admin / 03.08.2018
Учебник по языку SQL (DDL, DML) на примере диалекта MS SQL Server. Часть вторая / Хабр
Содержание
- Команда UPDATE
- Операторы манипулирования данными (язык DML).
- SQL – Запрос UPDATE
- 4.6.5.DML: Команды модификации данных.
- 4.6.6.DML: Выборка данных.
- 4.6.7.DML: Выборка из нескольких таблиц.
- 4.6.8.DML: Вычисления внутри SELECT.
- 4.6.9.DML: Групировка данных.
- 4.6.10.DML: Cортировка данных.
- 4.6.11.DML: Операция объединения.
- 4.6.12.Использование представлений.
- 4.6.13.Другие возможности SQL.
- SQL — запрос UPDATE
- Общее решение с динамическим SQL
- SQL UPDATE
- Частичные решения с простым SQL
- UPDATE ОПЕРАТОР
Команда UPDATE
Команда UPDATE — производит изменения в уже существующей записи или во множестве записей в таблице SQL. Изменяет существующие значения в таблице или в основной таблице представления.
Команда UPDATE Синтаксис команды

Синтаксис команды UPDATE
Команда UPDATE. Основные ключевые слова и параметры команды UPDATE
- schema — идентификатор полномочий, обычно совпадающий с именем некоторого пользователя
- table view — имя таблицы SQL, в которой изменяются данные; если определяется представление, данные изменяются в основной таблице SQL представления
- subquery_1 — подзапрос, который сервер обрабатывает тем же самым способом как представление
- сolumn — столбец таблицы SQL или представления SQL, значение которого изменяется; если столбец таблицы из предложения SET опускается, значение столбца остается неизменяемым
- expr — новое значение, назначаемое соответствующему столбцу; это выражение может содержать главные переменные и необязательные индикаторные переменные
- subquery_2 — новое значение, назначаемое соответствующему столбцу
- subquery_3 — новое значение, назначаемое соответствующему столбцу
WHERE — определяет диапазон изменяемых строк теми, для которых определенное условие является TRUE; если опускается эта фраза, модифицируются все строки в таблице или представлении.
При выдаче утверждения UPDATE включается любой UPDATE-триггер, определенный на таблице.
Подзапросы. Если предложение SET содержит подзапрос, он возвращает точно одну строку для каждой модифицируемой строки. Каждое значение в результате подзапроса назначается соответствующим столбцам списка в круглых скобках. Если подзапрос не возвращает никакие строки, столбцу назначается NULL. Подзапросы могут выбирать данные из модифицируемой таблицы. Предложение SET может совмещать выражения и подзапросы.
Команда UPDATE Пример 1
Изменение для всех покупателей рейтинга на значение, равное 200:
UPDATE Customers SET rating = 200;
Команда UPDATE Пример 2
Замена значения столбца во всех строках таблицы, как правило, используется редко. Поэтому в команде UPDATE, как и в команде DELETE, можно использовать предикат. Для выполнения указанной замены значений столбца rating, для всех покупателей, которые обслуживаются продавцом Giovanni (snum = 1003), следует ввести:
UPDATE Customers SET rating = 200 WHERE snum = 1001;
Команда SQL UPDATE Пример 3
В предложении SET можно указать любое количество значений для столбцов, разделенных запятыми:
UPDATE emp SET job = ‘MANAGER’, sal = sal + 1000, deptno = 20 WHERE ename = ‘JONES’;
Команда UPDATE Пример 4
В предложении SET можно указать значение NULL без использования какого-либо специального синтаксиса (например, такого как IS NULL). Таким образом, если нужно установить все рейтинги покупателей из Лондона (city = ‘London’) равными NULL-значению, необходимо ввести:
UPDATE Customers SET rating = NULL WHERE city = ‘London’;
Команда UPDATE Пример 5
Поясняет использование следующих синтаксических конструкций команды UPDATE:
- Обе формы предложения SET вместе в одном утверждении.
- Подзапрос.
- Предложение WHERE, ограничивающее диапазон модифицируемых строк.
UPDATE emp a SET deptno =
(SELECT deptno FROM dept WHERE loc = ‘BOSTON’), (sal, comm) = (SELECT 1.1*AVG(sal), 1.5*AVG(comm) FROM emp b WHERE a.deptno = b.deptno) WHERE deptno IN (SELECT deptno FROM dept WHERE loc = ‘DALLAS’ OR loc = ‘DETROIT’);
Вышеупомянутое утверждение UPDATE выполняет следующие операции:
- Модифицирует только тех служащих, кто работают в Dallas или Detroit
- Устанавливает значение колонки deptno для служащих из Бостона
- Устанавливает жалованье каждого служащего в 1.1 раз больше среднего жалованья всего отдела
- Устанавливает комиссионные каждого служащего в 1.5 раза больше средних комиссионных всего отдела
Операторы манипулирования данными (язык DML).
