admin / 02.03.2018
Проектирование баз данных
Содержание
Проектирование баз данных
Основные понятия о базах данных и СУБД
Информационная система (ИС) – это система, построенная на базе компьютерной техники, предназначенная для хранения, поиска, обработки и передачи значительных объемов информации, имеющая определенную практическую сферу применения.
База данных – это ИС, которая хранится в электронном виде.
База данных (БД) – организованная совокупность данных, предназначенная для длительного хранения во внешней памяти ЭВМ, постоянного обновления и использования.
БД служат для хранения и поиска большого объёма информации. Примеры баз данных: записная книжка, словари, справочники, энциклопедии и т.д.
Классификация баз данных:
1. По характеру хранимой информации:
— Фактографические – содержат краткие сведения об описываемых объектах, представленных в строго определённом формате (картотеки, н-р: БД книжного фонда библиотеки, БД кадрового состава учреждения),
— Документальные – содержат документы (информацию) самого разног типа: текстового, графического, звукового, мультимедийного (архивы, н-р: справочники, словари, БД законодательных актов в области уголовного права и др.)
2. По способу хранения данных:
— Централизованные (хранятся на одном компьютере),
— Распределенные (используются в локальных и глобальных компьютерных сетях).
3. По структуре организации данных:
— Реляционные (табличные),
— Нереляционные.
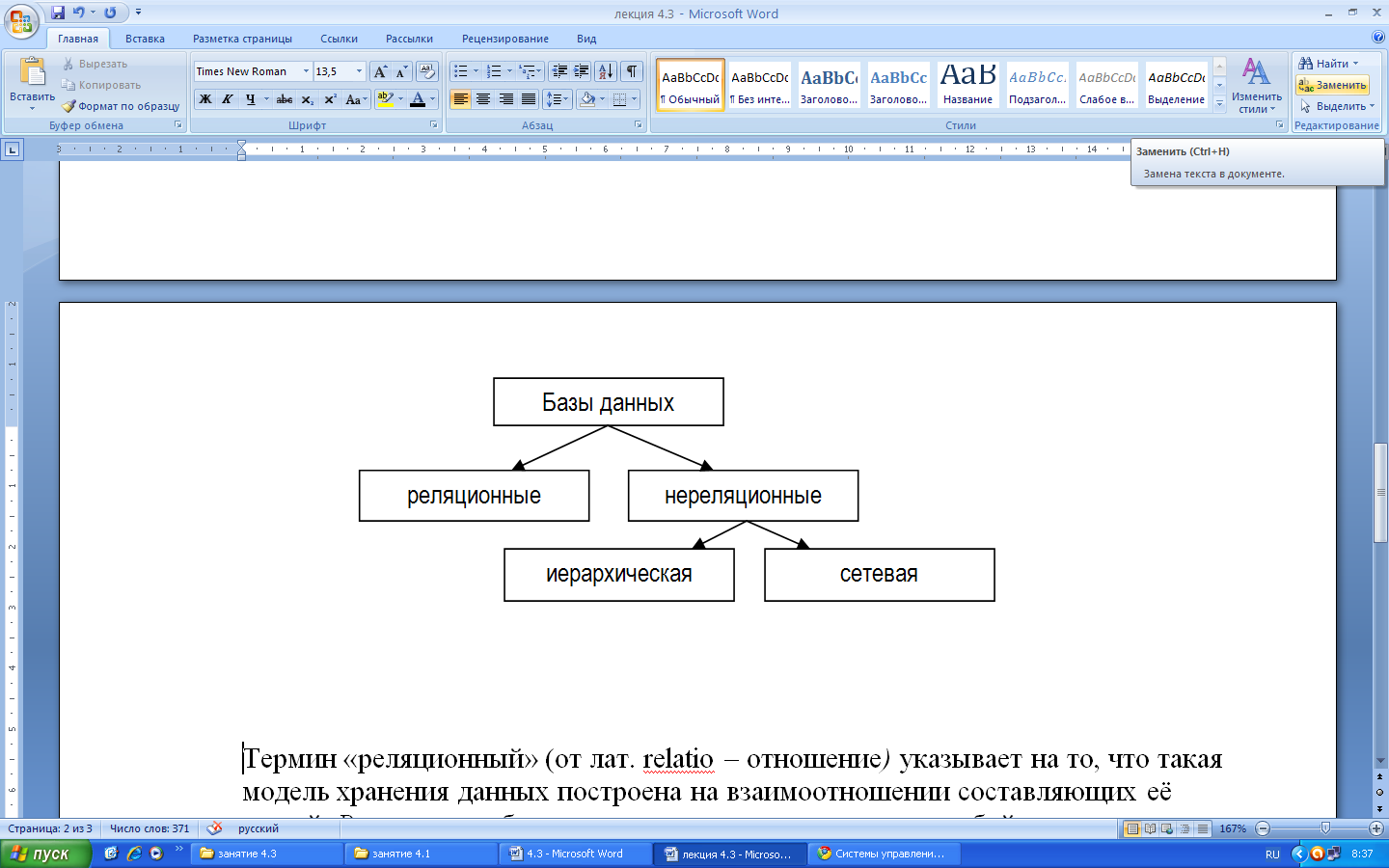
Термин «реляционный» (от лат. relatio – отношение) указывает на то, что такая модель хранения данных построена на взаимоотношении составляющих её частей. Реляционная база данных, по сути, представляет собой двумерную таблицу. Каждая строка такой таблицы называется записью. Столбцы таблицы называются полями: каждое поле характеризуется своим именем и топом данных. Поле БД – это столбец таблицы, содержащий значения определенного свойства.
Свойства реляционной модели данных:
— каждый элемент таблицы – один элемент данных;
— все поля таблицы являются однородными, т.е. имеют один тип;
