admin / 22.01.2018
Ошибка первого рода
.
Содержание
Ошибки первого и второго рода: расчет вероятности ошибки первого и второго рода
123456
Проверка статистической гипотезы означает проверку согласования исходных выборочных данных с выдвинутой основной гипотезой. При этом возможно возникновение двух ситуаций – основная гипотеза может подтвердиться, а может и быть опровергнута. Следовательно, при проверке статистических гипотез существует вероятность допустить ошибку, приняв или опровергнув верную гипотезу.
При проверке статистических гипотез можно допустить ошибки первого или второго рода
Ошибкой первого рода – отвергаем верную гипотезу.
Ошибкой второго рода– не отвергаем неверную гипотезу.
Уровнем значимости α называется вероятность совершения ошибки первого рода.
Значение уровня значимости α обычно задаётся близким к нулю (например, 0,05; 0,01;0,02 и т. д.), потому что чем меньше значение уровня значимости, тем меньше вероятность совершения ошибки первого рода, состоящую в опровержении верной гипотезы Н0.
Вероятность совершения ошибки второго рода, т. е. принятия ложной гипотезы, обозначается β
При проверке нулевой гипотезы Н0 возможно возникновение следующих ситуаций:

N.
Ошибки первого и второго рода: расчет вероятности ошибки первого и второго рода
B.! Смотрим распределение вероятностей по распределению верной гипотезы, то есть ошибку второго ищем по Н1, а не по Н0.
1- β – мощность критерия – способность теста обнаруживать альтернативную гипотезу или способность отвергать Н0, когда верна альтернатива (показывает насколько хороша статистика).
Таким образом, чем выше мощность, тем меньше вероятность совершить ошибку второго рода.
При проверке гипотез возникают ошибки двух типов. Ошибка первого рода — отвергнуть Н0 , в то время, как она является верной; и ошибка второго рода – принять нулевую гипотезу, которая в действительности является неверной. Вероятность ошибки первого рода называется уровнем значимости и обозначается α. Таким образом, α = Р{U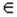 Ψ | H0}, т.е уровень значимости α – это вероятность события{U Ψ}, вычисленная в предположении о том, что Н0 верна. Наиболее часто уровень значимости принимают равным 0.05 или 0.01. Если, например, принят уровень значимости, равный 0.05, то это означает, что в пяти случаях из ста мы рискуем допустить ошибку первого рода (отвергнуть правильную гипотезу).
Ψ | H0}, т.е уровень значимости α – это вероятность события{U Ψ}, вычисленная в предположении о том, что Н0 верна. Наиболее часто уровень значимости принимают равным 0.05 или 0.01. Если, например, принят уровень значимости, равный 0.05, то это означает, что в пяти случаях из ста мы рискуем допустить ошибку первого рода (отвергнуть правильную гипотезу).
Уровень значимости ошибки однозначно определен, если гипотеза простая (Н0 : р=1/4 , Н1 : р 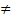 1/4), то есть распределение вероятностей задано точно. Когда же гипотеза сложная, то есть задан тип распределения вероятности с точностью до параметра (Н0 : р=1/4, Н1: р
1/4), то есть распределение вероятностей задано точно. Когда же гипотеза сложная, то есть задан тип распределения вероятности с точностью до параметра (Н0 : р=1/4, Н1: р 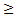 1/4, Н1: р
1/4, Н1: р 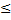 1/4, Н1
1/4, Н1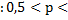 0,8)
0,8)
Для проверки как нулевой так и альтернативной гипотезы используется специально подобранная 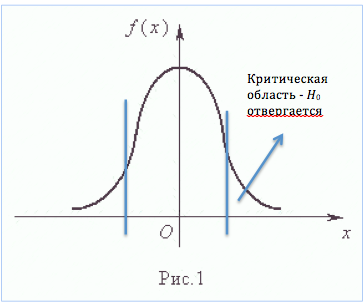 величина, значение которой точно или приближенно известно, соответственно Z – нормальное распределение, F – Фишер, t – Стьюдент,
величина, значение которой точно или приближенно известно, соответственно Z – нормальное распределение, F – Фишер, t – Стьюдент, 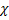 2 – «хи-квадрат». После выбора определенного критерия множество всех его возможных значений разделяют на два непересекающихся подмножества: то, где гипотеза принимается, и то, где нет.
2 – «хи-квадрат». После выбора определенного критерия множество всех его возможных значений разделяют на два непересекающихся подмножества: то, где гипотеза принимается, и то, где нет.
Вероятность ошибки второго рода есть P{U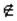 Ψ | H1}. Обычно используют не эту вероятность, а а ее дополнение 1, т.е. P{U Ψ | H1} = 1 — P{U Ψ | H1}. Эта величина носит название мощности критерия. Таким образом, мощность критерия – это вероятность того, что нулевая гипотеза будет отвергнута, когда альтернативная верна. Чаще всего мощность критерия обозначается как (1-
Ψ | H1}. Обычно используют не эту вероятность, а а ее дополнение 1, т.е. P{U Ψ | H1} = 1 — P{U Ψ | H1}. Эта величина носит название мощности критерия. Таким образом, мощность критерия – это вероятность того, что нулевая гипотеза будет отвергнута, когда альтернативная верна. Чаще всего мощность критерия обозначается как (1- 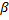 ), где
), где 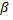 – ошибка второго рода. Стоит отметить, что мощность критерия – достаточно слабая статистика, потому что ошибки в ней слишком часты.
