admin / 22.01.2018
Unicode сколько бит на символ
Вы не увидите простой ответ, потому что его нет.
Во-первых, Unicode не содержит «каждого символа с каждого языка», хотя он действительно пытается.
Юникод сам по себе является отображением, он определяет кодовые точки, а кодовой точкой является число, связанное обычно с символом. Обычно я говорю, потому что есть такие понятия, как объединение символов. Вы можете быть знакомы с такими вещами, как акценты или умлауты. Они могут использоваться с другим символом, например или для создания нового логического символа. Следовательно, персонаж может состоять из 1 или более кодовых точек.
Чтобы быть полезными в вычислительных системах, нам нужно выбрать представление для этой информации. Это различные кодировки unicode, такие как utf-8, utf-16le, utf-32 и т. Д. Они в значительной степени отличаются размером их кодовых элементов. UTF-32 — это простейшая кодировка, у нее есть код, 32 бита, что означает, что отдельный кодовый адрес удобно помещается в кодовую часть. Другие кодировки будут иметь ситуации, когда для кодовой точки потребуется несколько кодовых элементов, или что конкретный код не может быть вообще представлен в кодировке (это проблема, например, с UCS-2).
Из-за гибкости объединения символов даже в пределах данной кодировки количество байтов на символ может варьироваться в зависимости от характера и формы нормализации. Это протокол для работы с символами, которые имеют более одного представления (вы можете сказать который является 2 кодовыми точками, один из которых представляет собой комбинированный символ или который является одним кодовым ).
Проще говоря, — это стандарт, который присваивает один номер (называемый кодовой точкой) всем персонажам мира (его работа продолжается).
Теперь вам нужно представить эти кодовые точки, используя байты, которые называются . — это способы представления этих символов.
— многобайтовая кодировка символов. Символы могут иметь от 1 до 6 байтов (некоторые из них могут не потребоваться прямо сейчас).
каждый символ имеет 4 байта символов.
использует 16 бит для каждого символа и представляет только часть символов Юникода под названием BMP (для всех практических целей это достаточно). Java использует эту кодировку в своих строках.
В Unicode ответ нелегко дать. Проблема, как вы уже указывали, — это кодировки.
Учитывая любое английское предложение без диакритических символов, ответ для UTF-8 будет таким же количеством байтов, что и символы, а для UTF-16 это будет число символов раз два.
Единственная кодировка, где (на данный момент) мы можем сделать утверждение о размере UTF-32. Там он всегда 32 бит на персонажа, хотя я думаю, что кодовые точки подготовлены для будущего UTF-64 🙂
Что делает его настолько трудным, по крайней мере, две вещи:
- состоящие из символов, где вместо использования символьной сущности, которая уже подчеркнута / диакритическая (À), пользователь решил объединить акцент и базовый символ (`A).
- кодовые точки. Кодовые точки — это метод, с помощью которого кодировки UTF позволяют кодировать больше, чем количество бит, которое дает им свое имя, как правило, позволяют. Например, UTF-8 обозначает определенные байты, которые сами по себе недействительны, но если следовать за допустимым байтом продолжения, это позволит описать символ за пределами 8-битного диапазона 0..255. См. Examples и Overlong Encodings ниже в статье Википедии о UTF-8.
- Отличный пример что символ € (кодовая точка может быть представлен либо как трехбайтная последовательность либо четырехбайтная последовательность .
- Оба действительны, и это показывает, насколько сложным является ответ, говоря о «Юникоде», а не о конкретной кодировке Unicode, такой как UTF-8 или UTF-16.
Существует отличный инструмент для вычисления байтов любой строки в UTF-8: http://mothereff.in/byte-counter
Обновление: @mathias сделал код общедоступным: https://github.com/mathiasbynens/mothereff.in/blob/master/byte-counter/eff.js
Для UTF-16 персонаж нуждается в четырех байтах (два блока кода), если он начинается с 0xD800 или выше; такой символ называется «суррогатной парой». Более конкретно, суррогатная пара имеет форму:
где […] указывает двухбайтовый блок кода с заданным диапазоном. Anything <= 0xD7FF — это один блок кода (два байта). Ничего> = 0xE000 недействительно (кроме маркеров спецификации, возможно).
См. http://unicodebook.readthedocs.io/unicode_encodings.html , раздел 7.5.