Предыдущая78910111213141516171819202122Следующая
Операторы DML работают с базой данных и используются для изменения данных и получения необходимых сведений.
SELECT – выборка строк, удовлетворяющих заданным условиям. Оператор реализует, в частности, такие операции реляционной алгебры как «селекция» и «проекция».
UPDATE – изменение значений определенных полей в строках таблицы, удовлетворяющих заданным условиям.
INSERT – вставка новых строк в таблицу.
DELETE – удаление строк таблицы, удовлетворяющих заданным условиям. Примернение этого оператора учитывает принципы поддержки целостности, поэтому он не всегда может быть выполнен корректно.
12.2 Интерактивный режим работы с SQL (интерактивный SQL)
Соответствующий режим предусматривает непосредственную работу пользователя с базой данных по следующему алгоритму: используя прикладную программу (клиентское приложение) или стандартную утилиту, входящую в СУБД, пользователь:
· устанавливает соединение с БД (подтверждая наличие прав доступа);
· вводит соответствующий оператор SQL, при необходимости в режиме диалога вводит дополнительную информацию;
· инициирует выполнение команды.
Текст запроса поступает в СУБД, которая:
· осуществляет синтаксический анализ запроса (проверяет, является ли запрос корректным);
· проверяет, имеет ли пользователь право выполнять подобный запрос (например, пользователь, у которого определены права только на чтение, пытается что-то удалить);
· выбирает, каким образом осуществлять выполнение запроса – план выполнения запроса;
· выполняет запрос;
· результат выполнения отсылает пользователю.
Схема взаимодействия пользователя и СУБД с использованием интерактивного SQL
приводится на рис. 12.1.

Рис. 12.1. Схема работы интерактивного SQL
12.3. Использование языка SQL для выбора информации из таблицы
Выборка данных осуществляется с помощью оператора SELECT, который является самым часто используемым оператором языка SQL. Синтаксис оператора SELECT имеет следующий вид:
SELECT [ALL/DISTINCT] <список атрибутов>/*
FROM <список таблиц>
[WHERE <условие выборки>]
[ORDER BY <список атрибутов>]
[GROUP BY <список атрибутов>]
[HAVING <условие>]
[UNION<выражение с оператором SELECT>]
В квадратных скобках указываются элементы, которые могут в запросе отсутствовать.
Ключевое слово ALL означает, что результатом будут все строки, удовлетворяющие условию запроса, в том числе и одинаковые строки.
DISTINCT означает, что в результирующий набор не включаются одинаковые строки. Далее идет список атрибутов исходной таблицы, которые будут включены в таблицу-результат. Символ* означает, что в таблицу-результат включаются все атрибуты исходной таблицы.
Обязательным ключевым словом является слово FROM, за ним следуют имена таблиц, к которым осуществляется запрос.
В предложении с ключевым словом WHERE задаются условия выборки строк таблицы. В таблицу-результат включаются только те строки, для которых условие, указанное в предложении WHERE, принимает значение истина.
Ключевое слово ORDER BY задает операцию упорядочения строк таблицы-результата по указанному списку атрибутов.
В предложении с ключевым словом GROUP BY задается список атрибутов группировки (разъяснение этого и последующего ключевого слова будет представлено немного позднее).
В предложении HAVING задаются условия, накладываемые на каждую группу.
Отдельно отметим, что ключевые слова FROM, WHERE ORDER BY используются аналогичным образом и в других операторах манипулирования данными языка SQL.
Рассмотрим реализацию запросов для конкретного примера, представленного в лекции 8 (см. рис.
SQL – Запрос UPDATE
8.1)
Выдать список всех студентов.
SELECT *
FROM student
или
SELECT id_st, surname
FROM student
Заметим, что если добавить к данному запросу предложение ORDER BY surname, то список будет упорядочен по фамилии. По умолчанию подразумевается, что сортировка производится по возрастанию. Если необходимо упорядочение по убыванию, после имени атрибута добавляется слово DESC.
Выдать список оценок, которые получил студент с кодом «1».
SELECT id_st, mark
FROM mark_st
Where id_st = 1
Выдать список кодов студентов, которые получили на экзаменах хотя бы одну двойку или тройку.
В предложении WHERE можно записывать выражение с использованием арифметических операторов сравнения (<, >, и т.д.) и логических операторов (AND, OR, NOT) как и в обычных языках программирования.
SELECT id_st, mark
FROM mark_st
WHERE ( MARK >= 2 ) AND ( MARK <= 3 )
Наряду с операторами сравнения и логическими операторами для составления условий в языке SQL (из-за специфики области применения) существуют ряд специальных операторов, которые, как правило, не имеют аналогов в других языках. Вот эти операторы:
IN – вхождение в некоторое множество значений;
BETWEEN – вхождение в некоторый диапазон значений;
LIKE – проверка на совпадение с образцом;
IS NULL – проверка на неопределенное значение.