— одинаковые записи в таблице отсутствуют;
— порядок записей в таблице может быть произвольным и может характеризоваться количеством полей, типом данных.
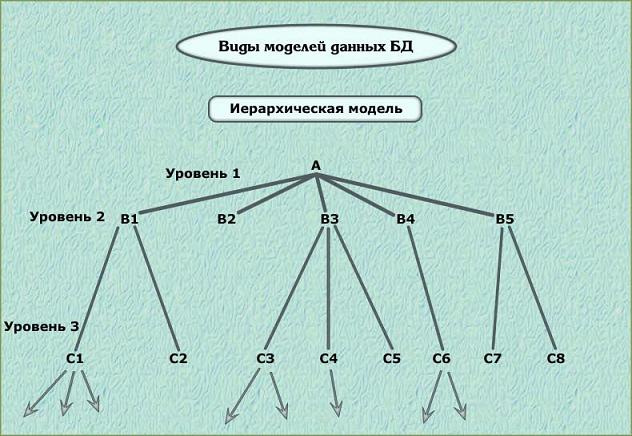
Иерархической называется БД, в которой информация упорядоченная следующим образом: один элемент считается главным, остальные – подчинёнными. В иерархической базе данных записи упорядочиваются в определенную последовательность, как ступеньки лестницы, и поиск данных может осуществляться последовательным «спуском» со ступени на ступень. Данная модель характеризуется такими параметрами, как уровни, узлы, связи. Принцип работы модели таков, что несколько узлов более низкого уровня соединяются при помощи связи с одним узлом более высокого уровня.
Узел – информационная модель элемента, находящегося на данном уровне иерархии.
Свойства иерархической модели данных:
— несколько узлов низшего уровня связано только с одним узлом высшего уровня;
— иерархическое дерево имеет только одну вершину (корень), не подчинено никакой другой вершине;
— каждый узел имеет своё имя (идентификатор);
— существует только один путь от корневой записи к более частной записи данных.
Иерархической базой данных является Каталог папок Windows, с которым можно работать, запустив Проводник. Верхний уровень занимает папка Рабочий стол. На втором уровне находятся папки Мой компьютер, Мои документы, Сетевое окружение и Корзина, которые представляют собой потомков папки Рабочий стол, будучи между собой близнецами. В свою очередь, папка Мой компьютер – предок по отношению к папкам третьего уровня, папкам дисков (Диск 3,5(А:), С:, D:, E:, F:) и системным папкам (Принтеры, Панель управления и др.).
Сетевой называется БД, в которой к вертикальным иерархическим связям добавляются горизонтальные связи. Любой объект может быть главным и подчинённым.
Сетевой базой данных фактически является Всемирная паутина глобальной компьютерной сети Интернет. Гиперссылки связывают между собой сотни миллионов документов в единую распределенную сетевую базу данных.