 Теоретически давно существует решение этих проблем. Оно называется Unicode (Юникод). Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т.е. 16 бит. На основании такой таблицы может быть закодировано N=216=65 536 символов.
Теоретически давно существует решение этих проблем. Оно называется Unicode (Юникод). Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т.е. 16 бит. На основании такой таблицы может быть закодировано N=216=65 536 символов.
Юникод включает практически все современные письменности, в том числе: арабскую, армянскую, бенгальскую, бирманскую, греческую, грузинскую, деванагари, иврит, кириллицу, коптскую, кхмерскую, латинскую, тамильскую, хангыль, хань (Китай, Япония, Корея), чероки, эфиопскую, японскую (катакана, хирагана, кандзи) и другие.
С академической целью добавлены многие исторические письменности, в том числе: древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
Для символов кириллицы в Юникоде выделено два диапазона кодов:
Cyrillic (#0400 — #04FF)
Cyrillic Supplement (#0500 — #052F).
Но внедрение таблицы Unicode в чистом виде сдерживается по той причине, что если код одного символа будет занимать не один байт, а два байта, что для хранения текста понадобится вдвое больше дискового пространства, а для его передачи по каналам связи – вдвое больше времени.
Поэтому сейчас на практике больше распространено представление Юникода UTF-8 (Unicode Transformation Format). UTF-8 обеспечивает наилучшую совместимость с системами, использующими 8-битные символы. Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 4 байтов. В целом, так как самые распространенные в мире символы – символы латинского алфавита — в UTF-8 по-прежнему занимают 1 байт, такое кодирование экономичнее, чем чистый Юникод.
Задачи
1. В кодируемом английском тексте используется только 26 букв латинского алфавита и еще 6 знаков пунктуации. В этом случае текст, содержащий 1000 символов можно гарантированно сжать без потерь информации до размера:
— 8000 бит;
— 7000 бит;
— 5000 бит;
— 1000 бит.
2.
Словарь Эллочки – «людоедки» (персонаж романа «Двенадцать стульев») составляет 30 слов. Сколько бит достаточно, чтобы закодировать весь словарный запас Эллочки? Варианты: 8, 5, 3, 1.
4.4. Единицы измерения объема данных и ёмкости памяти: килобайты, мегабайты, гигабайты…
Итак, в мы выяснили, что в большинстве современных кодировок под хранение на электронных носителях информации одного символа текста отводится 1 байт. Т.е. в байтах измеряется объем (V), занимаемый данными при их хранении и передаче (файлы, сообщения).
Объем данных (V) – количество байт, которое требуется для их хранения в памяти электронного носителя информации.
Память носителей в свою очередь имеет ограниченную ёмкость, т.е. способность вместить в себе определенный объем. Ёмкость памяти электронных носителей информации, естественно, также измеряется в байтах.
Однако байт – мелкая единица измерения объема данных, более крупными являются килобайт, мегабайт, гигабайт, терабайт…
Следует запомнить, что приставки “кило”, “мега”, “гига”… не являются в данном случае десятичными. Так “кило” в слове “килобайт” не означает “тысяча”, т.е. не означает “103”. Бит – двоичная единица, и по этой причине в информатике удобно пользоваться единицами измерения кратными числу “2”, а не числу “10”.
1 байт = 23 =8 бит, 1 килобайт = 210 = 1024 байта. В двоичном виде 1 килобайт = &10000000000 байт.
Т.е. “кило” здесь обозначает ближайшее к тысяче число, являющееся при этом степенью числа 2, т.е. являющееся “круглым” числом в двоичной системе счисления.
Таблица 11.
| Именование | Обозначение | Значение в байтах | |
| килобайт | 1 Кb | 210 b | 1 024 b |
| мегабайт | 1 Mb | 210 Kb = 220 b | 1 048 576 b |
| гигабайт | 1 Gb | 210 Mb = 230 b | 1 073 741 824 b |
| терабайт | 1 Tb | 210 Gb = 240 b | 1 099 511 627 776 b |
В связи, с тем, что единицы измерения объема и ёмкости носителей информации кратны 2 и не кратны 10, большинство задач по этой теме проще решается тогда, когда фигурирующие в них значения представляются степенями числа 2. Рассмотрим пример подобной задачи и ее решение:
В текстовом файле хранится текст объемом в 400 страниц. Каждая страница содержит 3200 символов. Если используется кодировка KOI-8 (8 бит на один символ), то размер файла составит:
— 1 Mb;
— 1,28 Mb;
— 1280 Kb;
— 1250 Kb.