Оператор IN используется для проверки вхождения в некоторое множество значений. Так, запрос
SELECT id_st, mark
FROM mark_st
WHERE mark IN (2,3)
дает тот же результат, что и вышеуказанный запрос (выведет идентификаторы всех абитуриентов, получивших хотя бы одну двойку или тройку на экзаменах).
Того же результата можно добиться, используя оператор BETWEEN:
SELECT id_st, mark
FROM mark_st
WHERE mark BETWEEN 2 AND 3
Выдать список всех студентов, фамилии которых начинаются с буквы А.
В этом случае удобно использовать оператор LIKE.
Оператор LIKE применим исключительно к символьным полям и позволяет устанавливать, соответствует ли значение поля образцу. Образец может содержать специальные символы:
_ (символ подчеркивания) – замещает любой одиночный символ;
% (знак процента) – замещает последовательность любого числа символов.
SELECT id_st, surname
FROM student
WHERE surname LIKE ‘А%’
Очень часто возникает необходимость произвести вычисление минимальных, максимальных или средних значений в столбцах. Так, например, может понадобиться вычислить средний балл. Для осуществления подобных вычислений SQL предоставляет специальные агрегатные функции:
MIN – минимальное значение в столбце;
MAX – максимальное значение в столбце;
SUM – сумма значений в столбце;
AVG – среднее значение в столбце;
COUNT – количество значений в столбце, отличных от NULL.
Следующий запрос считает среднее среди всех баллов, полученных студентами на экзаменах.
SELECT AVG(mark)
FROM mark_st
Естественно, можно использовать агрегатные функции совместно с предложением WHERE:
SELECT AVG(mark)
FROM mark_st
WHERE id_st = 100
Данный запрос вычислит средний балл студента с кодом 100 по результатам всех сданных им экзаменов.
SELECT AVG(mark)
FROM mark_st
WHERE id_ex = 10
Данный запрос вычислит средний балл студентов по результатам сдачи экзамена с кодом 10.
В дополнение к рассмотренным механизмам язык SQL предоставляет мощный аппарат для вычисления агрегатных функций не для всей таблицы результатов запроса, а для разных значений по группам. Для этого в SQL существует специальная конструкция GROUP BY, предназначенная для указания того столбца, по значениям которого будет производиться группировка. Так, например, мы можем вычислить средний балл по всем экзаменам для каждого студента. Для этого достаточно выполнить следующий запрос:
SELECT id_st, AVG(mark)
FROM mark_st
GROUP BY id_st
Все это, как обычно, может быть совмещено с предложением WHERE. При этом, не вдаваясь в тонкости выполнения запроса внутри СУБД, можно считать, что сначала выполняется выборка тех строк таблицы, которые удовлетворяют условиям из предложения WHERE, а потом производится группировка и агрегирование.
Приведем запрос, который вычисляет средний балл по оценкам, полученным на экзамене с кодом 100, для каждого студента.
SELECT id_st, AVG(mark)
FROM mark_st
WHERE id_ex = 100
GROUP BY id_st
Заметим, что группировка может производиться более чем по одному полю.
Для запросов, содержащих секцию GROUP BY существует важное ограничение: такие запросы могут включать в качестве результата столбцы, по которым производится группировка, и столбцы, которые содержат собственно результаты агрегирования.
Для того чтобы форматировать вывод, существуют различные возможности SQL. Так, например, допустимым является включение текста в запрос. Рассмотрим пример того, как это делается:
SELECT ‘Средний балл=’, AVG(mark)
FROM mark_st
WHERE id_ex = 10
В результате данного запроса пользователь увидит не просто некоторое число, а число, сопровожденное поясняющим текстом.
12.4. Использование SQL для выбора информации из нескольких таблиц
До сих пор мы рассматривали выбор информации из единственной таблицы. Можно запрашивать информацию из нескольких таблиц, реализуя описанные в соответствующем разделе учебника реляционные операции. Стоит упомянуть, что полное рассмотрение темы выходит за рамки данного учебника. Подробно этот вопрос можно изучить при помощи, например, [1, 2]. Рассмотрим некоторые примеры того, как это делается.
Как правило, в тех случаях когда возникает необходимость выбирать информацию из разных таблиц, они тем или иным образом связаны друг с другом, например отношениями один к многим или один к одному по некоторому полю.
Еще раз вернемся к примеру из лекции 8. Рассмотрим соответствующую ER-диаграмму (рис. 12.2.).
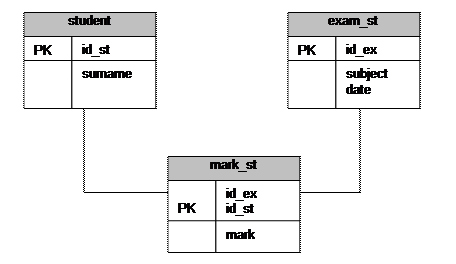
Рис. 12.2. Пример связанных таблиц
В этом примере тоже присутствуют связанные таблицы. Рассмотрим таблицы student, mark_st и exam_st.