Программное обеспечение, предназначенное для работы с базами данных, называется система управления базами данных (СУБД). СУБД используются для упорядоченного хранения и обработки больших объемов информации.
Система управления базами данных (СУБД) – это система, обеспечивающая поиск, хранение, корректировку данных, формирование ответов на запросы. Система обеспечивает сохранность данных, их конфиденциальность, перемещение и связь с другими программными средствами.
Основные действия, которые пользователь может выполнять с помощью СУБД:
— создание структуры БД;
— заполнение БД информацией;
— изменение (редактирование) структуры и содержания БД;
— поиск информации в БД;
— сортировка данных;
— защита БД;
— проверка целостности БД.

Современные СУБД дают возможность включать в них не только текстовую и графическую информацию, но и звуковые фрагменты и даже видеоклипы.
Простота использования СУБД позволяет создавать новые базы данных, не прибегая к программированию, а пользуясь только встроенными функциями. СУБД обеспечивают правильность, полноту и непротиворечивость данных, а также удобный доступ к ним.
Популярные СУБД — FoxPro, Access for Windows, Paradox.
Таким образом, необходимо различать собственно базы данных (БД) – упорядоченные наборы данных, и системы управления базами данных (СУБД) – программы, управляющие хранением и обработкой данных. Например, приложение Access, входящее в офисный пакет программ Microsoft Office, является СУБД, позволяющей пользователю создавать и обрабатывать табличные базы данных.
Принципы построения систем управления баз данных следуют из требований, которым должна удовлетворять организация баз данных:
— Производительность и готовность. Запросы от пользователя базой данных удовлетворяются с такой скоростью, которая требуется для использования данных. Пользователь быстро получает данные всякий раз, когда они ему необходимы.
— Минимальные затраты. Низкая стоимость хранения и использования данных, минимизация затрат на внесение изменений.
— Простота и легкость использования. Пользователи могут легко узнать и понять, какие данные имеются в их распоряжении. Доступ к данным должен быть простым, исключающим возможные ошибки со стороны пользователя.
— Простота внесения изменений. База данных может увеличиваться и изменяться без нарушения имеющихся способов использования данных.
— Возможностьпоиска. Пользователь базы данных может обращаться с самыми различными запросами по поводу хранимых в ней данных. Для реализации этого служит так называемый язык запросов.
— Целостность. Современные базы данных могут содержать данные, используемые многими пользователями. Очень важно, чтобы в процессе работы элементы данных и связи между ними не нарушались. Кроме того, аппаратные ошибки и различного рода случайные сбои не должны приводить к необратимым потерям данных. Значит, система управления данными должна содержать механизм восстановления данных.
— Безопасность и секретность. Под безопасностью данных понимают защиту данных от случайного или преднамеренного доступа к ним лиц, не имеющих на это права, от неавторизированной модификации (изменения) данных или их разрушения. Секретность определяется как право отдельных лиц или организаций решать, когда, как какое количество информации может быть передано другим лицам или организациям.
Далее на примере одной из самых распространенных систем управления базами данных – Microsoft Access входит в состав популярного пакета Microsoft Office – мы познакомимся с основными типами данных, способами создания баз данных и с приемами работы с базами данных.
Проектирование баз данных
Как и любой программный продукт, база данных обладает собственным жизненным циклом (ЖЦБД). Главной составляющей в жизненном цикле БД является создание единой базы данных и программ, необходимых для ее работы.
ЖЦБД включает в себя следующие основные этапы:
1. Планирование разработки базы данных;
2. Определение требований к системе;
3. Сбор и анализ требований пользователей:
4. Проектирование базы данных:
— концептуальное проектирование базы данных – создание концептуальной модели данных, то есть информационной модели. Такая модель создаётся без ориентации на какую-либо конкретную СУБД и модель данных. Чаще всего концептуальная модель базы данных включает в себя: описание информационных объектов, или понятий предметной области и связей между ними; описание ограничений целостности, т.е. требований к допустимым значениям данных и к связям между ними;
— логическое проектирование базы данных – создание логической модели данных; создание схемы базы данных на основе конкретной модели данных, например, реляционной модели данных. Для реляционной модели данных логическая модель — набор схем отношений, обычно с указанием первичных ключей, а также «связей» между отношениями, представляющих собой внешние ключи.