Решение
1) Определяем общее количество символов в текстовом файле. При этом мы представляем числа, кратные степени числа 2 в виде степени числа 2, т.е. вместо 4, записываем 22 и т.п. Для определения степени можно использовать Таблицу 7.
 символов.
символов.
2) По условию задачи 1 символ занимает 8 бит, т.е. 1 байт => файл занимает 27*10000 байт.
3) 1 килобайт = 210 байт => объем файла в килобайтах равен:
 .
.
Задачи
1. Сколько бит в одном килобайте?
— &1000;
— &10000;
— &10000000;
— &10000000000000.
2. Чему равен 1 Мбайт?
— 1024 байта;
— 1024 килобайта;
— 1000000 бит;
— 1000000 байт.
3. Сколько бит в сообщении объемом четверть килобайта? Варианты: 250, 512, 2000, 2048.
4. Объем текстового файла 640 Kb. Файл содержит книгу, которая набрана в среднем по 32 строки на странице и по 64 символа в строке.
Содержание
- Unicode сколько бит на символ?
- Читайте также
- Сколько бит в символе?
- Представление символов, таблицы кодировок
- В чем суть кодировок текста.
- Дополнительные материалы по теме: Кодировка текста.
- Калькулятор кодов
- IP-адрес, пароли и коды
- Виды кодов
- Десятичный код.
- Перевод в двоичный код.
- Кодирование текстовой информации
- Таблица символов Юникода®
- Порядковый номер
- Код
- Символ
- 0 — 31
- 00000000 — 00011111
- 32 — 127
- 00100000 — 01111111
- 128 — 255
- 10000000 — 11111111
- Внутреннее представление слов в памяти компьютера
- Слова
- Память
- file
- 01100110
- 01101001
- 01101100
- 01100101
- disk
- 01100100
- 01101001
- 01110011
- 01101011
- Кодировки символов
Unicode сколько бит на символ?
Сколько страниц в книге: 160, 320, 540, 640, 1280?
5. Досье на сотрудников занимают 8 Mb. Каждое из них содержит 16 страниц (32 строки по 64 символа в строке). Сколько сотрудников в организации: 256; 512; 1024; 2048?
⇐ Предыдущая19202122232425262728Следующая ⇒
Дата публикования: 2014-11-02; Прочитано: 420 | Нарушение авторского права страницы

Для кодирования текстовых данных в ЭВМ используется специальный метод, согласно которому, каждому символу алфавита сопоставлено число. Эти соответствия сведены в специальные таблицы, называемые стандартами кодирования текстовых данных. При кодировании текста͵ каждый символ алфавита заменяется соответствующим ему числом. При раскодировании, наоборот числа заменяются соответствующими им символами. Для того чтобы не ошибиться при декодировании данных, числа, представляющие текст, разделены на зоны. Каждая зона имеет длину 1 байт (8 двоичных разрядов).
Сегодня очень широкое распространение получил стандарт, называемый ASKII (American Standard Code for Information Interchange — стандартный код информационного обмена США). Этот стандарт имеет две части таблицы базовую – содержащую символы математических операций, латиницы, знаки препинания и др.
и расширенную, содержащую символы национальных языков. Базовая часть всегда неизменна и использует для кодирования символов шестнадцатеричные коды 00 – 7F. Расширенная часть таблицы (коды 80 – FF) может использоваться разная. Таблица ASCII-кодов используемая в России приведена на рисунке 5.

Рисунок 5 – Таблица ASCII-кодов
Слово “information” записанное в кодах таблицы ASCII выглядит как:
В двоичном представлении на код каждой буквы отводится 1 байт. К примеру, символ i кодируется числом 105, ĸᴏᴛᴏᴩᴏᴇ в двоичном представлении выглядит как 0110 1001.
Читайте также
Кодирование числовых данных Восьмеричная и шестнадцатеричная системы счисления Перевод чисел из десятичной системы в восьмеричную производится также как и в двоичную с помощью умножения и деления, только не на 2, а на 8. Например, 58,32(10) 58 : 8 = 7 (2 в остатке) 7 :… [читать подробнее].
29, 125 Кодирование действительных чисел Запись действительного числа в двоич-ной форме выполняется в несколько этапов. Рассмотрим для примера запись числа 29,125. 1. Сначала число преобразуется в двоичную форму. При этом целая и дробная части… [читать подробнее].
