admin / 23.04.2018
Анализ базы данных
Содержание
- Особенность информации, упорядоченной в виде набора элементов и записей одинаковой структуры. Характеристика системы управления базами данных. Использование совокупности языковых и программных средств для создания и ведения сообщений пользователями.
- 2. Анализ информации базы данных
- Область временного хранения данных (Staging Area)
- Детальные данные (System of records)
- Агрегаты (Summary area)
- Витрины данных (Data Marts)
- Анализ качества баз данных
- Интерфейсы обмена данными (Data Exchange Interface)
- Метаданные (Metadata)
- Анализ продуктов. Анализ баз данных
- Концепция хранилища данных
- Исследование Базы данных
- Анализ понятия базы данных
Особенность информации, упорядоченной в виде набора элементов и записей одинаковой структуры. Характеристика системы управления базами данных. Использование совокупности языковых и программных средств для создания и ведения сообщений пользователями.
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Размещено на http://www.allbest.ru/
1. Базы данных. Общие понятия
Базы данных (БД) — это организованный набор фактов в определенной предметной области. БД — это информация, упорядоченная в виде набора элементов, записей одинаковой структуры. Для обработки записей используются специальные программы, позволяющие их упорядочить, делать выборки по указанному правилу. Базы данных относятся к компьютерной технологии хранения, поиска и сортировки информации.
БД — это совокупность взаимосвязанных данных при предельно малой избыточности, допускающей их оптимальное использование в определённых областях человеческой деятельности. БД, в зависимости от способа представления данных и отношений между ними, могут иметь реляционную (таблицы связаны между собой), сетевую или иерархическую структуры. На эффективность БД с той или иной структурой влияют условия её применения. Данные в БД организованы, как правило, в виде таблиц. Табличный способ отображения информации широко используется в документах и отчётах, поскольку он удобен и позволяет наглядно представлять различного рода данные.
Пример простейшей базы данных в виде таблицы:
В БД может храниться миллионы записей. В любое время можно найти запись, которая необходима в данный момент. Результатом поиска информации в приведенной БД могут быть названия, суммы, количество, даты. В базах данных можно проводить сортировку информации и вывод её на печать, удаление старой и вставка новой информации, просматривать БД целиком или по частям. С числами в таблицах можно проводить обычные математические операции. Фамилии людей и названия предметов можно упорядочить по алфавиту.
Программное обеспечение для управления и поддержки работоспособности БД называют системой управления базами данных (СУБД). СУБД осуществляют ввод, проверку, систематизацию, поиск и обработку данных, распечатку их в виде отчётов.
Среди множества СУБД наиболее часто используются пакеты программ dBASE разных версий, FoxBase +, FoxPro, Fox Soft Ware, Clipper, совместимые с dBASE по системе команд и файлам.
Например, БД, созданная в одной СУБД, может использоваться в другой совместимой с ней СУБД, имеющей формат файлов dBASE (*.dbf). Однако есть иные СУБД, например PARADOX и RBase, несовместимые с dBASE. Кроме СУБД для DOS, существуют СУБД, работающие в среде Windows, например Access, MS Works и др.
В основе БД лежит представление данных в виде таблиц. Основными понятиями в СУБД являются поля и записи. В полях содержатся данные. Поле характеризуется длиной. Совокупность всех полей в строке называется записью.
Структуру простейшей базы данных можно рассматривать как прямоугольную таблицу, состоящую из вертикальных столбцов и горизонтальных строк. Вертикальные столбцы принято называть полями, а горизонтальные строки — записями. Единицей хранимой информации является горизонтальная строка-запись, которая хранит информацию, например, об одном сотруднике фирмы. Каждая запись представляет собой совокупность полей.
1.1 Типы данных
В СУБД можно обрабатывать следующие типы данных:
Символьный (Character).
Числовой (Numeric).
Дата календарная (Date).
Логический (Logical).
Данные символьного типа — это любая последовательность символов длиной не более 254.
Числовые данные делятся на 2 вида: целые и вещественные. Длина числового поля должна быть достаточной, чтобы поместились знак числа, целая часть, точка (десятичная) и дробная часть.
Значения календарной даты по умолчанию отображаются в Американском формате ММ/ЧЧ/ГГ (ММ-месяц, ЧЧ-число, ГГ-год). Длина этого поля установлена автоматически и равна 8.
Данные логического типа имеют значения ДА (YES) и НЕТ (NO).
В математической логике они называются Истина (True) и Ложь (False). В логических полях БД используются только первые буквы латинских слов Y,T,N,F. Длина логического поля равна 1.
В поле примечаний отмечается признак, который указывает, что к записи прилагается дополнительный фрагмент текста.
1.2 Структура базы данных
Структуру простейшей базы данных можно рассматривать как прямоугольную таблицу, состоящую из вертикальных столбцов и горизонтальных строк. Вертикальные столбцы принято называть полями, а горизонтальные строки — записями. Единицей хранимой информации является горизонтальная строка-запись, которая хранит информацию, например, об одном ученике в классе в журнале. Каждая запись представляет собой совокупность полей.
Каждое поле БД характеризуется рядом параметров.
имя поля
тип поля
длина поля
количество десятичных знаков
СУБД поддерживает пять типов полей:
СИМВОЛЬНЫЙ — поля этого типа предназначены для хранения в них информации, которая рассматривается как строка символов и может состоять из букв, цифр, знаков препинания и т.п.
ЧИСЛОВОЙ — поля этого типа предназначены только для хранения чисел.
ДАТА — поля этого типа предназначены для хранения каких-либо дат в фиксированном формате: число, месяц, год.
ЛОГИЧЕСКИЙ — поля этого типа предназначены для хранения альтернативных значений вида «ДА» — «НЕТ» или «ПРАВДА» — «ЛОЖЬ». При этом значению «ДА» соответствует нахождение в поле символа «Т», а значение «НЕТ» — символа «F».
ПРИМЕЧАНИЕ (Memo) — поля этого типа используются для хранения фрагментов текста (примечаний).
Длина поля — это ширина вертикального столбца таблицы в символах.
Длина полей СИМВОЛЬНОГО типа представляют собой количество символов, которое Вы хотите уместить в поле.