Преобразование концептуальной модели в логическую модель, как правило, осуществляется по формальным правилам. Этот этап может быть в значительной степени автоматизирован.
На этапе логического проектирования учитывается специфика конкретной модели данных, но может не учитываться специфика конкретной СУБД.
— физическое проектирование базы данных – создание схемы базы данных для конкретной СУБД, создание описания СУБД. Специфика конкретной СУБД может включать в себя ограничения на именование объектов базы данных, ограничения на поддерживаемые типы данных и т.п. Кроме того, специфика конкретной СУБД при физическом проектировании включает выбор решений, связанных с физической средой хранения данных (выбор методов управления дисковой памятью, разделение БД по файлам и устройствам, методов доступа к данным, разработка средств защиты данных), создание индексов и т.д.;
5. Разработка приложений:
— проектирование транзакций (группа инструкций SQL (набор команд), исполняемых как единое целое);
— проектирование пользовательского интерфейса;
6. Реализация;
7. Загрузка данных;
8. Тестирование;
9. Эксплуатация и сопровождение:
— анализ функционирования и поддержка исходного варианта БД;
— адаптация, модернизация и поддержка переработанных вариантов.
Проектирование баз данных – процесс создания схемы базы данных и определения необходимых ограничений целостности (соответствие имеющейся в базе данных информации её внутренней логике, структуре и всем явно заданным правилам).
Основные задачи проектирования баз данных:
— Обеспечение хранения в БД всей необходимой информации.
— Обеспечение возможности получения данных по всем необходимым запросам.
— Сокращение избыточности и дублирования данных.
— Обеспечение целостности базы данных.
12345
Дата добавления: 2015-09-28; просмотров: 2397;
ПОСМОТРЕТЬ ЕЩЕ:
Этапы проектирования базы данных
Все тонкости построения информационной модели некоторой предметной области деятельности человека преследуют одну цель – получить хорошую БД. Поясним термин – хорошая БД и сформулируем требования, которым должна удовлетворять такая БД:
1. БД должна удовлетворять информационным потребностям пользователей (организаций) и по структуре и содержанию соответствовать решаемым задачам;
2. БД должна обеспечивать получение требуемых данных за приемлемое время, т.е. отвечать требованиям производительности;
3. БД должна легко расширяться при реорганизации предметной области;
4. БД должна легко изменяться при изменении программной и аппаратной среды;
5. Корректные данные, загруженные в БД, должны оставаться корректными (данные должны проверяться на корректность при их вводе).
Рассмотрим основные этапы проектирования (рис. 3.5):
Первый этап. Планирование разработки базы данных. На этом этапе выделятся наиболее эффективный способ реализации этапов жизненного цикла системы.
Второй этап. Определение требований к системе. Производится определение диапазона действий и границ приложения базы данных, а также производится сбор и анализ требований пользователей.
Третий этап. Проектирование концептуальной модели БД. Процесс создания БД начинается с определения концептуальной модели, представляющей объекты и их взаимосвязи без указания способов их физического хранения. Усилия на этом этапе должны быть направлены на структуризацию данных и выявление взаимосвязей между ними. Этот процесс можно разбить еще на несколько подэтапов:
a) Уточнение задачи. Еще перед началом работы над конкретным приложением у разработчика обычно имеются некоторые представления о том, что он будет разрабатывать. В иных случаях, когда разрабатывается небольшая персональная БД, такие представления могут быть достаточно полными. В других случаях, когда разрабатывается большая БД под заказ, таких представлений может быть очень мало, или они наверняка будут поверхностными. Сразу начинать разработку с определения таблиц, полей и связей между ними явно рановато. Такой подход может привести к полной переделке большей части приложения. Поэтому следует затратить некоторое время на составление списка всех основных задач, которые в принципе должны решаться этим приложением, включая и те, которые могут возникнуть в будущем.