– ошибка второго рода. Стоит отметить, что мощность критерия – достаточно слабая статистика, потому что ошибки в ней слишком часты.
Поскольку исследователь хочет прийти к правильному выводу, надежные исследования планируются таким образом, чтобы обеспечить низкий уровень а и большую мощность. При низком уровне а крайне мало шансов отвергнуть правильную нулевую гипотезу, а при большой мощности критерия больше шансов принять правильную альтернативную гипотезу.
Существует несколько способов увеличить мощность критерия:
· Повысить уровень значимомсти. Так повышается вероятность отвергнуть нулевую гипотезу и, соответственно, принять верную альтернативную. Вместе с тем растет риск отвергнуть же нулевую гипотезу, которая может оказаться верной, и совершить таким образом ошибку первого рода.
· Формулирование направленных гипотез – исследователь может сосредоточиться на риске с уровнем 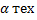 исходов, которые соответствуют выбранной гипотезе.
исходов, которые соответствуют выбранной гипотезе.
· Увеличить размер выборки, т.к статистики, основанные на большом количестве респондентов, более устойчивы и обеспечивают более точную оценку характеристик генеральной совокупности. Т.е прибавка прямым образом повышает вероятность того, что будет принята верная гипотеза.
123456
.
Полнота и точность
Мы выяснили, что запросы к поисковым машинам могут быть совершенно разных типов и что большинство запросов имеет неявное условие релевантности, которое не присутствует в самом запросе, а находится в уме пользователя. В общем, релевантность, она же качество поиска, — довольно сложная вещь.
Как же оценить качество работы поисковика с запросами? Для этого применяются понятия, традиционные для задач поиска информации, — полнота и точность.
Полнота
Полнота поиска — это мера того, нашел ли поисковик все нужные веб-страницы, которые есть в Сети. Проще всего вычислять полноту в процентах от всех релевантных запросу страниц. Например, если в Интернете есть 100 тысяч страниц, посвященных группе «Ногу свело», а поисковик нашел лишь 65 тысяч из них, «не заметив» остальные по тем или иным причинам, то полнота будет равна 65%.
Заметим, что из данного, вполне жизненного примера видно, что полнота поиска не очень-то интересна обычному пользователю интернет-поисковика.
Ведь в Сети всегда слишком много данных. Все равно невозможно просмотреть ни 100 тысяч страниц, ни 65 тысяч…
А ведь поисковик показывает данные постранично — первые десять найденных страниц, потом еще десять и т.
д. Большинство обычных пользователей (до 80%) не заглядывают дальше первой-второй страницы результатов поиска, просматривая только первые 10-20 ссылок. Поэтому не очень важно, сколько релевантных результатов (десять тысяч, сто тысяч или миллион) осталось за пределами первых страниц результатов поиска или вообще не было найдено в Сети.
Ошибка второго рода и кривые оперативной характеристики в MS EXCEL
И того, что найдено, за глаза хватит.
Поэтому основным показателем качества работы интернет-поисковика является его точность.
Не полнота, а разнообразие
На самом деле полнота поиска — очень важна, если понимать ее не как требование найти все, а как требование разнообразия «верхней» части выдачи, то есть требование найти и показать все варианты, все типы ответов на запрос.
Например, если по запросу «дизайн» поисковик находит только релевантные документы, целиком посвященные дизайну сайтов, то полнота поиска явно низкая.
Желательно, чтобы также были найдены страницы про другие виды дизайна — дизайн квартир, ландшафтный дизайн, полиграфический дизайн и пр. Таким образом, если поисковик находит много, но по одной теме, то пользователь получает однообразную информацию.
Надо заметить, что в 2009-2010 годах поисковики стали обращать больше внимания на качество результатов поиска по таким неоднозначным запросам. Раньше по большинству «коммерческих» запросов было невозможно получить «некоммерческие» страницы вверху списка результатов поиска — первые десятки и даже сотни результатов поиска относились к коммерческой выдаче. Например, по запросу «цветы» вся поисковая выдача была забита страницами с предложениями доставки цветов, причем в основном по Москве. Сегодня ситуация меняется в лучшую для пользователя сторону — поисковая выдача становится более разнообразной.
Точность
Точность — это мера качества выданных результатов. Она вычисляется как количество релевантных страниц в общем объеме того, что выдал нам поисковик.
Если, допустим, по запросу нам выдано всего 1000 страниц, а на самом деле отношение к очистителям воздуха имеют только 850 из них, то точность поиска будет равна 85%. Ясно, что для поисковика точность важнее всего.
Однако из данного примера видно, что на самом деле нет смысла вычислять точность по всему объему найденных страниц. Гораздо важнее порядок выдачи. А что если все 150 нерелевантных страниц из 1000 окажутся в начале выдачи? Ясно, что средний пользователь, просматривающий две первые страницы результатов поиска (это максимум 20-30 первых результатов), сочтет такую выдачу абсолютно нерелевантной и будет прав.
Таким образом, важно не только обеспечить достаточную точность поиска, то есть релевантность всего объема найденных по запросу страниц, но и правильно расположить релевантные результаты в выдаче, то есть обеспечить правильный порядок, или ранжирование результатов поиска.
FILED UNDER : IT