Длина поля ЧИСЛОВОГО типа равна количеству десятичных разрядов числа, умещающегося в поле, включая знак числа, десятичную точку, целую и дробную часть. Например, если Вы описываете значение «-546.78», то длина равна 7.
Длина ЛОГИЧЕСКОГО поля всегда равна 1, так как его значение «T» или «F».
Количество десятичных знаков — это количество разрядов после десятичной точки. Данная характеристика имеет значение только для полей числового типа. Для всех остальных она равна нулю. Количество десятичных знаков не должно превосходить величины, на 2 меньшей, чем длина соответствующего числового поля. Это автоматически контролируется системой. информация база данные программный
Чтобы описать структуру базы данных необходимо последовательно от поля к полю задать все вышеописанные их характеристики. Вы как бы разлиновываете таблицу, определяете ширину граф и их заголовки. При анализе возможной структуры базы Вам необходимо серьезно отнестись к вопросу распределения информации по полям и определения типов этих полей.
2. Понятие СУБД
В современной технологии баз данных предполагается, что создание базы данных, её поддержка и обеспечение доступа пользователей к ней осуществляются централизованно с помощью специального программного инструментария — системы управления базами данных (СУБД).
Система управления базами данных (СУБД) — это совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
Современная СУБД содержит в своем составе программные средства создания баз данных, средства работы с данными и сервисные средства. С помощью создания БД проектировщик, используя язык описания данных (ЯОД), переводит логическую модель БД в физическую структуру, а на языке манипуляции данными (ЯМД) разрабатывает программы, реализующие основные операции с данными (в реляционных БД — это реляционные операции). При проектировании привлекаются визуальные средства, т. е. объекты, и программа-отладчик, с помощью которой соединяются и тестируются отдельные блоки разработанной программы управления конкретной БД.
Средства работы с данными предназначены для пользователя БД. Они позволяют установить удобный (как правило, графический многооконный) интерфейс с пользователем, создать необходимую функциональную конфигурацию экранного представления выводимой и вводимой информации (цвет, размер и количество окон, пиктограммы пользователя и т. д), производить операции с данными БД, манипулируя текстовыми и графическими экранными объектами.
Сервисные средства позволяют при проектировании использовании БД привлечь к работе с БД другие системы. Например, воспользоваться данными из табличного процессора Excel или обратиться к сетевому серверу.
Размещено на http://www.allbest.ru/
Рис.1 Состав СУБД.
2.1 Классификация СУБД
Классифицировать СУБД можно, используя различные признаки классификации. По степени универсальности различают СУБД общего и специального назначения. СУБД общего назначения не ориентированы на какую-либо конкретную предметную область или на информационные потребности конкретной группы пользователей. Развитые функциональные возможности таких СУБД обеспечивают безболезненную эволюцию построенных на их основе автоматизированных информационных систем в рамках их жизненного цикла.
Однако в некоторых случаях доступные СУБД общего назначения не позволяют добиться требуемой производительности и/или удовлетворить заданные ограничения по объёму памяти, предоставляемой для хранения БД. Тогда приходится разрабатывать специализированную СУБД для данного конкретного применения. Примером специализированной СУБД может быть система IMBASE, используемая для автоматизации проектных и конструкторских разработок.
Важнейшим классификационным признаком СУБД является тип модели данных, поддерживаемый СУБД. По этому признаку СУБД делятся на:
· Иерархические. Первой иерархической СУБД была система IMS (Information Management System) компании IBM,коммерческое распространение которой началось в 1968 г.;
· Сетевые. Первой сетевой СУБД считается система IDS (Integrated Data Store), разработанная компанией General Electric немножко позже системы IMS;
· Реляционные. Первые коммерческие реляционные СУБД от компании IBM, Oracle Corporation, Relation Technology Inc. и других поставщиков появились в начале 80-х годов. Реляционные СУБД просты в использовании, повышают производительность программистов при разработке прикладных программ, хорошо приспособлены для работы в архитектуре клиент/сервер, позволяют параллельную обработку БД, хорошо приспособлены к графическим интерфейсам. Реляционные СУБД продолжают совершенствоваться, предоставляя пользователю возможность решать всё более сложные задачи;
· Объектно-реляционные (постреляционные). Объектно-реляционные СУБД продолжают использовать стандартный язык запросов для реляционных БД — SQL, но с объектными расширениями;
· Объектно-ориентированные. В основе объектно-ориентированных СУБД лежит объектно-ориентированная модель обработки данных.
· Многомерные, в основе которых лежит многомерная модель данных.
На самом общем уровне все СУБД можно разделить на:
· Профессиональные (промышленные), которые представляют собой программную основу для разработки автоматизированных систем управления крупными экономическими объектами. На их базе создаются комплексы управления и обработки информации крупных предприятий, банков или даже целых отраслей. В настоящее время характерными представителями профессиональных СУБД являются такие программные продукты: Oracle, DB2, Sybase, Informix, Inqres, Progress.
· Персональные (настольные). Это программное обеспечение, ориентированное на решение задач локального пользователя или компактной группы пользователей и предназначенная для использования на персональном компьютере, это объясняет их второе название — настольные. К ним относятся DBASE, Fox Base, Fox Pro, Clipper, Paradox, Access.
В настоящее время среди СУБД выделяют СУБД (условно говоря) промежуточные между профессиональными и персональными. SQL Windows/SQL Base, Interbase, Microsoft SQL Server.
Размещено на Allbest.ru
…
Подобные документы
-
Структура базы данных. Свойства полей
Изучение понятия баз данных — набора специальным образом организованных, хранящихся вместе данных, относящихся к определенному роду или кругу деятельности. СУБД – комплекс программных и языковых средств для создания, редактирования и ведения баз данных.
презентация [4,3 M], добавлен 21.02.2011
-
Базы данных и системы управления базами данных
Устройства внешней памяти. Система управления базами данных. Создание, ведение и совместное использование баз данных многими пользователями. Понятие системы программирования. Страницы доступа к данным. Макросы и модули. Монопольный режим работы.