Рис. 3.5. Схема проектирования БД
b) Уточнение последовательности выполнения задач. Чтобы приложение работало логично и удобно, лучше всего объединить основные задачи в группы и затем упорядочить задачи каждой группы так, чтобы они располагались в порядке их выполнения. Группировка и графическое представление последовательности их выполнения поможет определить естественный порядок выполнения задач.
c) Анализ данных. После определения списка задач необходимо для каждой задачи составить подробный перечень данных, требуемых для ее решения. После этапа анализа данных можно приступать к разработке концептуальной модели, т.е. к выделению объектов, атрибутов и связей.
Четвертый этап. Построение логической модели. Построение логической модели начинается с выбора модели данных. При выборе модели важную роль играет ее простота, наглядность и сравнение естественной структуры данных с моделью, ее представляющей. Например, если иерархическая структура присуща самим данным, то выбор иерархической модели будет предпочтительнее. Но зачастую этот выбор определяется успехом (или наличием) той или иной СУБД. То есть разработчик выбирает СУБД, а не модель данных. Таким образом, на этом этапе концептуальная модель транслируется в модель данных, совместимую с выбранной СУБД. Возможно, что отображенные в концептуальной модели взаимосвязи между объектами либо некоторые атрибуты объектов окажутся впоследствии нереализуемыми средствами выбранной СУБД. Это потребует изменения концептуальной модели. Версия концептуальной модели, которая может быть обеспечена конкретной СУБД, называется логической моделью. Иногда процесс определения концептуальной и логической моделей называется определением структуры данных.
Пятый этап.
Проектирование баз данных
Построение физической модели. Физическая модель определяет размещение данных, методы доступа и технику индексирования. На этапе физического проектирования мы привязываемся к конкретной СУБД и расписываем схему данных более детально, с указанием типов, размеров полей и ограничений. Кроме разработки таблиц и индексов, на этом этапе производится также определение основных запросов.
При построении физической модели приходится решать две взаимно противоположные по своей сути задачи. Первой из них является минимизация места хранения данных, а второй – достижение максимальной производительности, целостности и безопасности данных. Например, для обеспечения высокой скорости поиска необходимо создание индексов, причем их число будет определяться всеми возможными комбинациями полей, участвующими в поиске; для восстановления данных требуется ведения журнала всех изменений и создание резервных копий БД; для эффективной работы транзакций требуется резервирование места на диске под временные объекты и т.д., что приводит к увеличению (иногда значительному) размера БД.
Шестой этап. Оценка физической модели. На этом этапе проводится оценка эксплуатационных характеристик. Здесь можно проверить эффективность выполнения запросов, скорость поиска, правильность и удобство выполнения операций с БД, целостность данных и эффективность расхода ресурсов компьютера. При неудовлетворительных эксплуатационных характеристиках возможен возврат к пересмотру физической и логической моделей данных, выбору СУБД и типа компьютера.
Седьмой этап. Реализация БД. При удовлетворительных эксплуатационных характеристиках можно перейти к созданию макета приложения, то есть набору основных таблиц, запросов, форм и отчетов. Этот предварительный макет можно продемонстрировать перед заказчиком и получить его одобрение перед детальной реализацией приложения.
Восьмой этап. Тестирование и оптимизация. Обязательным этапом является тестирование и оптимизация разработанного приложения.
Этап девятый, заключительный. Сопровождение и эксплуатация. Так как выявить и устранить все ошибки на этапе тестирования не получается, то этап сопровождения является обычным для баз данных.
Существует два основных подхода к проектированию схемы данных: нисходящий и восходящий. При восходящем подходе работа начинается с нижнего уровня – уровня определения атрибутов, которые на основе анализа существующих между ними связей группируются в отношения, представляющие объекты, и связи между ними. Процесс нормализации таблиц для реляционной модели данных является типичным примером этого подхода. Этот подход хорошо подходит для проектирования относительно небольших БД. При увеличении числа атрибутов до нескольких сотен и даже тысяч более подходящей стратегией проектирования является нисходящий подход. Начинается этот подход с определения нескольких высокоуровневых сущностей и связей между ними. Затем эти объекты детализируются до необходимого уровня. Примером такого подхода проектирования является использование модели «сущность-связь». На практике эти подходы обычно комбинируются. В этом случае можно говорить о смешанном подходе проектирования.
