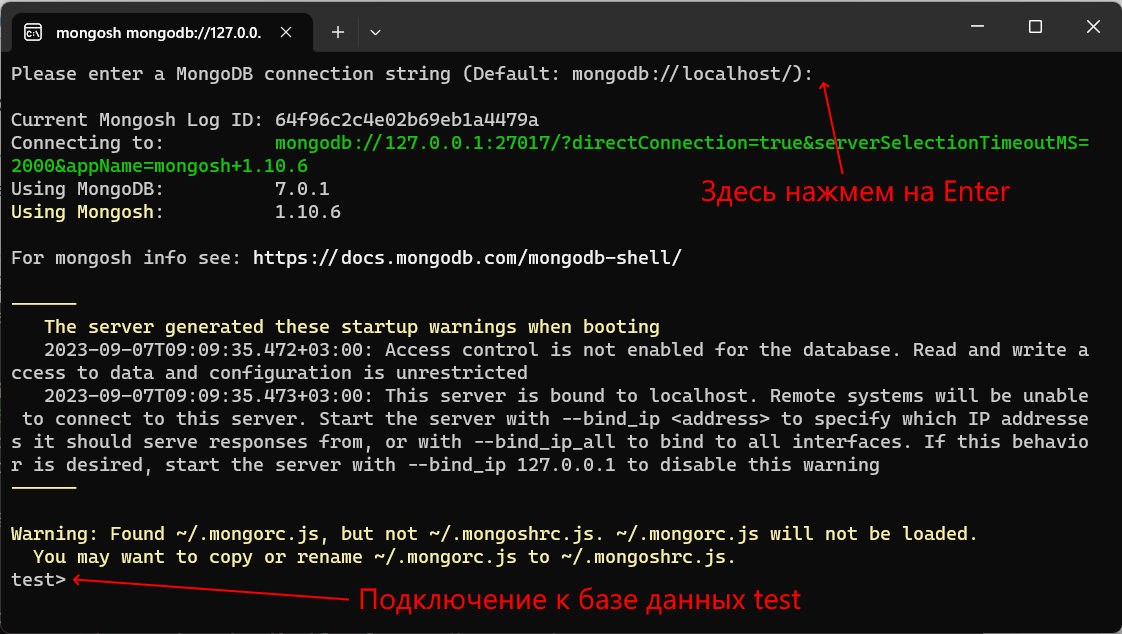
Это консольная оболочка для взаимодействия с сервером, через которую можно управлять данными. Второй строкой эта оболочка говорит о подключении к серверу mongod.
Теперь поизведем какие-либо простейшие действия. Введем в mongo последовательно следующие команды и после каждой команды нажмем на Enter:
use test db.users.save( { name: «Tom» } ) db.users.find()
Первая команда use test устанавливает в качестве используемой базу данных test. Даже если такой бд нет, то она создается автоматически. И далее будет представлять текущую базу данных — то есть базу данных test. После db идет — это коллекция, в которую затем мы добавляем новый объект. Если в SQL нам надо создавать таблицы заранее, то коллекции MongoDB создает самостоятельно при их отсутствии.
С помощью метода db.users.save() в коллекцию users базы данных test добавляется объект . Описание добавляемого объекта определяется в формате, с которым вы возможно знакомы, если имели дело с форматом JSON. То есть в данном случае у объекта определен один ключ «name», которому сопоставляется значение «Tom». То есть мы добавляем пользователя с именем Tom.
Если объект был успешно добавлен, то консоль выведет результа в виде выражения .
А третья команда db.users.find() выводит на экран все объекты из бд test.
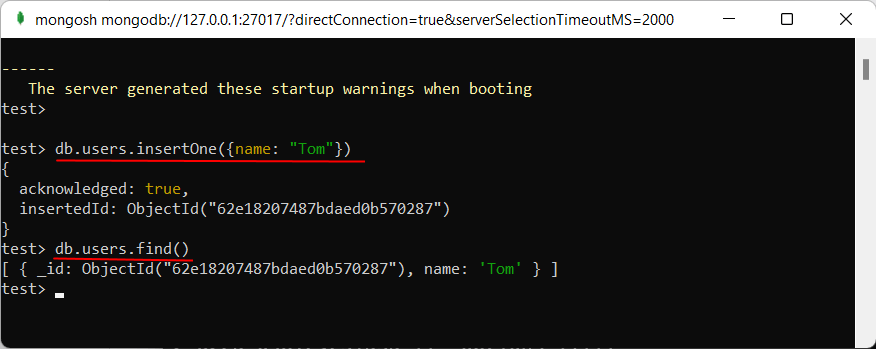
Из вывода вы можете увидеть, что к начальным значениям объекта было добавлено какое-то непонятно поле ObjectId. Как вы помните, MongoDB в качестве уникальных идентификаторов документа использует поле . И в данном случае ObjectId как раз и представляет значение для идентификатора _id.