реферат [27,5 K], добавлен 10.01.2011
-
Система управления базами данных
Рассмотрение совокупности программ и языковых средств (специальных языков описания и манипулирования данными), предназначенных для создания, ведения и использования баз данных. Определение языков общения. Исследование принципов построения банка данных.
реферат [56,9 K], добавлен 07.08.2017
-
Разработка базы данных «Обувная мастерская»
Система управления базами данных как совокупность программных и языковых средств, предназначенных для создания и обработки данных. Анализ деятельности обувной мастерской. Особенности разработки функциональной диаграммы и тестирования программного модуля.
дипломная работа [2,9 M], добавлен 04.11.2012
-
Система управления базами данных Access
Алгоритмы обработки массивов данных. Система управления базами данных. Реляционная модель данных. Представление информации в виде таблицы. Система управления базами данных реляционного типа. Графический многооконный интерфейс.
контрольная работа [2,8 M], добавлен 07.01.2007
-
Информационная система «Журнал инспектора»
Анализ предметной области. Проектирование и разработка базы данных и интерфейса в виде набора Web-страниц для отображения, создания, удаления и редактирования записей базы данных. Аппаратное и программное обеспечение системы. Алгоритм работы программы.
курсовая работа [3,0 M], добавлен 12.01.2016
-
Создание базы данных поликлиники
Основные виды баз данных. Система управления базами данных. Анализ деятельности и информации, обрабатываемой в поликлинике. Состав таблиц в базе данных и их взаимосвязи. Методика наполнения базы данных информацией. Алгоритм создания базы данных.
курсовая работа [3,1 M], добавлен 17.12.2014
-
Работа с базами данных в MS Excel
Создание базы данных. Поиск, изменение и удаление записей. Обработка и обмен данными. Проектирование базы данных. Определение формул для вычисляемой части базы. Редактирование полей и записей. Формы представления информации, содержащейся в базе данных.
курсовая работа [67,0 K], добавлен 23.02.2009
-
Практическая обработка набора данных, представленного в виде файла
Структура программного комплекса. Ввод информации из заданного файла. Создание набора данных. Добавление элементов в конец набора данных. Просмотр всех элементов набора данных. Копирование информации из НД в заданный файл. Сортировка массива по номерам.
курсовая работа [630,5 K], добавлен 01.06.2014
-
Разработка базы данных для создания учетных записей на файловом сервере
Особенности создания учетных записей на файловом сервере. Разработка функциональной модели базы данных. Отчет по дугам модели. Сущность, атрибуты и связи информационной модели. Разработка базы данных в системе управления базами данных MS Access.
контрольная работа [2,3 M], добавлен 23.01.2014

Реализовано в версии 8.3.10.2168.
Мы продолжаем развивать механизм выгрузки / загрузки конфигурации в файлы XML. Некоторое время назад мы уже рассказывали о том, что реализовали частичную загрузку конфигурации. Теперь мы реализовали обратную операцию – частичную (инкрементальную) выгрузку конфигурации.
В результате этих двух изменений групповая разработка больших конфигураций должна стать легче и быстрее.
Главное изменение заключается в том, что при выгрузке конфигурации в файлы XML теперь формируется (или обновляется) специальный служебный файл ConfigDumpInfo.xml, который называется файлом версий. Он хранится в каталоге выгрузки вместе с остальными файлами XML, и содержит информацию о формате выгрузки, о версии выгрузки, и о версиях всех объектов, которые были выгружены.
Таким образом теперь, проанализировав этот файл, платформа точно знает, какие версии каких объектов содержатся в выгрузке. На основании этой информации она выгружает только те объекты, которые были изменены по отношению к уже выгруженным.
На практике это выглядит следующим образом.
Если выгрузка выполняется в первый раз (или если в каталоге выгрузки отсутствует файл версий), то выполняется полная выгрузка, генерируется файл версий.
Если в каталоге выгрузки уже есть файл версий, то выгружаются только изменения конфигурации по отношению к файлу версий, файл версий обновляется.
Интересным моментом является то, что частичная выгрузка конфигурации в файлы XML предоставляет вам сразу несколько новых возможностей, которые отсутствовали ранее, или были сложны в реализации.
Оптимизация работы 1C:Enterprise Development Tools
Эта возможность не требует от вас каких-либо усилий, потому что реализуется на уровне платформы. Конечно же, инкрементальную выгрузку в файлы XML мы, прежде всего, задействуем в новой среде разработки. Это должно ускорить работу с большими конфигурациями, на которые эта среда и рассчитана. Благодаря тому, что теперь есть возможность выгружать только изменённые объекты, должны ускориться операции получения изменений из информационной базы.
Интерактивная выгрузка
Этот сценарий позволяет вам в процессе разработки периодически сохранять конфигурацию в виде файлов XML. Раньше для больших конфигураций этот сценарий был практически неприемлем, потому что каждый раз выгружалась вся конфигурация. А это могло занимать много времени.
Теперь же полная выгрузка конфигурации потребуется вам только в первый раз. Дальше вы модифицируете конфигурацию и в некоторый момент просто вызываете диалог выгрузки, указываете каталог, и нажимаете ОК. В результате будут выгружены только те изменения, которые вы произвели в конфигурации с прошлой выгрузки в XML.
Автоматическое обновление XML выгрузки
Это вариация предыдущего сценария, когда изменения, выполненные вами за день, автоматически сохраняются в XML выгрузке. Тут вам понадобится написать скрипт, который запускается после окончания рабочего дня, и выполняет, например, такую команду:
1cv8.exe config /DumpConfigToFiles C:\xml –update
В результате в каталог выгрузки (C:\xml) будут сохранены только те изменения (-update), которые сделаны с момента предыдущей выгрузки, то есть в течение дня.
update это новый ключ, который позволяет обновить выгрузку, то есть выгрузить только те файлы, версии которых отличается от версий в каталоге выгрузки.
Автоматическая модификация или контроль конфигурации
Существует целый ряд задач, когда выгрузка конфигурации в файлы XML используется для автоматической проверки конфигурации или для выполнения «регламентных» действий, не связанных с прикладной логикой. Это может быть, например, автоматизированная проверка конфигурации на соответствие стандартам разработки, принятым в компании. Или автоматическая модификация ролей для новых объектов.