Дата добавления: 2016-10-26; просмотров: 7846;
Похожие статьи:
ПРОЕКТИРОВАНИЕ РЕЛЯЦИОННОЙ БАЗЫ ДАННЫХ
⇐ ПредыдущаяСтр 4 из 12Следующая ⇒
МЕТОДОМ «СУЩНОСТЬ – СВЯЗЬ»
Существуют разные подходы к проектированию БД. Мы рассмотрим два метода проектирования: декомпозиционный и метод «сущность — связь», первым рассмотрим метод «сущность — связь».
3.1. Этапы проектирования
В БД отражается информация об определенной предметной области. Предметнойобластью называют часть реального мира, представляющую интерес для данного использования. В автоматизированных информационных системах отражение предметной области представляется моделями данных нескольких уровней (число уровней зависит от особенностей СУБД). Независимо от того, поддерживаются ли в явном виде отдельно модели логического и физического уровня, с точки зрения методологии все равно можно выделить эти уровни и соответствующие им этапы проектирова- ния БД.
Первый этап проектирования — инфологическое моделирование. Чтобы спроектировать структуру БД, необходима исходная информация о предметной области. Желательно, чтобы эта информация была представлена в формализованном виде. Описание предметной области, выполненное без ориентации на используемые в дальнейшем программные и технические средства, называется инфологическоймодельюпредметнойобласти (ИЛМ).
На втором этапе проектирования на основе инфологической модели строится даталогическаямодель БД (ДЛМ). Даталогическаямодель является моделью логического уровня и представляет собой отображение логических связей между элементами данных безотносительно к их содержанию и среде хранения. Модель строится в терминах информационных единиц, допустимых в той конкретной СУБД, в среде которой проектируется БД. Этап создания ДЛМ называется даталогическим проектированием. Описание логической структуры БД на языке СУБД называется схемой.
Третий этап проектирования состоит в привязке ДЛМ к среде хранения с помощью модели данных физического уровня (физическоймодели). Описание физической структуры БД называется схемой хранения, соответствующий этап проектирования БД – физическим проектированием.
В ряде СУБД, помимо описания общей логической структуры БД, есть возможность описать логическую структуру БД с точки зрения конкретного пользователя. Такая модель называется внешней, а ее описание называется подсхемой.
Внешняя модель не всегда является точным подмножеством схемы. Если определена подсхема, то пользователь имеет доступ только к тем данным, которые отражены в соответствующей подсхеме, что является одним из способов защиты информации от несанкционированного доступа.
Взаимосвязь этапов проектирования БД отражена на рис. 3.1.
Что такое проектирование баз данных
Из рисунка видно, что при проектировании БД возможны возвраты на предыдущие уровни. При этом есть возвраты, обусловленные необходимостью пересмотра результата проектирования, и есть возвраты, вызванные необходимостью уточнения предыдущей модели (обычно инфологической) с целью получения дополнительной информации для проектирования или при выявлении противоречий в модели.
 |
Рис. 3.1. Взаимосвязь этапов проектирования БД
3.2. Общие сведения об инфологическом моделировании
Уточним понятие ИЛМ. Для описания предметной области может использоваться и естественный язык, но его применение имеет много недостатков. Основные: громоздкость описания и неоднозначность трактовки. Поэтому для описания предметной области обычно используют искусственные формализованные языковые средства. В связи со сказанным уточним определение инфологической модели.
Инфологической моделью предметной области называют описание предметной области, выполненное с использованием специальных языковых средств и не зависящее от используемых в дальнейшем программных и технических средств.
Требования, предъявляемые к ИЛМ:
· адекватность отображения предметной области (основное требование);
· ИЛМ должна быть непротиворечивой;
· ИЛМ является конечной, но должна обладать свойством легкой расширяемости (для обеспечения ввода новых данных без изменения ранее определенных; то же самое можно сказать и об удалении данных);
· язык спецификации ИЛМ должен быть одинаково применим как при ручном, так и при автоматизированном проектировании информационных систем;
· ИЛМ должна легко восприниматься разными категориями пользователей.
Компоненты ИЛМ:
1) описание объектов и связей между ними (ER – модель);
2) описание информационных потребностей пользователей;
3) алгоритмические связи показателей;
4) лингвистические отношения;
5) ограничения целостности.
ER – модель (Е (entity) – сущность, R (relationship) – связь) является центральной компонентой ИЛМ. Вопросы ее построения подробно рассматриваются в подраз- деле 3.3.