Установка драйверов MongoDB
Конечно, мы можем работать и через консоль mongo, добавляя и отображая объекты в бд. Но нам также было бы неплохо, если бы mongoDB взаимодействовала бы с нашими приложениями, написанными на PHP, C++, C# и других языках программирования. И для этой цели нам потребуются специальные драйверы.
На офсайте на странице https://docs.mongodb.com/ecosystem/drivers/ можно найти драйвера для таких языков программирования, как PHP, C++, C#, Java, Python, Perl, Ruby, Scala и др.
Далее уже, рассматривая взаимодействие отдельных языков программирования с MongoDB, мы подробнее рассмотрим установку и драйвера и всю необходимую конфигурацию для определенных языков программирования.
НазадСодержаниеВперед
Глава 1 — Основы
Начнём мы с изучения основных механизмов работы с MongoDB. Это самое основное, что понадобится для понимания MongoDB, но также мы коснёмся высокоуровневых вопросов — о том, где применима MongoDB.
Для начала нужно понять шесть основных концепций.
-
MongoDB — концептуально то же самое, что обычная, привычная нам база данных (или в терминологии Oracle — схема). Внутри MongoDB может быть ноль или более баз данных, каждая из которых является контейнером для прочих сущностей.
-
База данных может иметь ноль или более «коллекций». Коллекция настолько похожа на традиционную «таблицу», что можно смело считать их одним и тем же.
-
Коллекции состоят из нуля или более «документов». Опять же, документ можно рассматривать как «строку».
-
Документ состоит из одного или более «полей», которые — как можно догадаться — подобны «колонкам».
-
«Индексы» в MongoDB почти идентичны таковым в реляционных базах данных.
-
«Курсоры» отличаются от предыдущих пяти концепций, но они очень важны (хотя порой их обходят вниманием) и заслуживают отдельного обсуждения. Важно понимать, что когда мы запрашиваем у MongoDB какие-либо данные, то она возвращает курсор, с которыми мы можем делать все что угодно — подсчитывать, пропускать определённое число предшествующих записей — при этом не загружая сами данные.
Подводя итог, MongoDB состоит из «баз данных», которые состоят из «коллекций». «Коллекции» состоят из «документов». Каждый «документ» состоит из «полей». «Коллекции» могут быть проиндексированы, что улучшает производительность выборки и сортировки. И наконец, получение данных из MongoDB сводится к получению «курсора», который отдаёт эти данные по мере надобности.
Вы можете спросить — зачем придумывать новые термины (коллекция вместо таблицы, документ вместо записи и поле вместо колонки)? Не излишнее ли это усложнение? Ответ в том, что эти термины, хоть и близки своим «реляционным» аналогам, но не полностью идентичны им. Основное различие в том, что реляционные базы данных определяют «колонки» на уровне «таблицы», в то время как документ-ориентированные базы данных определяют «поля» на уровне «документа». Это значит, что любой документ внутри коллекции может иметь свой собственный уникальный набор полей. В этом смысле «глупее» чем , тогда как имеет намного больше информации, чем .
Хоть это и важно понять, не волнуйтесь, если не сможете сразу. После нескольких вставок вы увидите, что имеется в виду. В конечном счёте дело в том, что коллекция не содержит информации о структуре содержащихся в ней данных. Информацию о полях содержит каждый отдельный документ. Преимущества и недостатки этого станут понятны из следующей главы.
Приступим. Запустите сервер и консоль , если ещё не запустили. Консоль работает на JavaScript. Есть несколько глобальных команд, например или . Команды, которые вы запускаете применительно к текущей базе данных исполняются у объекта , например или . Команды, которые вы запускаете применительно к конкретной коллекции, исполняются у объекта , например или .
Введите и получите список команд, которые можно выполнить у объекта .
Заметка на полях. Поскольку консоль интерпретирует JavaScript, если вы попытаетесь выполнить метод без скобок, то в ответ получите тело метода, но он не выполнится. Не удивляйтесь, увидев , если случайно сделаете так. Например, если введёте (без скобок), вы увидите внутреннее представление метода .
Сперва для выбора базы данных воспользуемся глобальным методом — введите . Неважно, что база данных пока ещё не существует. В момент создания первой коллекции создастся база данных . Теперь, когда вы внутри базы данных, можно вызывать у неё команды, например . В ответ увидите пустой массив (). Поскольку коллекции бесструктурны (в оригинале «schema-less». Здесь и далее — прим. перев.), мы не обязаны создавать их явно. Мы просто можем вставить документ в новую коллекцию. Чтобы это сделать, используйте команду , передав ей вставляемый документ:
Данная строка выполняет метод («вставить») в коллекцию , передавая ему единственный аргумент. MongoDB у себя внутри использует бинарный сериализированный JSON формат. Снаружи это означает, что мы широко используем JSON, как, например, в случае с нашими параметрами. Если теперь выполнить , мы увидим две коллекции: и . создаётся в каждой базе данных и содержит в себе информацию об индексах этой базы.