Общим в этих задачах является то, что конфигурацию предварительно нужно выгрузить в файлы XML. А иногда ещё и загрузить обратно. И тут, конечно, инкрементальная выгрузка конфигурации позволит сэкономить значительное количество времени в цепочке выгрузка – обработка – загрузка.
Контроль изменений в конфигурации
Этот сценарий удобен в том случае, когда над одной конфигурацией работают сразу несколько разработчиков. При этом имеется XML выгрузка, которая является эталонным состоянием конфигурации. Задача состоит в том, чтобы при каждом изменении конфигурации сохранять информацию о том, что изменилось. В этом случае разработчик может выполнить, например, такую команду:
1cv8.exe config /DumpConfigToFiles C:\xml -getChanges C:\diff.txt
В результате будет сформирован файл (C:\diff.txt), содержащий изменения конфигурации (-getChanges) относительно эталонной выгрузки(C:\xml). Если изменений нет, то файл diff.txt будет пустым.
getChanges это новый ключ, который позволяет вывести в указанный далее файл изменения текущей конфигурации относительно той выгрузки, каталог которой указан перед этим ключом.
2. Анализ информации базы данных
Работа с системами контроля версий
Ещё один сценарий групповой разработки предполагает то, что выгрузка конфигурации в виде файлов XML хранится во внешней системе контроля версий, с которой работают все разработчики.
Тогда разработчик, внеся свои изменения в конфигурацию локальной информационной базы, может выполнить следующие шаги:
- Получить обновления (Update) выгрузки конфигурации из системы контроля версий (если они есть);
- Выгрузить измененные объекты из локальной информационной базы, например, такой командой:
1cv8.exe config /DumpConfigToFiles C:\xml -update
- Зафиксировать изменения (Commit) выгрузки конфигурации в системе контроля версий.
После этого другие разработчики смогут обновить (Update) свои копии XML выгрузки конфигурации.
Получение «патча» для конфигурации
И, наконец, последний сценарий использования частичной выгрузки конфигурации в файлы XML позволяет создавать своеобразные «патчи» из XML файлов конфигурации.
Например, есть конфигурация, которая хранится и распространяется в виде XML выгрузки. Известно, что эта конфигурация изменяется мало. В некоторый момент в конфигурации были выявлены ошибки.
Тогда прежде, чем исправлять ошибки, вы фиксируете (сохраняете) XML выгрузку, соответствующую этому состоянию конфигурации, как эталонную. После этого исправляете ошибки, и выгружаете только изменения, относящиеся к исправлению ошибок. Например, такой командой:
1cv8.exe config /DumpConfigToFiles C:\xml_patch -update –configDumpInfoForChanges C:\xml_source\ConfigDumpInfo.xml
Здесь C:\xml_source\ConfigDumpInfo.xml это файл версий эталонной конфигурации, а C:\xml_patch – каталог, в который будут выгружены только те XML файлы, которые исправляют обнаруженные ошибки.
configDumpInfoForChanges это новый ключ, который позволяет указать конкретный файл версий, от которого нужно «отсчитывать» изменения.
Если же вы хотите не только выгрузить файлы, но и получить список измененных объектов, содержащихся в вашем «патче», то нужно выполнить такую команду:
1cv8.exe config /DumpConfigToFiles C:\xml_patch -update –configDumpInfoForChanges C:\xml_source\ConfigDumpInfo.xml -getChanges C:\diff.txt
Тогда информация об изменениях будет записана в файл C:\diff.txt.
Основными компонентами корпоративного хранилища данных являются:
- Модель данных;
- База данных;
- ETL-приложение;
- BI-приложение.
Архитектура области хранения данных базы данных корпоративного хранилища, как правило, состоит из следующих областей:
- область временного хранения данных (Staging Area) – предназначена для временного хранения данных, извлеченных из систем-источников; является промежуточным слоем между операционными системами компании и хранилищем данных;
- область постоянного хранения данных, которая включает:
- детальные данные (System of records) – область хранения детальных данных, приведенных к структуре модели данных корпоративного хранилища, прошедших очистку и обогащение;
- агрегаты (Summary area) – сгруппированные по времени (чаще просуммированные) детальные данные;
- витрины данных (Data Marts) – тематические наборы данных, хранящиеся в виде пригодном для их анализа (например, схема «звезда»); ориентированны на поддержку конкретных бизнес-процессов, приложений, подразделений компании, бизнес-целей;
- интерфейсы обмена данными с другими системами (Data Exchange Interface или Feedback Area) – таблицы БД, в которых храняться подготовленные для передачи в другие информационные системы компании данные из области постоянного хранения данных;
- метаданные (Metadata) – являются важной частью архитектуры хранилища данных. Метаданные — это данные, описывающие правила, по которым «живет» хранилище. Например, с точки зрения базы данных хранилища, метаданными является описание структур таблиц, взаимосвязей между ними, правил секционирования, описание витрин данных и т.п. С точки зрения ETL, метаданными являются описания правил извлечения и преобразования данных, периодичность выполнения ETL-процессов и т.п.
Обычно приведенные выше области хранения данных реализуются в виде отдельных схем одной или нескольких баз данных.
Ниже представлена общая схема организации областей хранения данных.
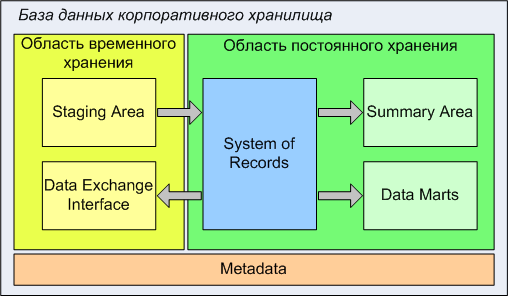
Область временного хранения данных (Staging Area)
Область временного хранения данных является промежуточным слоем между источниками данных и областью постоянного хранения. В данной области сохраняются извлеченные из операционных систем-источников (СУБД, csv, dbf, xml файлов, web-сервисов и т.д.) данные, производится их очистка, трансформация, обогащение, подготовка к загрузке в область постоянного хранения. Зачастую очередной цикл обработки и загрузки данных в хранилище не может быть начат пока не будут извлечены все необходимые данные из различных систем-источников, а в силу ряда причин (географической распределенности, разных циклов функционирования систем и т.п.) данные в источниках могут быть доступны в разные моменты по времени. Область временного хранения служит для сбора всех необходимых данных перед началом трансформации.