Для описания информационных потребностей пользователей используются специальные языковые средства.
 Для отражения алгоритмических связей между показателями используются графы взаимосвязи показателей, отражающие, какие показатели служат исходными для вычисления других (рис. 3.2).
Для отражения алгоритмических связей между показателями используются графы взаимосвязи показателей, отражающие, какие показатели служат исходными для вычисления других (рис. 3.2).
Описание предметной области всегда представлено в какой-то знаковой системе. Поэтому кроме отношений, присущих предметной области, возникают еще и отношения, обусловленные особенностями отображения предметной области в языковой среде. Поэтому при построении ИЛМ должны учитываться такие лингвистические категории, как синонимия, омонимия, изоморфизм и др.
Важной компонентой ИЛМ являются ограничения целостности. Их рассмотрению посвящен восьмой раздел.
3.3. Построение ER — модели
Для описания ИЛМ используются как языки аналитического (описательного) типа, так и графические средства. Мы воспользуемся последними, как более наглядными.
В предметной области в результате ее анализа выделяют классы объектов. Классомобъектов называют совокупность объектов, обладающих одинаковым набором свойств. Например, если в качестве предметной области рассмотреть высшее учебное заведение, то в данной предметной области можно выделить следующие классы объектов: учащиеся, преподаватели, аудитории, изучаемые дисциплины.
Каждый объект в информационной системе представляется своим идентификатором, а каждый класс объектов представляется именем класса.
Каждый объект обладает определенным набором свойств. Для объектов одного класса набор этих свойств одинаков, а их значения, естественно, различаются.
Для изображения объектов и их свойств будем использовать следующие обозначения:
 |
Связь между объектом и характеризующим его свойством будем изображать в виде линии. Связь может быть различной.
Объект может обладать только одним значением какого-то свойства (например, каждый человек может иметь только одну дату рождения). Такие свойства будем называть единичными.
Для других свойств возможно существование одновременно нескольких значений у одного объекта (например, объект Сотрудники и его свойство Иностранный язык, человек может владеть несколькими иностранными языками). Такие свойства будем называть множественными.
 Для единичных свойств будем использовать одинарную стрелку: , для множественных свойств двойную: .
Для единичных свойств будем использовать одинарную стрелку: , для множественных свойств двойную: .
Некоторые свойства являются постоянными, их значения не могут измениться с течением времени (например, Дата рождения); такие свойства будем называть статическими и обозначать буквой S над соответствующей линией.
Свойства, значения которых могут изменяться со временем (например, Фамилия, Адрес, Телефон), будем называть динамическими и обозначать буквой D.
Свойство может отсутствовать у некоторых объектов одного класса (например, свойство Ученая степень, не все объекты класса Сотрудники могут обладать указанным свойством). Такие свойства будем называть условными и изображать пунктирной линией.
Существует понятие составного свойства (примеры таких свойств: Адрес, состоящий из «улицы», «дома», «квартиры»; Дата рождения, состоящая из «числа», «месяца», «года»). Для его обозначения будем использовать квадрат.
В качестве примера на рис. 3.3 приводится изображение класса объектов Сотрудники и его свойств.
 |
Рис. 3.3. Изображение класса объектов и его свойств
В ИЛМ отображаются не отдельные экземпляры объектов, а классы объектов. Когда в ИЛМ изображено обозначение объекта, то ясно, что речь идет о классе объектов, обладающих описанными свойствами. Поэтому в ИЛМ в большинстве случаев не вводят в явном виде еще и обозначение для класса объектов. Явное изображение последнего необходимо только в том случае, если в предметной области для данного класса объектов фиксируются не только характеристики, относящиеся к отдельным объектам этого класса, но и какие-то интегральные характеристики, относящиеся ко всему классу в целом. Например, если для класса объектов Сотрудники фиксируется не только возраст каждого из сотрудников, но и средний возраст всех сотрудников, то в ИЛМ необходимо отразить не только объект Сотрудник, но и класс объектов Сотрудники (рис. 3.4).
 |
Рис. 3.4. Изображение класса объектов и интегральных
характеристик класса
В инфологической модели фиксируются не только связи между объектом и его свойствами, но и связи между объектами разных классов.
Различают связи типа:
· один к одному (1:1);
· один ко многим (1:М);
· многие к одному (М:1);
· многие ко многим (М:М).