Таблица mark_st связана с таблицей exam_st по полю id_ex.
Таблица mark_st связана с таблицей student по полю id_st.
Допустим, требуется распечатать список студентов с оценками, которые они получили на экзаменах. Для этого необходимо выполнить следующий запрос:
SELECT student.surname, mark_st.id_ex, mark_st.mark
FROM student, mark_st
WHERE student.id_st = mark_st.id_st
Отметим следующие изменения по сравнению с запросами к одной таблице.
1. В секции FROM указаны две таблицы.
2. Так как таблиц стало больше одной, появилась некоторая неоднозначность при упоминании полей. Так, во многих случаях неизвестно, из какой таблицы из списка FROM брать поле. Для устранения неоднозначности имена полей указываются с префиксом – именем таблицы. Имя таблицы от имени поля отделяется точкой.
3. В предложении WHERE указано условие соединения таблиц.
Нетрудно заметить, что использование префиксов-имен таблиц сильно загромождает запрос. Для того чтобы избежать подобного загромождения, используются псевдонимы. Так, можно переписать предыдущий запрос следующим образом:
SELECT E.surname, M.id_ex, M.mark
FROM student E, mark_st M
WHERE E.id_st = M. id_st
12.5. Использование SQL для вставки, редактирования и удаления данных
в таблицах
Для добавления данных в таблицу в стандарте SQL предусмотрена команда INSERT.
Рассмотрим ряд примеров запросов.
INSERT INTO mark_st
VALUES (1, 2, 5)
Данный запрос вставляет в таблицу mark_st строку, содержащую значения, перечисленные в списке VALUES. Если не нужно указывать значение какого-то поля, можно присвоить ему NULL:
INSERT INTO mark
VALUES (1, 2, NULL)
В случае если необходимо использование для некоторых полей значений по умолчанию, SQL позволяет явно указать, какие поля необходимо заполнить конкретными данными, а какие – значениями по умолчанию:
INSERT INTO mark_st (id_st, id_ex)
VALUES (1, 2)
Для удаления данных из таблицы существует команда DELETE:
DELETE
FROM student
Этот запрос удаляет все данные из таблицы student.
Можно ограничить диапазон удаляемой информации следующим образом:
DELETE
FROM student
WHERE surname > ‘И’
Для обновления данных используется команда UPDATE.
UPDATE mark_st
SET mark = ‘5’
WHERE id_st = 100 AND id_ex = 10
При помощи этого запроса изменится на «5» оценка у студентас кодом 100 по экзамену с кодом 10.
12.5. Язык SQL и операции реляционной алгебры
Язык SQL является средством выражения мощного математического аппарата теории множеств и реляционной алгебры. В данном разделе рассматривается связь операторов языка SQL с операциями реляционной алгебры и теории множеств.
Операция объединения
Средствами языка SQL операция объединения представляется следующим образом:
SELECT *
FROM A
UNION
SELECT *
FROM B
Операция разности
Средствами языка SQL операция разности представляется следующим образом:
SELECT *
FROM A
EXCEPT
SELECT *
FROM B
Операция проекции
SELECT Fieldi1, … , Fieldin
FROM A
Операция выборки (селекции)
SELECT *
FROM A
WHERE (<condition>)
Операция пересечения
SELECT *
FROM A
INTERSECT
SELECT *
FROM B
Предыдущая78910111213141516171819202122Следующая



4.6.5.DML: Команды модификации данных.
К этой группе относятся операторы добавления, изменения и удаления записей. INSERT INTO <имя_таблицы> [ (<имя_столбца>,<имя_столбца>,…) ] VALUES (<значение>,<значение>,..) Список столбцов в данной команде не является обязательным параметром. В этом случае должны быть указаны значения для всех полей таблицы в том порядке, как эти столбцы были перечислены в команде , например: Пример с указанием списка столбцов: UPDATE <имя_таблицы> SET <имя_столбца>=<значение>,… [WHERE <условие>] Если задано ключевое слово и условие, то команда применяется только к тем записям, для которых оно выполняется. Если условие не задано, применяется ко всем записям. Пример: В качестве условия используются логические выражения над константами и полями. В условиях допускаются:
- операции сравнения: . В SQL эти операции могут применяться не только к числовым значениям, но и к строкам (означает раньше, а позже в алфавитном порядке) и датам (раньше и позже в хронологическом порядке).
- оперции проверки поля на значение :
- операции проверки на вхождение в диапазон: и .
- операции проверки на вхождение в список: и
- операции проверки на вхождение подстроки: и
- отдельные операции соединяются связями и группируются с помощью скобок.