Одной из наиболее важных задач при построении хранилища данных является определение соответствия (mapping) сущностей систем-источников данных и сущностей модели хранилища данных. Обычно подобное соответствие представляет собой отношение десятков (а иногда и сотен) таблиц систем-источников к десяткам таблиц области постоянного хранения данных. Правильно организованная область временного хранения данных позволяет значительно упростить организацию процессов загрузки данных из области временного в область постоянного хранения.
Ниже представлены основные принципы формирования области временного хранения.
- В области временного хранения данных должно быть относительно небольшое количество сущностей — до 20, в которые сохраняются все необходимые данные, извлеченные из систем-источников.
- Основой для проектирования состава сущностей области временного хранения должны являться предметные области (Subject Area) модели данных.
- При извлечении данных из систем-источников сами данные и их типы не должны принципиально изменяться.
Детальные данные (System of records)
Данная область является основной хранилища данных.
В этой области хранятся преобразованные и очищенные детальные данные, полученные из систем-источников, и основные классификаторы. Хорошо спроектированная модель данной области является залогом дальнейшего успешного функционирования базы данных и BI-приложения.
Данная область содержит следующие типы сущностей:
- справочники и классификаторы;
- сущности, содержащие фактические значения;
- сущности, описывающие связи.
Справочники и классификаторы определяют:
- участников основных бизнес-процессов – клиентов, поставщиков, филиалы, услуги, продукты и т.п.
- базовые справочники – дата и время, валюта, страны и т.п.
- прочие справочники – отражающие потребности бизнеса в необходимой аналитике данных, определяющие в разрезе каких справочников необходимо анализировать фактические данные.
Сущности, содержащие фактические значения, – транзакционные данные из систем источников. Например, информация о совершенных телефонных звонках, выставленных счетах, проводках, проданных товарах и т.п.
Сущности, содержащие связи, определяют взаимосвязи между остальными сущностями. Например, Клиент-Услуга.
Область детальных данных не содержит никаких агрегатов. Только детальные, очищенные и структурированные в соответствии с моделью данные.
Агрегаты (Summary area)
В данной области хранятся агрегаты данных, которые в основном строятся для сущностей, описывающих участников бизнес-процессов. Например, агрегаты строятся для данных по продажам товаров, оказанию услуг, клиентам и т.п. Данные агрегируются в разрезе времени – от часа, дня к неделе, месяцу. Для каждого агрегата может быть определена своя степень агрегации данных.
Витрины данных (Data Marts)
Витрины данных являются объектами хранения аналитической информации, нацеленными на поддержку конкретных бизнес-функций, конкретных подразделений компании. На уровне базы данных витрины обычно реализуются по схеме «звезда» или «снежинка» и содержат данные из области детальных данных (System of records). Также могут быть реализованы в виде многомерного OLAP-куба. Витрины данных являются основой, обеспечивающей возможность проведения многомерного анализа (OLAP) данных.
Ниже представлены основные принципы проектирования витрин данных.
- Витрины данных ориентированы на бизнес и при их проектировании необходимо учесть все измерения, показатели и иерархии, необходимые пользователям.
- При проектировании витрин данных необходимо учитывать особенности BI-приложения, используемого на проекте.
Анализ качества баз данных
Например, в Oracle Discoverer нет возможности создавать несбалансированные иерархии и это нужно учитывать.
Интерфейсы обмена данными (Data Exchange Interface)
Хранилище обычно строится с целью консолидации в нем данных компании, и поэтому оно зачастую является источником данных для других информационных систем. Для обмена данными создаются интерфейсы обмена (обычно это таблицы базы данных), в которых и хранятся специально подготовленные (возможно, перед передачей данных потребуется их предобработка) для передачи данные. Интерфейсы обмена желательно создавать как можно более универсальными.
Метаданные (Metadata)
Разработка и сопровождение системы с хорошо спроектированными и описанными метаданными является более простой задачей, нежели при отсутствии таковых. Метаданные хранилища включают:
- информацию о данных, их бизнес-описание и структуру хранения;
- описание структур источников данных, их доступности;
- информацию о структуре процессов ETL, периодичности их выполнения, применяемых правил очистки и преобразования данных;
- описание бизнес-представления данных, помогающее пользователю работать с BI-приложением;
- информацию о настройках безопасности, правил аутентификации и назначенных прав доступа;
- статистику утилизации ресурсов, обращений к данным и др., которая помогает администратору оптимизировать работу базы данных хранилища.
Обычно управление метаданными осуществляется отдельными инструментами для каждого из компонентов хранилища. Например, для базы данных Oracle, метаданные которой хранятся в системных таблицах и настроечных файлах, это будет Oracle Enterprise Manager.
Ковтун М.В. Апрель 2011
Источники:
Курсовая работа
По дисциплине:
«Базы данных»
Тема:
«Хранилища данных»
Содержание
Введение
1. Хранилища данных
2. Принципы построения
2.1 Основные компоненты хранилища данных
3. Технологии управления информацией
3.1 OLАP‑технология
4. Понятие баз данных
5. Создание базы данных
5.1 Структура таблиц
5.2 Схема данных
5.3 Пользовательские формы
5.4 Создание запросов
5.5 Создание отчетов
6. Программная реализация базы данных
Заключение
Список используемых источников
Введение
Рассмотрим фирму, которая ведет некую производственную и торговую деятельность: скажем, что-то проектирует, производит и продает. Для продажи у нее имеется, в частности, торговая система, которая учитывает движение товарных и денежных средств.
Повседневная деятельность такой фирмы сопровождается ежедневным внесением в базу данных десятков счетов, накладных и других оперативных документов. Реляционные СУБД, рассмотренные выше, проектировались и используются для выполнения именно такой работы – для управления большим потоком транзакций, каждая из которых связана с внесением небольших изменений в оперативные данные предприятия. Системы такого типа называются системами оперативной обработки транзакций или OLTP(OnlineTransactionProcessing) Будем называть их просто оперативными системами.
