admin / 29.01.2018
Новым процессорам — новые компиляторы | Открытые системы. СУБД | Издательство «Открытые системы»
.
Подход к распараллеливанию в DataRush начинается на уровне программных тредов. Программа может иметь несколько тредов и в пределах одного ядра. Нужно помнить, что ядро может в любой момент времени обслуживать только один тред, при этом тред может «повисать», когда программа ждет получения того или иного ресурса. Переключение исполнения с одного треда на другой сопряжено с изменением контекста, а это требует времени. На рис. 6 этот процесс проиллюстрирован в упрощенном виде. Здесь имеется 4 ядра с разным числом исполняемых тредов в каждом (3,2,4,2). Эффективное управление такой системой со стороны программиста практически не реально. Эту задачу решает DataRush, при этом в процессе управления он может учитывать то, где находятся данные, подлежащие обработке. Нужно учитывать, что разные приложения и треды используют часто одно и то же пространство памяти. С учетом тенденции роста числа процессоров и ядер в одном сервере (в 2010 году их число достигает 48), а также объема оперативной и виртуальной памяти эксплуатационные характеристики DataRush только улучшаются.
Рис. 6. Переплетение тредов
Содержание
Области применения
На рис. 7 представлены типичные применения DataRush и Hadoop/MapReduce. По горизонтальной оси отложен объем данных в логарифмическом масштабе (от мегабайт до экзабайт). В настоящее время корпоративные базы данных имею объем менее терабайта. Тенденция же роста объема данных самоочевидна. По вертикальной оси отложена сложность задач. В верхней части рисунка размещены задачи типа моделирования климата, анализ сейсмических данных, гидродинамика и физика элементарных частиц.
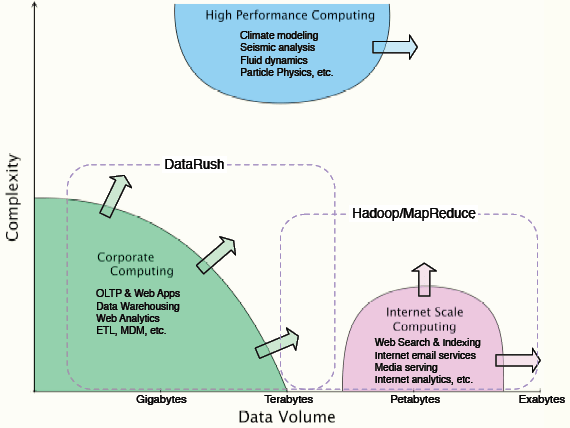
Рис. 7. Карта приложений с учетом сложности и объема данных
Задачи оптимизации для каждого класса задач решается независимо.
Возникает вопрос, станут ли параллельные вычисления нормой? Здесь нужно учитывать то, что существует огромное число программ, которые могут исполняться только на одном процессоре. В то же время разработаны и продолжают разрабатываться ОС, которые позволяют исполнять традиционные «старые» программы на многоядерных серверах, при этом достигается существенное ускорение их исполнения. C учетом сложившихся технологических ограничений следует признать, что параллельным вычислениям в перспективе нет альтернативы.
Анализ использования параллельных вычислений в бизнесе, где требований к быстродействию на первый взгляд ограничены, также показывает преимущества использования параллельных технологий.
Ссылки
- Теория и практика параллельных вычислений. В.П.
Автоматическое распараллеливание
Гергель. Интернет университет
- Информационно-аналитический центр по параллельным вычислениям Параллельные вычисления в России.
- Научные ресурсы. Параллельные вычисления. Информационно-аналитический центр по параллельным вычислениям (МГУ)
- «APPLIED PARALLEL COMPUTING» E&R CENTER
.
Распараллеливание — вычисление
Cтраница 1
Распараллеливание вычислений здесь возможно только на первом уровне. Система уравнений материального и теплового баланса схемы ( I, 65) может решаться как последовательно, так и параллельно. В случае последовательного решения возможности параллельного счета очень ограничены. [1]
Распараллеливание вычислений позволило увеличить быстродействие вычислительных устройств, но при этом значительно увеличило аппаратурные затраты.