Подробно все эти ключевые слова будут описаны и проиллюстрированы в параграфе, посвященном оператору . Здесь мы ограничимся приведением несложного примера: Эта команда находит в таблице publishers все неопределенные значения столбца url и заменяет их строкой «url not defined». DELETE FROM <имя_таблицы> [ WHERE <условие> ] Удаляются все записи, удовлетворяющие указанному условию. Если ключевое слово и условие отстутствуют, из таблицы удаляются все записи. Пример: Эта команда удаляет запись об издательстве Super Computer Publishing.
4.6.6.DML: Выборка данных.
Для извлечения записей из таблиц в SQL определен оператор SELECT. С помощью этой команды осуществляется не только операция реляционной алгебры «выборка» (горизонтальное подмножество), но и предварительное соединение (join) двух и более таблиц. Это наиболее сложное и мощное средство SQL, полный синтаксис оператора SELECT имеет вид: SELECT [ALL | DISTINCT] <список_выбора> FROM <имя_таблицы>, … [ WHERE <условие> ] [ GROUP BY <имя_столбца>,… ] [ HAVING <условие> ] [ORDER BY <имя_столбца> [ASC | DESC],… ] Порядок предложений в операторе SELECT должен строго соблюдаться (например, должно всегда предшествовать ), иначе это приведет к появлению ошибок.
Мы начнем рассмотрение SELECT с наиболее простых его форм. Все примеры, приведенные ниже, касающиеся базы данных publications, можно выполнить самостоятельно, зайдя на эту страничку, поэтому результаты запросов здесь не приводятся.
Этот оператор всегда начинается с ключевого слова . В кострукции определяется столбец или столбцы, включаемые в результат. Он может состоять из имен одного или нескольких столбцов, или из одного символа (звездочка), определяющего все столбцы. Элементы списка разделяются запятыми.
Пример: получить список всех авторов
получить список всех полей таблицы authors: В том случае, когда нас интересуют не все записи, а только те, котрые удовлетворяют некому условию, это условие можно указать после ключевого слова .
Например, найдем все книги, опубликованные после 1996 года: Допустим теперь, что нам надо найти все публикации за интервал 1995 — 1997 гг. Это условие можно записать в виде: Другой вариант этой команды можно получить с использованием логической операции проверки на вхождение в интервал: При использовании конструкции находятся все строки, не входящие в указанный диапазон.
Еще один вариант этой команды можно построить с помощью логической операции проверки на вхождение в список:
Здесь мы задали в явном виде список интересующих нас значений. Конструкция позволяет найти строки, не удовлетворяющие условиям, перечисленным в списке.
Наиболее полно преимущества ключевого слова проявляются во вложенных запросах, также называемых подзапросами. Предположим, нам нужно найти все издания, выпущенные компанией «Oracle Press». Наименования издательских компаний содержатся в таблице publishers, названия книг в таблице titles. Ключевое слово позволяет объединить обе таблицы (без получения общего отношения) и извлечь при этом нужную информацию:
При выполнении этой команды СУБД вначале обрабатывает вложенный запрос по таблице publishers, а затем его результат передает на вход основного запроса по таблице titles.
Некоторые задачи нельзя решить с использованием только операторов сравнения. Например, мы хоти найти web-site издательтва «Wiley», но не знаем его точного наименования. Для решения этой задачи предназначено ключевое слово , его синтаксис имеет вид:
Образец заключается в кавычки и должен содержать шаблон подстроки для поиска. Обычно в шаблонах используются два символа:
- % (знак процента) — заменяет любое количество символов
- _ (подчеркивание) — заменяет одиночный символ.
Попробуем найти искомый web-site: В соотвествии с шаблоном СУБД найдет все строки включающие в себя подстроку «Wiley». Другой пример: найти все книги, название которых начинается со слова «SQL»: В том случае, когда надо найти значение, которое само содержит один из символов шаблона, используют ключевое слово и <ключевой_символ>. Литерал, следующий в шаблоне после ключевого символа, рассматривается как обычный символ, все последующие символы имеют обычное значение. Например, нам надо найти ссылку на web-страницу, о которой известно, что в ее url содержится подстрока «my_works»: В заключение заметим, что при выполнении оператора результирующее отношение может иметь несколько записей с одинаковыми значениями всех полей. Чтобы исключить повторяющиеся записи из выборки используется ключевое слово . Ключевое слово указывает, что в результат необходимо включать все строки.
4.6.7.DML: Выборка из нескольких таблиц.
Очень часто возникает ситуация, когда выборку данных надо производить из отношения, которое является результатом слияния (join) двух других отношений. Например, нам нужно получить из базы данных publications информацию о всех печатных изданиях в виде следующей таблицы: Для этого СУБД предварительно должна выполнить слияние таблиц titles и publishers, а только затем произвести выборку из полученного отношения.
Для выполнения операции такого рода в операторе после ключевого слова указывается список таблиц, по которым произвоится поиск данных. После ключевого слова указывается условие, по которому производится слияние. Для того, чтобы выполнить данный запрос, нужно дать команду:
А вот пример, где одновременно задаются условия и слияния, и выборки (результат предыдущего запроса ограничивается изданиями после 1996 года): Следует обратить внимание на то, что когда в разных таблицах присутствуют одноименные поля, то для устранения неоднозначности перед именем поля указывается имя таблицы и знак «.» (точка). (Хорошее правило: имя таблицы указывать всегда!)