Известно, что структура БД оперативных систем в высокой степени нормализована, т.е. состоит из множества таблиц, связанных между собой посредством внешних ключей. Такая нормализованная структура оптимизирована именно для быстрого поиска и обработки единичных записей.
Потребности в оперативных документах краткосрочны. С оперативными документами работают в течение какого-то времени: отслеживают оплату счета, приход денег, поставку товара и т.д. Для контроля данного процесса периодически формируются отчеты, которые имеют несколько стандартных для фирмы разновидностей и строятся путем выборки данных непосредственно из БД торговой системы. Оперативный документ, сыграв свою роль, далее в рамках торговой системы, как правило, больше не используется. Со временем растущий объем данных начинает замедлять выполнение операций, что порождает естественное желание избавиться от старых неиспользуемых данных.
Между тем в накопленных данных содержится история развития предприятия, история его взаимоотношений с поставщиками и покупателями. Данные, накопленные в предприятии, – уникальный ресурс. В результате их анализа можно было бы получить ценнейшую информацию, позволяющую принимать эффективные управленческие решения. Ценность информации, а, следовательно, и глубина анализа еще более возрастут, если использовать объединенную информацию всего предприятия, всех его систем.
Но для этого руководителю может потребоваться исследование десятков тысяч комбинаций данных, не укладывающихся в имеющийся набор готовых отчетных форм.
Следует отметить, что подобные исследования редко проводятся самим руководителем.
Чаще он приглашает или выращивает в своей фирме аналитика, который хочет извлечь из данных все, что можно. Например, понять, какой тип клиентов наиболее перспективен для фирмы, или какие скидки будут оптимальными этой весной. Но сделать это оказывается не так-то просто.
Традиционный анализ, который, как правило, осуществляется при помощи изучения набора готовых отчетных форм, а его результатом является принятие одного из стандартных бизнес-решений, здесь явно не поможет. Если считать, что в распоряжении аналитика имеется только традиционная СУБД, то при выполнении возложенных на него обязанностей он столкнется с рядом проблем:
Построение сводных отчетов над нормализованной структурой, как правило, неэффективно: связывание большого числа таблиц в одном запросе выполняется достаточно долго, если объем этих таблиц велик; развернуть данные по любому измерению. Хранилища данных не заменяют, а дополняют традиционные реляционные базы данных с первичной информацией.
Для построения систем ОLАР используются специализированные многомерные БД либо надстройки над обычными реляционными БД. До последнего времени ОLАР-технология ассоциировалась с большими проектами по хранению массивов данных и сложными приложениями для их анализа. Сложный и дорогой ОLАР-инструментарий был доступен только очень крупным компаниям.
И все же в последнее время ситуация на рынке резко изменилась. Произошло это благодаря тому, что было найдено компромиссное решение: укомплектовать полноценным ОLАР-сервером хорошо зарекомендовавшие себя недорогие программные продукты. К таким продуктам относится, например, МSSQL‑сервер баз данных, начиная с версии 7 и позднее, который во всем мире активно используется для построения хранилищ данных.
Компания Microsoft предпринимает ряд серьезных мер, чтобы обеспечить наилучшую поддержку хранилищ данных и построения информационных систем. Вследствие указанного изменения ситуации современные OLАР-системы анализа данных стали действительно доступны малому и среднему бизнесу.
1. Хранилища данных
Хранилища данных – это процесс сбора, отсеивания и предварительной обработки данных с целью представления результирующей информации пользователям для статистического анализа и аналитических отчетов. Ральф Кинболл (автор концепции хранилищ данных) описывал хранилища данных как «место, где люди могут получить доступ к своим данным». Он же сформулировал основные требования к хранилищам данных:
– поддержка высокой скорости данных из хранилища;
– поддержка внутренней непротиворечивости данных;
– возможность получения и сравнения данных;
– наличие удобных утилит просмотра данных хранилища;
– полнота и достоверность хранимых данных;
– поддержка качественного процесса пополнения данных.
Всем перечисленным требованиям удовлетворять зачастую не удается, поэтому для реализации хранилищ данных используют несколько продуктов. Одни из которых представляют средства хранения данных, другие – средства их извлечения и просмотра, в-третьих – средства пополнения хранилищ данных. Типичное хранилище данных как правило отличается от реляционной базы данных: 1) Обычная база данных предназначена для того, чтобы помочь пользователям выполнять повседневную работу, тогда как хранилища данных предназначены для принятия решений; 2) Обычная база данных подвержена постоянным изменениям в процессе работы пользователей, а хранилища данных относительно стабильно; данные в нем обновляются согласно расписанию (например, ежечасно, ежедневно, ежемесячно), в идеале, процесс пополнения данными за определенный период времени без изменения прежней информации находящейся уже в хранилище. 3) Обычная база данных чаще всего является источником данных попадающих в хранилище, кроме того хранилище может пополняться за счет внешних источников (например, сжатия данных).
2. Принципы построения
Информация, которая загружается в хранилище, должна интегрироваться в целостную структуру, отвечающую целям анализа данных. При этом минимизируются несоответствия между данными из различных оперативных систем, в хранилище именуются и выражаются единым образом. Данные интегрированы на множестве уровней: на уровне ключа, атрибута, на описательном, структурном уровне и так далее. Общие данные и общая обработка данных консолидированы и являются единообразным для всех данных, которые подобны или схожи в хранилище данных. При этом информация структурируется по разным уровням детализации:
– высокая степень суммаризации;
– низкая степень суммаризации;
– текущая детальная информация.
Хранилища можно рассматривать как набор моментальных снимков состояния данных: можно восстановить картинку на любой момент времени. Атрибут времени всегда явно присутствует в структурах данных хранилища.
Попав однажды в хранилище, данные уже никогда не изменяются, а только пополняются новыми данными из оперативных систем, где данные постоянно меняются. Новые данные по мере поступления обобщаются с уже накопленной информацией в хранилище данных.