Теперь у коллекции можно вызвать метод , который вернёт список документов:
Заметьте, что кроме данных, которые мы задавали, появилось дополнительное поле . Каждый документ должен иметь уникальное поле . Можете генерировать его сами или позволить MongoDB самой сгенерировать для вас ObjectId. В большинстве случаев вы скорее всего возложите эту задачу на MongoDB. По умолчанию — индексируемое поле, вследствие чего и создается коллекция .
Давайте взглянем на :
Вы увидите имя индекса, базы данных и коллекции, для которой индекс был создан, а также полей, которые включены в него.
Вернёмся к обсуждению бесструктурных коллекций. Давайте вставим кардинально отличный от предыдущего документ в , вот такой:
И снова воспользуемся для просмотра списка документов. Теперь, узнав чуть больше, мы можем обсудить это интересное поведение MongoDB, но, надеюсь, вы уже начинаете понимать, почему традиционная терминология здесь не совсем применима.
Осваиваем селекторы
В дополнение к изученным ранее шести концепциям, есть ещё один немаловажный практический аспект MongoDB, который следует освоить, прежде чем переходить к более сложным темам: это — селекторы запросов. Селектор запросов MongoDB аналогичен предложению SQL-запроса. Как таковой он используется для поиска, подсчёта, обновления и удаления документов из коллекций. Селектор — это JSON-объект, в простейшем случае это может быть даже , что означает выборку всех документов (аналогичным образом работает ). Если нам нужно выбрать всех единорогов (англ. «unicorns») женского рода, можно воспользоваться селектором .
Прежде, чем мы глубоко погрузимся в селекторы, давайте сначала создадим немного данных, с которыми будем экспериментировать.
Сперва давайте удалим всё, что до этого вставляли в коллекцию с помощью команды: (поскольку мы не передали селектора, произойдёт удаление всех документов).
Теперь давайте произведём следующие вставки, чтобы получить данные для дальнейших экспериментов (можете скопировать и вставить это в консоль):
Теперь, когда данные созданы, можно приступать к освоению селекторов. используется для поиска всех документов, у которых равно . работает как логическое . Специальные операторы , , , и используются для выражения операций «меньше», «меньше или равно», «больше», «больше или равно», и «не равно». Например, чтобы получить всех самцов единорога, весящих более 700 фунтов, мы можем написать:
Оператор используется для проверки наличия или отсутствия поля, например:
Вернёт единственный документ. Если нужно ИЛИ вместо И, мы можем использовать оператор и присвоить ему массив значений, например:
Вышеуказанный запрос вернёт всех самок единорогов, которые или любят яблоки, или любят апельсины, или весят менее 500 фунтов.
В нашем последнем примере произошло кое-что интересное. Вы заметили — поле это массив. MongoDB поддерживает массивы как объекты первого класса. Это потрясающе удобная возможность. Начав это использовать, вы удивитесь, как вы раньше жили без этого. Самое интересное это та простота, с которой делается выборка по значению массива: вернёт нам все документы, у которых является одним из значений поля .
Это ещё не все операторы. Самый гибкий оператор — , позволяющий нам передавать JavaScript для его выполнения на сервере. Это описано в разделе Сложные запросы на сайте MongoDB. Мы изучили основы, которые нам нужны для начала работы. Это также то, что вы будете использовать большую часть времени.
Мы видели, как эти селекторы могут быть использованы с командой . Они также могут быть использованы с командой , которую мы кратко рассмотрели, командой , на которую мы пока не взглянули, но которую вы скорее всего изучите, и командой , с которой в дальнейшем мы проведём большую часть времени.
, сгенерированный MongoDB для поля , подставляется в селектор следующим образом:
В этой главе
Мы пока ещё не рассматривали команду или более интересные вещи, которые можно сделать с помощью . Однако мы подняли MongoDB, кратко изучили команды и (изучив практически всё, что о них можно изучить) . Мы также начали исследовать и узнали что такое селекторы MongoDB. Это неплохо для начала, и основы для дальнейшего изучения заложены.
Верите или нет, но вы уже изучили практически всё, что нужно знать о MongoDB — настолько она проста и легка в изучении. Я настоятельно рекомендую вам поэкспериментировать с вашими данными, прежде, чем можно будет двигаться дальше. Вставьте несколько новых документов — возможно в новые коллекции — и поэкспериментируйте с селекторами. Используйте , и . После нескольких ваших собственных попыток вещи, казавшиеся непонятными, станут на свои места.