Современная микроэлектронная элементная база предоставляет разработчику возможность построения высокопроизводительных систем обработки изображений с параллельной организацией вычислительных процессов, сочетающих относительно малые стоимость и габариты с высоким быстродействием и гибкостью обработки. Вопросы разработки алгоритмов наиболее часто встречающихся операций, позволяющих синтезировать регулярные, модульно наращиваемые процессоры, удобные для реализации в БИС и на основе стандартных микропроцессорных комплектов, а также осуществляющие обработку изображений в реальном масштабе времени, являются в настоящее время исключительно актуальными. [2]
Распараллеливание вычислений между несколькими ведущими микро — УВМ системы позволяет существенно повысить ее производительность. [3]
Алгоритм распараллеливания вычислений с помощью метода Монте-Карло. [4]
Идеология распараллеливания вычислений, заложенная в нейросетевые алгоритмы решения задач, неэффективно реализуется в существующих компьютерах, реализующих архитектуру вычислительных систем фон Неймана, то есть систем с центральным процессором. [5]
Возможность распараллеливания вычислений БО приводит к многообразию структурных вариантов реализации АУ. [6]
Это допускает распараллеливание вычислений. [7]
Перечисленные выше способы распараллеливания вычислений предполагают расчленение единой задачи на различных уровнях независимо от исходной информации. Еще одним методом распределения загрузки по компонентам ВС является метод распараллеливания по процессорам или машинам объектов, информация о которых подлежит обработке по одинаковым программам. В этом случае связность между программами различных машин определяется использованием общей исходной и обработанной информации по объектам. Результаты обработки информации некоторого объекта используются той же машиной в последующих циклах обработки, а также остальными машинами ВС при обработке данных по назначенным им объектам. Таким образом, связность функционирования программ определяется информационной и функциональной связностью управляемых объектов. [8]
Разработан ряд стохастических методов решения поставленной оптимизационной задачи распараллеливания вычислений. В первом методе — стохастическом методе попарной оптимизации подграфов — поиск оптимального решения осуществляется за счет взаимного ( стохастического) переноса вершин между различными парами подграфов графа алгоритма. Второй метод — метод Монте-Карло случайного блуждания вершин графа алгоритма по подграфам — основан на отождествлении вершин графа алгоритма с некоторыми частицами, совершающими случайные блуждания по областям-подграфам в потенциальном силовом поле, роль потенциала которого играет минимизируемый функционал. Наиболее вероятное состояние подобной системы частиц соответствует минимуму потенциала — и, следовательно, является искомым решением. [10]
Разработан ряд стохастических методов решения поставленной оптимизационной задачи распараллеливания вычислений. В первом методе — стохастическом методе попарной оптимизации подграфов — поиск оптимального решения осуществляется за счет взаимного ( стохастического) переноса вершин между различными парами подграфов графа алгоритма. Второй метод — метод Монте-Карло случайного блуждания вершин графа алгоритма по подграфам — основан на отождествлении вершин графа алгоритма с некоторыми частицами, совершающими случайные блуждания по областям-подграфам в потенциальном силовом поле, роль потенциала которого играет минимизируемый функционал. Наиболее вероятное состояние подобной системы частиц соответствует минимуму потенциала — — и, следовательно, является искомым решением. Поиск такого состояния осуществляется методом Монте-Карло с использованием специальной процедуры имитации отжига. Третий метод — стохастический метод наискорейшего спуска — основан на использовании дискретного аналога градиента минимизируемого функционала. Все разработанные методы реализованы программно и являются частью системы программ PARALLAX. Проведено тестирование созданных программ и сравнение их работы на простейших примерах.
Вопрос Upgrade Пк
[11]
К функциям DCE относятся распределение вычислений по технологии RPC; распараллеливание вычислений ( но программист сам проектирует параллельный процесс); защита данных; синхронизация ( согласование времени); поддержка распределенной файловой системы. [12]
Ее выбор обусловлен тем обстоятельством, что при выбранной схеме распараллеливания вычислений наряду с распараллеливанием по процессам необходимо распараллеливание по данным — различные потоки команд управляют различными потоками данных в вычислительном процессе. Структура обменов однородна в пределах одного блока ( метода) и между блоками и не однородна при передаче параметров каждого из методов. Кроме того, корневой процесс выполняет вычисления, необходимые для обновления матрицы исходных данных, с последующей рассылкой этого значения остальным процессам, выбора наилучшего варианта среди моделей одного метода, окончательного выбора модели на текущем шаге. [13]
Это существенно сокращает объем вычислений при выводе графической информации и обеспечивает возможность распараллеливания вычислений при пересчете координат. [14]
Существует два принципиальных направления сокращения времени синтеза изображений: устранение заведомо лишних вычислений и распараллеливание вычислений. Потребность в ускорении процесса синтеза связана с тем, что высококачественные и сложные изображения формируются на однопроцессорных машинах за десятки минут, что выходит за рамки даже самых скромных потребительских требований. [15]
Страницы: 1 2 3

FILED UNDER : IT