Естественно, имеется возможность производить слияние и более чем двух таблиц. Например, чтобы дополнить описанную выше выборку именами авторов книг необходимо составить оператор следующего вида:
4.6.8.DML: Вычисления внутри SELECT.
позволяет выполнять различные арифметические операции над столбцами результирующего отношения. В конструкции <список_выбора> можно использовать константы, функции и их комбинации с арифметическими операциями и скобками. Например, чтобы узнать сколько лет прошло с 1992 года (год принятия стандарта SQL-92) до публикации той или иной книги можно выполнить команду: В арифметических вражения допускаются операции сложения (+), вычитания (-), деления (/), умножения (*), а также различные функции (COS, SIN, ABS — абсолютное значение и т.д.).
Также в запрос можно добавить строковую константу: В также определены так называемые агрегатные функции, которые совершают действия над совокупностью одинаковых полей в группе записей. Среди них:
- AVG(<имя поля>) — среднее по всем значениям данного поля
- COUNT(<имя поля>) или COUNT (*) — число записей
- MAX(<имя поля>) — максимальное из всех значений данного поля
- MIN(<имя поля>) — минимальное из всех значений данного поля
- SUM(<имя поля>) — сумма всех значений данного поля
Следует учитывать, что каждая агрегирующая функция возвращает единственное значение. Примеры: определить дату публикации самой «древней» книги в нашей базе данных подсчитать количество книг в нашей базе данных: Область действия данных функции можно ограничить с помощью логического условия. Например, количество книг, в названии которых есть слово «SQL»:
4.6.9.DML: Групировка данных.
Группировка данных в операторе осуществляется с помощью ключевого слова и ключевого слова , с помощью которого задаются условия разбиения записей на группы.
неразрывно связано с агрегирующими функциями, без них оно практически не используется. разделяет таблицу на группы, а агрегирующая функция вычисляет для каждой из них итоговое значение. Определим для примера количество книг каждего издательства в нашей базе данных:
Kлючевое слово работает следующим образом: сначала разбивает строки на группы, затем на полученные наборы накладываются условия . Например, устраним из предыдущего запроса те издательства, которые имеют только одну книгу: Другой вариант использования — включить в результат только те издательтва, название которых оканчивается на подстроку «Press»: В чем различие между двумя этими вариантами использования ? Во втором варианте условие отбора записей мы могли поместить в раздел ключевого слова , в первом же варианте этого сделать не удасться, поскольку не допускает использования агрегирующих функций.
4.6.10.DML: Cортировка данных.
Для сортировки данных, получаемых при помощи оператора служит ключевое слово . С его помощью можно сортировать результаты по любому столбцу или выражению, указанному в <списке_выбора>. Данные могут быть упорядочены как по возрастанию, так и по убыванию. Пример: сортировать список авторов по алфавиту: Более сложный пример: получить список авторов, отсортированный по алфавиту, и список их публикаций, причем для каждого автора список книг сортируется по времени издания в обратном порядке (т.е. сначала более «свежие» книги, затем все более «древние»): Ключевое слово задает здесь обратный порядок сортировки по полю yearpub, ключевое слов (его можно опускать) — прямой порядок сортировки по полю author.
4.6.11.DML: Операция объединения.
В SQL предусмотрена возможность выполнения операции реляционной алгебры «ОБЪЕДИНЕНИЕ» (UNION) над отношениями, являющимися результатами оператора SELECT. Естественно, эти отношения должны быть определены по одной схеме.Пример: получить все Интеренет-ссылки, хранимые в базе данных publications. Эти ссылки хранятся в таблицах publishers и wwwsites. Для того, чтобы получить их в одной таблице, мы должны построить следующие запрос:
4.6.12.Использование представлений.
До сих пор мы говорили о таблицах, которые реально хранятся в базе данных. Это, так называемые, базовые таблицы (base tables). Существует другой вид таблиц, получивший название «представления» (иногда их называют»представляемые таблицы»).
Когда содержимое базовых таблиц меняется, СУБД автоматически перевыполняет запросы, создающие view, что приводит к соответствующи изменениям в представлениях.
Представление определяется с помощью команды
CREATE VIEW <имя_представления> [<имя_столбца>,…] AS <запрос> При этом должны соблюдаться следующие ограничения:
- представление должно базироваться на единcтвенном запросе ( не допустимо)
- выходные данные запроса, формирующего представление, должны быть не упорядочены ( не допустимо)
Создадим представление, хранящее информацию об авторах, их книгах и издателях этих книг: Теперь любой пользователь, чьих прав на доступ к данному представлению достаточно, может осуществлять выборку данных из books. Например: (Права пользователей на доступ в представлениям назначаются также с помощью команд .)