Работа с базой данных
Устройство базы данных. Документы
Последнее обновление: 25.03.2018
Всю модель устройства базы данных в MongoDB можно представить следующим образом:
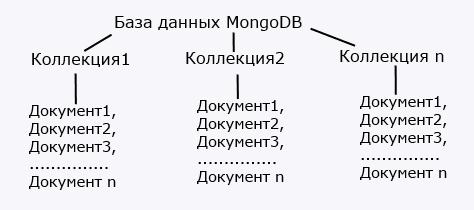
Если в реляционных бд содержимое составляют таблицы, то в mongodb база данных состоит из коллекций.
Каждая коллекция имеет свое уникальное имя — произвольный идентификатор, состоящий из не более чем 128 различных алфавитно-цифровых символов и знака подчеркивания.
В отличие от реляционных баз данных MongoDB не использует табличное устройство с четко заданным количеством столбцов и типов данных. MongoDB является документо-ориентированной системой, в которой центральным понятием является документ.
Документ можно представить как объект, хранящий некоторую информацию. В некотором смысле он подобен строкам в реляционных субд, где строки хранят информацию об отдельном элементе. Например, типичный документ:
{ «name»: «Bill», «surname»: «Gates», «age»: «48», «company»: { «name» : «microsoft», «year» : «1974», «price» : «300000» } }
Документ представляет набор пар ключ-значение.
Rencontres Du Film Court Antananarivo
Например, в выражении name представляет ключ, а Bill — значение.
Ключи представляют строки. Значения же могут различаться по типу данных. В данном случае у нас почти все значения также представляют строковый тип, и лишь один ключ (company) ссылается на отдельный объект. Всего имеется следующие типы значений:
- String: строковый тип данных, как в приведенном выше примере (для строк используется кодировка UTF-8)
- Array (массив): тип данных для хранения массивов элементов
- Binary data (двоичные данные): тип для хранения данных в бинарном формате
- Boolean: булевый тип данных, хранящий логические значения или , например,
- Date: хранит дату в формате времени Unix
- Double: числовой тип данных для хранения чисел с плавающей точкой
- Integer: используется для хранения целочисленных значений, например,
- JavaScript: тип данных для хранения кода javascript
- Min key/Max key: используются для сравнения значений с наименьшим/наибольшим элементов BSON
- Null: тип данных для хранения значения
- Object: строковый тип данных, как в приведенном выше примере
- ObjectID: тип данных для хранения id документа
- Regular expression: применяется для хранения регулярных выражений
- Symbol: тип данных, идентичный строковому. Используется преимущественно для тех языков, в которых есть специальные символы.
- Timestamp: применяется для хранения времени
В отличие от строк документы могут содержать разнородную информацию. Так, рядом с документом, описанным выше, в одной коллекции может находиться другой объект, например:
{ «name»: «Tom», «birthday»: «1985.06.28», «place» : «Vashington», «languages» :[ «english», «german», «spanish» ] }
Казалось бы разные объекты за исключением отдельных свойств, но все они могут находиться в одной коллекции.
Еще пара важных замечаний: в MongoDB запросы обладают регистрозависимостью и строгой типизацией. То есть следующие два документа не будут идентичны:
{«age» : «28»} {«age» : 28}
Если в первом случае для ключа age определена в качестве значения строка, то во втором случае значением является число.
Идентификатор документа
Для каждого документа в MongoDB определен уникальный идентификатор, который называется . При добавлении документа в коллекцию данный идентификатор создается автоматически. Однако разработчик может сам явным образом задать идентификатор, а не полагаться на автоматически генерируемые, указав соответствующий ключ и его значение в документе.
Данное поле должно иметь уникальное значение в рамках коллекции. И если мы попробуем добавить в коллекцию два документа с одинаковым идентификатором, то добавится только один из них, а при добавлении второго мы получим ошибку.
Если идентификатор не задан явно, то MongoDB создает специальное бинарное значение размером 12 байт. Это значение состоит из нескольких сегментов: значение типа размером 4 байта, идентификатор машины из 3 байт, идентификатор процесса из 2 байт и счетчик из 3 байт. Таким образом, первые 9 байт гарантируют уникальность среди других машин, на которых могут быть реплики базы данных. А следующие 3 байта гарантируют уникальность в течение одной секунды для одного процесса. Такая модель построения идентификатора гарантирует с высокой долей вероятности, что он будет иметь уникальное значение, ведь она позволяет создавать до 16 777 216 уникальных объектов ObjectId в секунду для одного процесса.
НазадСодержаниеВперед
.
FILED UNDER : IT