Текстовую информацию кодируют двоичным кодом через обозначение каждого символа алфавита определенным целым числом. С помощью восьми двоичных разрядов возможно закодировать 256 различных символов. Данного количества символов достаточно для выражения всех символов… [читать подробнее].
Текстовую информацию кодируют двоичным кодом через обозначение каждого символа алфавита определенным целым числом. С помощью восьми двоичных разрядов возможно закодировать 256 различных символов. Данного количества символов достаточно для выражения всех символов… [читать подробнее].
Кроме числовой информации в компьютере может обрабатываться и текстовая информация, содержащая буквы, цифры, знаки препинания и другие символы.
Сколько бит в символе?
Обычно число различных символов не превышает 256, поэтому для представления символов в компьютере используют… [читать подробнее].
Начиная с конца 60-х годов, компьютеры все больше стали использоваться для обработки текстовых данных и в настоящее время большая часть персональных компьютеров в мире (и наибольшее время) занято обработкой именно текстов. Традиционно для кодирования одного символа… [читать подробнее].
При формировании любого текстового (символьного) документа характерно последовательное использование нескольких видов кодировок и их преобразований. Например, при вводе информации с клавиатуры каждое нажатие клавиши, на которой изображен требуемый символ, вызывает… [читать подробнее].
Если каждому символу алфавита сопоставить определенное целое число (например порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватит, чтобы выразить… [читать подробнее].
В традиционных кодировках для кодирования одного символа используется 8 бит. Легко подсчитать, что такой 8-разрядный код позволяет закодировать 256 различных символов. В качестве международного стандарта принята кодовая таблица ASCII (American Standard Code for Information Interchange), кодирующая… [читать подробнее].
Кодировка текста — понятие, которое часто встречается у веб-мастеров. Вёрстка html-документов и web-программирование нередко подразумевают работу с кодировкой файла. При неверно выбранной кодировке текста существует вероятность некорректного отображения информации браузерами — поскольку программы не всегда могут определить кодировку в автоматическом режиме.
Представление символов, таблицы кодировок
В случае ошибочного определения кодировки браузером, пользователь на экране увидит хаотичный набор нечитаемых символов вместо предполагаемого текста. Это — последствия несовпадения кодировки, указанной в параметрах html-страницы и непосредственно кодировки файла.
Кстати, на нашем сайте вы можете перевести любой текст в десятичный, шестнадцатеричный, двоичный код воспользовавшись Калькулятором кодов онлайн.
Другими словами, от этого параметра зависит корректное отображение веб-страниц. Самое время ответить на вопрос о том, что такое кодировка текста. Её также называют набором символов. Кодировкой является специальная стандартизованная таблица, которая задаёт соответствие между кодом и символом, который он обозначает. Код представлен нулями и единицами, т.е., битами, и любая кодировка содержит конечный набор символов. Количество бит (байт), которое задаёт код, а также набор конкретных символов — это основные параметры кодировок.
В чем суть кодировок текста.
Различные наборы символов сложились исторически и вследствие естественного развития компьютерной техники за последний полувек. Кодировка текста ASCII — один из первых наборов, разработанный в 1963 году и используемый до сих пор. Первоначально таблица содержала всего 128 символов, среди которых были буквы латинского алфавита, цифры и специальные символы. В дальнейшем это число было расширено до 256 — это позволило использовать буквы национальных алфавитов, в том числе и русского. Однако порядок и способ указания подобных символов не был регламентирован, что породило несколько несовместимых между собой кодировок: Windows-1251, КОИ-8. Помимо указанных кодировок, существовали также несовместимые (не-ASCII) варианты — например, CP866.
Стандарт Unicode (Юникод) был разработан для решения этих проблем. На нём основаны наборы символов UTF-8, UTF-16, UTF-32, самым популярным из которых является UTF-8. Обычно его и применяют для вёрстки современных web-страниц; на нём также основана работа большинства систем, таких как WordPress и Joomla. Кодировка текста UTF-8 поддерживает множество специальных символов (например, диакритические знаки и псевдографику), иероглифы и т.д. На сегодняшний день Юникод — самая универсальная кодировка текста.

Установка кодировки происходит на этапе сохранения файла. Веб-мастерам необходимо уметь работать с кодировками для обеспечения корректной работы своих сайтов. Например, если php-файл сохранён в одном наборе символов, а в заголовке (
) html-страницы указан другой — то это вызовет искажение текстовой информации. Важно также обращать внимание и на кодировку базы данных.