2.1 Основные компоненты хранилища данных
Использование технологии хранилищ данных предполагает наличие в системе следующих компонентов:
– оперативных источников данных;
– средств переноса и трансформации данных;
– метаданных – включают каталог хранилища и правила преобразования данных при загрузке их из оперативных баз данных;
– реляционного хранилища;
– OLAP‑хранилища;
– средств доступа и анализа данных.
Назначение перечисленных компонентов таково. Оперативные данные собираются из различных источников. Поступившие оперативные данные очищаются, интегрируются и складываются в реляционные хранилище. Они уже доступны для анализа при помощи средств построения отчетов. Затем данные (полностью или частично) подготавливаются с использованием средств переноса и трансформации данных для OLAP‑анализа, который реализуется применением средств доступа и анализа данных. При этом они могут быть загружены в специальную базу данных OLAP или оставаться в реляционном хранилище.
Важнейшим элементом хранилища являются метаданные, т.е. данные о структуре, размещении, трансформации данных, которые используются любыми процессами хранилища. Метаданные могут быть востребованы для различных целей, например: извлечения и загрузки данных; обслуживании хранилища и запросов. Метаданные для различных процессов могут иметь различную структуру, т.е.
Анализ продуктов. Анализ баз данных
для одного и того же элемента данных может существовать несколько вариантов метаданных.
Итак, хранилища данных являются структурированными. Они содержат базовые данные, которые образуют единый источник для обработки данных во всех системах поддержки принятия решений. Элементарные данные, присутствующие в хранилище, могут быть представлены в различной форме. Хранилища данных исключительно велики, поскольку в них содержатся интегрированные и детализированные данные.
Концепция хранилища данных
Понятие хранилища данных
«Хранилище данных»- это предметно-ориентированное, привязанное ко времени и неизменяемое собрание данных для поддержки процесса принятия управляющих решений.
Данные в хранилище попадают из оперативных систем (OLTP-систем), которые предназначены для автоматизации бизнес-процессов. Кроме того, хранилище может пополняться за счет внешних источников, например статистических отчетов, различных справочников и т.д. Хранилище данных кроме детализированной информации содержит в себе агрегаты, т.е. обобщающую информацию, например суммы продаж, количество, общие расходы и т.д.
Хранилище налоговых данных следует рассматривать как центр информации, в котором автоматизируется расчет отложенных налогов, принимается и хранится информация из внешних источников, а данные преобразуются в удобный для пользователей формат. Такое хранилище представляет собой площадку для хранения точных и оперативных налоговых данных, которые могут быть извлечены и переданы во внешние приложения для целей анализа, аудита, планирования и прогнозирования.
Хранилище данных представляет собой репозитарий информационных ресурсов и обеспечивает консолидацию данных предприятия для целей отчетности и анализа. Данные и информация, как операционная, так и неоперационная, вводятся в хранилище обычно при помощи инструментов ETL из источников, данных по мере их появления или на регулярной основе. Трансформация данных позволяет своевременно обрабатывать запросы и анализировать их, что упрощает и ускоряет процесс выполнения запросов на информацию, изначально поступившую из других источников.
Преимущества, которые дает хранилище, включают возможность преобразования данных в качественную информацию, необходимую для подготовки налоговой отчетности и соблюдения налогового законодательства, для пользователей всех уровней. Любые заинтересованные лица – клиенты, партнеры, сотрудники, менеджеры и руководители – могут получать интерактивный контент когда угодно и где угодно.
Само наличие единого источника информации для подготовки налоговой отчетности и соблюдения налогового законодательства является большим шагом вперед для многих налоговых служб.
Зачем нужно строить хранилища данных — ведь они содержат заведомо избыточную информацию, которая и так находится в базах или файлах оперативных систем? Анализировать данные оперативных систем напрямую невозможно или очень затруднительно. Это объясняется различными причинами, в том числе разрозненностью данных и хранением их в форматах различных СУБД. Но даже если на предприятии все данные хранятся на центральном сервере БД, аналитик почти наверняка не разберется в их сложных, подчас запутанных структурах.
Таким образом, задача хранилища — предоставить «сырье» для анализа в одном месте и в простой, понятной структуре.
Есть и еще одна причина, оправдывающая появление отдельного хранилища — сложные аналитические запросы к оперативной информации тормозят текущую работу компании, надолго блокируя таблицы и захватывая ресурсы сервера.
Под хранилищем можно понимать не обязательно гигантское скопление данных — главное, чтобы оно было удобно для анализа.
Концепция хранилища данных
Автором концепции хранилищ данных (Data Warehouse) является Б. Инмон, который определил хранилища данных как: «предметно-ориентированные, интегрированные, неизменчивые, поддерживающие хронологию наборы данных, организованные для целей поддержки управления», призванные выступать в роли «единого и единственного источника истины», обеспечивающего менеджеров и аналитиков достоверной информацией, необходимой для оперативного анализа и принятия решений. Схему хранилища данных можно представить следующим образом:


Физическая реализация данной схемы может быть самой разнообразной. Рассмотрим первый вариант — виртуальное хранилище данных, это система, предоставляющая доступ к обычной регистрирующей системе, которая эмулирует работу с хранилищем данных. Виртуальное хранилище можно организовать двумя способами. Можно создать ряд «представлений» (view) в базе данных или использовать специальные средства доступа к базе данных (например, продукты класса desktop OLAP).

Поскольку конструирование хранилища данных — сложный процесс, который может занять несколько лет, некоторые организации вместо этого строят витрины данных (data mart), содержащие информацию для конкретных подразделений.
Например, маркетинговая витрина данных может содержать только информацию о клиентах, продуктах и продажах и не включать в себя планы поставок. Несколько витрин данных для подразделений могут сосуществовать с основным хранилищем данных, давая частичное представление о содержании хранилища. Витрины данных строятся значительно быстрее, чем хранилище, но впоследствии могут возникнуть серьезные проблемы с интеграцией, если первоначальное планирование проводилось без учета полной бизнес-модели. Это второй способ.

Построение полноценного корпоративного хранилища данных обычно выполняется в трехуровневой архитектуре. На первом уровне расположены разнообразные источники данных — внутренние регистрирующие системы, справочные системы, внешние источники (данные информационных агентств, макроэкономические показатели). Второй уровень содержит центральное хранилище, куда стекается информация от всех источников с первого уровня, и, возможно, оперативный склад данных, который не содержит исторических данных и выполняет две основные функции.