Из приведенного выше примера достаточно ясен смысл использования представлений. Если запросы типа «выбрать все книги данного автора с указанием издательств» выполняются достаточно часто, то создание представляемой таблицы books значительно сократит накладные расходы на выполнение соединеия четырех базовых таблиц authors, titles, publishers и titleauthors. Кроме того, в представлении может быть представлена информация, явно не хранимая ни в одной из базовых таблиц. Например, один из столбцов представления может быть вычисляемым:
Здесь использована еще одна, ранее не описанная, возможность — присвоение новых имен столбцам представления.
В приведенном примере число изданий, осуществленных каждым издатетлем, будет хранится в столбце с именем books_count. Заметим, что если мы хотим присвоить новые имена столбцам представления, нужно указывать имена для всех столбцов. Тип данных столбца представления и его нулевой статус всегда зависят от того, как он был определен в базовой таблице (таблицах).
Запрос на выборку данных к представлению выглядит абсолютно аналогично запросу к любой другой таблице. Однако на изменение данных в представлении накладываются ограничения. Кратко о них можно сказать следующее:
- Если представление основано на одной таблице, изменения данных в нем допускаются. При этом изменяются данные в связанной с ним таблице.
- Если представление основано более чем на одной таблице, то изменения данных в нем не допускаются, т.к. в большинстве случаев СУБД не может правильно восстановить схему базовых таблиц из схемы представления.
Удаление представления производится с помощью оператора:
DROP VIEW <имя_представления>
4.6.13.Другие возможности SQL.
Описываемые ниже возможности пока не стандартизованы, но представлены в той или иной мере практически во всех современных СУБД.
- Хранимые процедуры. Практический опыт создания приложений обработки данных показывает, что ряд операций над данными, реализующих общую для всех пользователей логику и не связанных с пользовательским интерфейсом, целесообразно вынести на сервер. Однако, для написания процедур, реализующих эти операции стандартных возможностей не достаточно, поскольку здесь необходимы операторы обработки ветвлений, циклов и т.д. Поэтому многие поставщики СУБД предлагают собственные процедурные расширения (PL/SQL компании Oracle и т.д.). Эти расширения содержат логические операторы (IF … THEN … ELSE), операторы перехода по условию (SWITCH … CASE …), операторы циклов (FOR, WHILE, UNTIL) и операторы предачи управления в процедуры (CALL, RETURN). С помощью этих средств создаются функциональные модули, которые хранятся на сервере вместе с базой данных. Обычно такие модули называют хранимые процедуры. Они могут быть вызваны с передачей параметров любым пользователем, имеющим на то соотвествующие права. В некоторых системах хранимые процедуры могут быть реализованы и в виде внешних по отношению к СУБД модулей на языках общего назначения, таких как C или Pascal.
SQL — запрос UPDATE
Пример для СУБД PostgreSQL: CREATE FUNCTION <имя_функции> ([<тип_параметра1>,…<тип_параметра2>]) RETURNS <возвращаемые_типы> AS [ <SQL_оператор> | <имя_объектного_модуля> ] LANGUAGE ‘SQL’ | ‘C’ | ‘internal’ Вызов созданной функции осуществялется из оператора SELECT (также, как вызываются функции агрегирования). Более подробно о хранимых процедурах см. статью Э.Айзенберга Новый стандарт хранимых процедур в языке SQL, СУБД N 5-6, 1996 г.
- Триггеры. Для каждой таблицы может быть назначена хранимая процедура без параметров, которая вызывается при выполнении оператора модификации этой таблицы (INSERT, UPDATE, DELETE). Такие хранимые процедуры получили название триггеров. Триггеры выполняются автоматически, независимо от того, что именно является причиной модификации данных — действия человека оператора или прикладной программы. «Усредненный» синтаксис оператора создания триггера: CREATE TRIGGER <имя_триггера> ON <имя_таблицы> FOR { INSERT | UPDATE | DELETE } [, INSERT | UPDATE | DELETE ] … AS <SQL_оператор> Ключевое слово задает имя таблицы, для которой определяется триггер, ключевое слово указывает какая команда (команды) модификации данных активирует триггер. Операторы после ключевого слова описывают действия, которые выполняет триггер и условия выполнения этих действий. Здесь может быть перечислено любое число операторов , вызовов хранимых процедур и т.д. Использование триггеров очень удобно для выполнения операций контроля ограничений целостности (см. главу 4.3).
- Мониторы событий. Ряд СУБД допускает создание таких хранимых процедур, которые непрерывно сканируют одну или несколько таблиц на предмет обнаружения тех или иных событий (например, среднее значение какого-либо столбца достигает заданного предела). В случае наступления события может быть инициирован запуск триггера, хранимой процедуры, внешнего модуля и т.п. Пример: пусть наша база данных является частью автоматизированной системы управления технологическим процессом. В поле одной из таблиц заносятся показания датчика температуры, установленного на резце токарного станка. Когда это значение превышает заданный предел, запускается внешняя программа, изменяющая параметры работы станка.