Дополнительные материалы по теме: Кодировка текста.
|
|||||||||
|
|
||||||||
|
|
||||||||
 |
 |
Кодирование текстовой информации
 |
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа «=», «(«, «&» и т.п. и даже (обратите особое внимание!) пробелы между словами. Да, не удивляйтесь: пустое место в тексте тоже должно иметь свое обозначение. |
Вспомним некоторые известные нам факты:
Множество символов, с помощью которых записывается текст, называется алфавитом.
Число символов в алфавите – это его мощность.
Формула определения количества информации: N = 2b,
где N – мощность алфавита (количество символов),
b – количество бит (информационный вес символа).
В алфавит мощностью 256 символов можно поместить практически все необходимые символы. Такой алфавит называется достаточным.
Т.к. 256 = 28, то вес 1 символа – 8 бит.
Единице измерения 8 бит присвоили название 1 байт:
1 байт = 8 бит.
Двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
Каким же образом текстовая информация представлена в памяти компьютера?
 |
Тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные нам буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в двоичном коде. Это значит, что каждый символ представляется 8-разрядным двоичным кодом. Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер — по их коду. |
Удобство побайтового кодирования символов очевидно, поскольку байт — наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу.
Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
Таблица символов Юникода®
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
Международным стандартом для ПК стала таблица ASCII (читается аски) (Американский стандартный код для информационного обмена).
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
Порядковый номер |
Код |
Символ |
0 — 31 |
00000000 — 00011111 |
Символы с номерами от 0 до 31 принято называть управляющими. |
32 — 127 |
00100000 — 01111111 |
Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы. |
128 — 255 |
10000000 — 11111111 |
Альтернативная часть таблицы (русская). |
Первая половина таблицы кодов ASCII
 |
Обращаю ваше внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Для букв русского алфавита также соблюдается принцип последовательного кодирования.
Вторая половина таблицы кодов ASCII

К сожалению, в настоящее время существуют пять различных кодировок кириллицы (КОИ8-Р, Windows. MS-DOS, Macintosh и ISO). Из-за этого часто возникают проблемы с переносом русского текста с одного компьютера на другой, из одной программной системы в другую.
Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 («Код обмена информацией, 8-битный»). Эта кодировка применялась еще в 70-ые годы на компьютерах серии ЕС ЭВМ, а с середины 80-х стала использоваться в первых русифицированных версиях операционной системы UNIX.
От начала 90-х годов, времени господства операционной системы MS DOS, остается кодировка CP866 («CP» означает «Code Page», «кодовая страница»).
Компьютеры фирмы Apple, работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac.
Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.
Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251.
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode. Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Попробуем с помощью таблицы ASCII представить, как будут выглядеть слова в памяти компьютера.
Внутреннее представление слов в памяти компьютера
Слова |
Память |
file |
01100110011010010110110001100101 |
disk |
01100100011010010111001101101011 |
Иногда бывает так, что текст, состоящий из букв русского алфавита, полученный с другого компьютера, невозможно прочитать — на экране монитора видна какая-то «абракадабра». Это происходит оттого, что на компьютерах применяется разная кодировка символов русского языка.
назад
Кодировки символов
| Двоичный код | Десятичный код | КОИ8 | СР1251 | СР866 | Мас | ISO |
| ………….. | ||||||
| Удаление последнего символа (клавиша Backspace) | ||||||
| …………… | ||||||
| Перевод строки (клавиша Enter) | ||||||
| …………… | ||||||
| Пробел | ||||||
| ! | ||||||
| …………… | ||||||
| Z | ||||||
| …………… | ||||||
| — | Ъ | А | А | к | ||
| ………….. | ||||||
| б | В | — | — | Т | ||
| …………… | ||||||
| л | М | Ь | ||||
| ………….. | ||||||
| щ | Э | _ | Ё | н | ||
| ………….. | ||||||
| ь | я | Нераздел. пробел | Нераздел. пробел | п |
Каждая кодировка задается своей собственной кодовой таблицей. Как видно из табл. 1, одному и тому же двоичному коду в различных кодировках поставлены в соответствие различные символы.
Например, последовательность числовых кодов 221, 194, 204 в кодировке СР1251 образует слово «ЭВМ», тогда как в других кодировках это будет бессмысленный набор символов.