В основе концепции хранилищ данных лежат две основополагающие идеи:
1) интеграция ранее разъединенных детализированных данных в едином хранилище данных, их согласование и, возможно, агрегация:
· исторических архивов;
· данных из традиционных СОД;
· данных из внешних источников.
2) разделение наборов данных, используемых для операционной обработки, и наборов данных, применяемых для решения задач анализа.
Цель концепции хранилищ данных — выяснить требования к данным, помещаемым в целевую БД хранилища данных (Таблица 1), определить общие принципы и этапы ее построения, основные источники данных, дать рекомендации по решению потенциальных проблем, возникающих при их выгрузке, очистке, согласовании, транспортировке и загрузке в целевую БД.
Таблица 1. Основные требования к данным в Хранилище Данных.
| Предметная ориентированность | Все данные о некотором предмете (бизнес-объекте) собираются (обычно из множества различных источников), очищаются, согласовываются, дополняются, агрегируются и представляются в единой, удобной для их использования в бизнес-анализе форме. |
| Интегрированность | Все данные о разных бизнес-объектах взаимно согласованы и хранятся в едином общекорпоративном Хранилище. |
| Неизменчивость | Исходные (исторические) данные, после того как они были согласованы, верифицированы и внесены в общекорпоративное Хранилище, остаются неизменными и используются исключительно в режиме чтения. |
| Поддержка хронологии | Данные хронологически структурированы и отражают историю, за достаточный для выполнения задач бизнес-анализа и прогнозирования период времени. |
Предметом концепции хранилищ данных служат сами данные. После того как традиционная система обработки данных (СОД) реализована и начинает функционировать, она становится ровно таким же самостоятельным объектом реального мира, как и любой производственный процесс. А данные, которые являются одним из конечных продуктов такого производства, обладают ровно теми же свойствами и характеристиками, что и любой промышленный продукт: сроком годности, местом складирования (хранения), совместимостью с данными из других производств (СОД), рыночной стоимостью, транспортабельностью, комплектностью, ремонтопригодностью и т. д.
Именно с этой точки зрения и рассматриваются данные в хранилищах данных. То есть целью здесь являются не способы описания и отображения объектов предметной области, а собственно данные, как самостоятельный объект предметной области, порожденной в результате функционирования ранее созданных информационных систем.
Для правильного понимания данной концепции необходимо уяснение следующих принципиальных моментов:
· Концепция хранилищ данных — это не концепция анализа данных, скорее, это концепция подготовки данных для анализа.
· Концепция хранилищ данных не предопределяет архитектуру целевой аналитической системы. Она говорит о том, какие процессы должны выполняться в системе, но не о том, где конкретно и как эти процессы должны выполняться.
·Концепция хранилищ данных предполагает не просто единый логический взгляд на данные организации, а реализацию единого интегрированного источника данных.
Кроме единого справочника метаданных, средств выгрузки, агрегации и согласования данных, концепция хранилищ данных подразумевает: интегрированность, неизменчивость, поддержку хронологии и согласованность данных. И если два первых свойства (интегрированность и неизменчивость) влияют на режимы анализа данных, то последние два (поддержка хронологии и согласованность) существенно сужают список решаемых аналитических задач.
Без поддержки хронологии (наличия исторических данных) нельзя говорить о решении задач прогнозирования и анализа тенденций. Но наиболее критичными и болезненными оказываются вопросы, связанные с согласованием данных.
Основным требованием аналитика является даже не столько оперативность, сколько достоверность ответа. Но достоверность, в конечном счете, и определяется согласованностью. Пока не проведена работа по взаимному согласованию значений данных из различных источников, сложно говорить об их достоверности.
Нередко, менеджер сталкивается с ситуацией, когда на один и тот же вопрос, различные системы могут дать и обычно дают различный ответ. Это может быть связано как с несинхронностью моментов модификации данных, отличиями в трактовке одних и тех же событий, понятий и данных, изменением семантики данных в процессе развития предметной области, элементарными ошибками при вводе и обработке, частичной утратой отдельных фрагментов архивов и т.
Исследование Базы данных
д. Очевидно, что учесть и заранее определить алгоритмы разрешения всех возможных коллизий мало реально. Тем более, это нереально сделать в оперативном режиме, динамически, непосредственно в процессе формирования ответа на запрос.
Дата добавления: 2016-12-31; просмотров: 711 | Нарушение авторских прав
Похожая информация:
Поиск на сайте:
Анализ понятия базы данных
до 52 000
руб.
Упавляющая компания многопрофильного холдинга приглашает принять участие в открытом конкурсе на вакансию “Аналитик баз данных”
Обязанности:
- Разработка баз данных для хранения аналитической информации и процедуры обработки данных и оперативной отчетности;
- Администрирование и сопрвождение проекта “Консолидированная база данных”;
- Обеспечение интеграции различных программных приложений для решения оптимизационных и стратегических задач;
- Выявление и исправление ошибок в информации, предоставляемой дистрибуторами для загрузки;
- Описание и документирование всех источников данных, выходных форм автоматизированной отчетности, созданных приложений;
- Создание справочников продукции и клиентов холдинга.
Требования:
- Образование: высшее профессиональное (математическое, техническое);
- Опыт работы: не менее 3- лет в сфере анализа и статистической обработки данных;
- Знание и опыт программирования: С#, VB, VB.NET, C++, SQL, реляционные базы данных, Web-программирование (HTML, PHP, ASP, ASP.NET);
- Знание компьютерных программ: MS Access, MS Office – уровень продвинутого пользователя;
- Аналитический склад ума, исполнительность, ответственность, самостоятельность.
Условия:
- Уровень заработной платы с успешным кандитатом обсуждается индивидуально;
- Оформление по Тк РФ;
- Место работы: м.Калужская, бизнес-центр “Кругозор”.
Похожие:
- Программист баз данных MS SQL
- Администратор баз данных
- Администратор баз данных и приложений
- Старший администратор баз данных
- Программист баз данных (С#, MS SQL)
FILED UNDER : IT