Answers
Вопрос старый, но я чувствовал, что лучшего ответа пока не дали.
Есть ли синтаксис UPDATE … без указания имен столбцов ?
Общее решение с динамическим SQL
Вам не нужно знать имена столбцов, за исключением некоторых уникальных столбцов для присоединения ( в примере). Хорошо работает для любого возможного углового случая, о котором я могу думать.
Это характерно для PostgreSQL. Я создаю динамический код на основе информации_схемы , в частности, таблицы , которая определена в ANSI SQL и поддерживает большинство современных СУБД (за исключением Oracle). Но оператор с кодом PL / pgSQL, выполняющим динамический SQL, является полностью нестандартным синтаксисом PostgreSQL.
SQL UPDATE
Предполагая соответствующий столбец в для каждого столбца в , но не наоборот.
могут иметь дополнительные столбцы.
является необязательным, чтобы обновлять только выбранную строку.
SQL Fiddle.
Похожие ответы с большим количеством объяснений:
Частичные решения с простым SQL
Со списком разделяемых столбцов
Вам все равно нужно знать список имен столбцов, которые разделяют обе таблицы. С ярлыком синтаксиса для обновления нескольких столбцов — короче, чем другие ответы, предлагаемые до сих пор в любом случае.
SQL Fiddle.
Этот синтаксис был введен с Postgres 8.2 в декабре 2006 года, задолго до того, как был задан вопрос.
Более подробная информация содержится в руководстве и соответствующем ответе на dba.SE:
Со списком столбцов в
Если все столбцы определены (но не обязательно ),
и вы знаете имена столбцов (но не обязательно ).
присоединяется к строке из где все столбцы с одинаковыми именами имеют одинаковые значения. Мы не нуждаемся в обновлении в этом случае (ничего не меняется) и можем удалить эти строки в начале процесса ( ).
Нам все равно нужно найти подходящую строку, поэтому во внешнем запросе.
SQL Fiddle.
Это стандартный SQL, за исключением предложения .
Он работает независимо от того, какой из столбцов фактически присутствует в , но запрос не может отличить фактические значения NULL и отсутствующие столбцы в , поэтому он является только надежным, если все столбцы в определены .
Существует несколько возможных вариантов, в зависимости от того, что вы знаете об обеих таблицах.
У меня две таблицы:
всегда будет подмножеством (что означает, что все столбцы также находятся в ).
Я хочу обновить запись с определенным в с их данными из для всех столбцов Этот существует как в и в
Есть ли синтаксис или любой другой способ сделать это без указания имен столбцов, просто говоря «установить все столбцы A» ?
Я использую PostgreSQL, поэтому также принимается конкретная нестандартная команда (однако, не рекомендуется).
Эти понятия относятся к базам данных.
DDL — Data Definition Language. С помощью этого языка определяют данные указывая тип данных , структуры представления. Вообщем то это часть языка SQL. Но только одна. Это те операторы которые связанны с командами создания, например CREATE TABLE. Результатом выполнения этих операций заноситься в системный каталог, в котором хранятся сведения о таблицах.
DML — Data Manipulation Language. Это язык управления данными, с помощью которого можно извлекать и изменять данные. Есть две разновидности этих языков.
Procedural процедурный Non Procedural непроцедурный
Разница между ними не такая как кажется на первый взгляд. Для программиста это типа есть процедуры, нет процедур. На самом деле процедурные языки обрабатывают данные последовательно. То есть запись за записью, а непроцедурные оперируют сразу целыми наборами. И разница отсюда видна, что в процедурных языках указывается, как нужно получать данные, а в непроцедурных, что мы хотим получить. Процесс в непроцедурном языке нас не волнует и он скрыт от разработчика. Наиболее распространенный непроцедурный язык это SQL. И тут должно стать понятно, что такое, когда мы указываем не путь, а результат. Оператор SQL типа SELECT * FROM TABLE говорит о результате, который хотим. А в данном случае мы хотим получить все записи и колонки из таблицы.
UPDATE ОПЕРАТОР
Есть еще один не процедурный язык QBE. Давайте взглянем на это со стороны SQL. Итак, SQL это две части, первая часть для создание объектов в базе данных DDL, а вторая часть для манипуляции с данными в этих объектах DML. Зачем такое разделение? Проектирование базы данных задача далеко не простая и требует серьезной проработки. Есть специальные программы, которые помогают строить структуру данных, проверять связи, устранять противоречия на этапе проектирования. В результате работы этих программ формируется набор команд DDL ( в виде операторов SQL) которые запускаются на сервере баз данных и все структуры готовы к работе. Дальше начинается заполнение использую уже DML, и потом работа, опять используя DML (в виде операторов SQL).
Предыдущий Шаг | Следующий Шаг | Оглавление
Автор Каев Артем.
FILED UNDER : IT