К счастью, в большинстве случаев пользователь не должен заботиться о перекодировках текстовых документов, так как это делают специальные программы-конверторы, встроенные в приложения.
С распространением персональных компьютеров типа IBM PC международным стандартом стала таблица кодировки под названием ASCII (American Standard Code for Information Interchange) — Американский стандартный код для информационного обмена.
Стандартными в этой таблице являются только первые 128 символов, т. е. символы с номерами от нуля (двоичный код 00000000) до 127 (01111111). Сюда входят буквы латинского алфавита, цифры, знаки препинания, скобки и некоторые другие символы. Остальные 128 кодов, начиная со 128 (двоичный код 10000000) и кончая 255 (11111111), используются для кодировки букв национальных алфавитов, символов псевдографики и научных символов (например, символы >, < или ±). В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита.
 Определение числового кода символа
Определение числового кода символа
1. Запустить текстовый редактор MS Word 2002. Ввести команду [Вставка-Символ … ]. На экране появится диалоговая панель Символ. Центральную часть диалогового окна занимает таблица символов для определенного шрифта (например, Times New Roman). Символы располагаются последовательно слева направо и построчно, начиная с символа Пробел в левом верхнем углу и заканчивая буквой «я» в правом нижнем углу таблицы.
Выбрать символ и в раскрывающемся списке из: тип кодировки.
В текстовом поле Код знака: появится его числовой код.
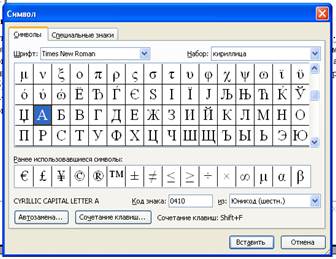 .
.
 Ввод символов по числовому коду
Ввод символов по числовому коду
1. Запустить стандартную программу Блокнот [Пуск – Программы – Стандартные — Блокнот]. С помощью дополнительной цифровой клавиатуры при нажатой клавише {Alt} ввести число 0224, отпустить клавишу {Alt}. В документе появится символ «а». Повторить процедуру для числовых кодов от 0225 до 0233. В документе появится последовательность из 12 символов «абвгдежзий» в кодировке Windows (CP1251).
2. С помощью дополнительной цифровой клавиатуры при нажатой клавише {Alt} ввести число 224, в документе появится символ «р». Повторить процедуру для числовых кодов от 225 до 233, в документе появится последовательность из 12 символов «рстуфхцчшщ» в кодировке MS-DOS (CP866).

 2.. Принцип последовательного кодирования алфавита
2.. Принцип последовательного кодирования алфавита
Принцип последовательного кодирования алфавита:в кодовой таблице ASCII латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений. Данное правило соблюдается и в других таблицах кодировки. Благодаря этому и в машинном представлении для символьной информации сохраняется понятие «алфавитный порядок».
В таблице 2 приведена стандартная часть (управляющие коды — от 00 до 31 — в данную таблицу не включены) кода ASCII. В 3-й таблице дан фрагмент альтернативной части кода ASCII, содержащий буквы русского алфавита. Здесь в первой колонке — десятичный номер символа, во второй колонке — символ, в третьей — двоичный код.
 |
Таблица 2
Таблица 3
Таблица альтернативной части кода ASCII
| А | Р |
| Б | С |
| В | Т |
| Г | У |
| Д | Ф |
| Е | Х |
| Ж | Ц |
| З | Ч |
| И | Ш |
| Й | Щ |
| К | Ъ |
| Л | Ы |
| М | Ь |
| Н | Э |
| О | Ю |
| П | Я |
 ЗНАТЬ
ЗНАТЬ
Для кодирования одного символа требуется 1 байт информации.
Таблица кодировки – это таблица, в которой устанавливается соответствие между символами и их порядковыми номерами в компьютерном алфавите.
Принцип последовательного кодирования алфавита:в кодовой таблице ASCII латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений. Данное правило соблюдается и в других таблицах кодировки. Благодаря этому и в машинном представлении для символьной информации сохраняется понятие «алфавитный порядок».
Контрольные вопросы и задания
1. Какой код используется для кодирования букв латинского алфавита буквами персонального компьютера?
2. Какие коды используются в вычислительной технике для кодирования букв русского алфавита?
12
Дата добавления: 2015-08-08; просмотров: 2099;
ПОСМОТРЕТЬ ЕЩЕ:
FILED UNDER : IT