Иногда эти типы связей называют степенью связи.
Кроме степени связи, в ИЛМ для характеристики связи между разными объектами указывается класс принадлежности, который показывает, может ли отсутствовать связь объекта одного класса с каким-либо объектом другого класса. Различают обязательный и необязательный класс принадлежности. Объясним сказанное на конкретных примерах.
Пусть в ИЛМ отображается связь между двумя классами объектов: Сотрудники и Язык иностранный.
а) Предметной областью является завод, некоторые сотрудники которого знают иностранный язык, но ни один из них не владеет более чем одним языком.
Соответствующие диаграммы
ER – типов ER — экземпляров
 |
б) Предметной областью является институт, сотрудники которого обязательно должны владеть каким-либо иностранным языком, но никто не владеет более чем одним языком.
Соответствующие диаграммы
ER – типов ER – экземпляров
 |
В рассмотренных случаях между объектами наблюдается связь типа М:1; в случае а класс принадлежности является необязательным для обоих объектов; в случае б – для объекта Сотрудники класс принадлежности является обязательным, что изображается точкой в прямоугольнике.
в) Предметной областью является опять институт, некоторые сотрудники которого знают несколько иностранных языков.
Соответствующие диаграммы
ER – типов ER – экземпляров
 |
В этом случае связь между объектами имеет тип М:М.
г) Предметной областью является лингвистический институт, каждый из сотрудников которого обязательно знает несколько иностранных языков, и по каждому из языков в этом институте имеется хотя бы один специалист, владеющий им. В этом случае связь между объектами будет М:М, и класс принадлежности обоих объектов является обязательным.
Примеры возможных ситуаций можно было бы продолжить, но суть ясна.
До этого момента мы рассматривали объекты, не вникая в их сложность. На самом деле среди объектов различаются простые и сложные.
Объект называют простым, если он рассматривается как неделимый. Сложный объект представляет собой объединение других объектов, простых или сложных, также отображаемых в информационной системе.
Понятия простой и сложный являются относительными. При одном рассмотрении объект может считаться простым, а при другом этот же объект может рассматриваться как сложный. Например, объект Стул в подсистеме учета материальных ценностей будет рассматриваться как простой объект, а для предприятия, производящего стулья, это будет составной объект (включающий «ножки», «спинку», «сиденье»).
Сложные объекты подразделяют на составные, обобщенные и агрегированные.
Составной объект соответствует отображению связи «целое — часть». Примеры таких объектов: класс – ученики, группа – студенты и т.п.
Для отображения составных объектов в ИЛМ обычно не используются какие-либо специальные условные обозначения, а связь между составным и составляющими его объектами отображается так же, как это было описано выше (например, объекты Группа и Студенты связаны между собой отношением 1:М).
Обобщенный объект отражает наличие связи «род — вид» между объектами предметной области.
Например, объекты Студент, Школьник, Аспирант образуют обобщенный объект Учащиеся. Объекты, составляющие обобщенный объект, называются его категориями. Как «родовой» объект, так и «видовые» объекты могут обладать определенным набором свойств. Причем «видовые» объекты обладают всеми теми свойствами, которыми обладает «родовой» объект, плюс свойствами, присущими только объектам этого вида.
Определение родо-видовых связей означает классификацию объектов предметной области по тем или иным признакам. Подклассы могут выделяться в ИЛМ в явном виде (рис. 3.5).
 |
Рис. 3.5. Изображение обобщенного объекта
На рис. 3.5 изображен фрагмент ИЛМ, отражающий обобщенный объект Кадры для высшего учебного заведения. Для обобщенного объекта выделено две категории: Сотрудник и Учащийся. Для обозначения подкласса в схеме использован треугольник. Естественно, что классификация может быть многоуровневой. В рассматриваемом примере подкласс Сотрудник, в свою очередь, может быть классифицирован на Преподаватель и Администрация; Учащийся на Студент и Аспирант.
Агрегированный объект соответствует обычно какому-либо процессу, в который оказываются «вовлеченными» другие объекты. Например, агрегированный объект Поставка (рис. 3.6) объединяет в себе объекты Поставщик, Получатель, Продукт и Дата. Для отображения агрегированного объекта в схеме использован ромб.
Агрегированный объект может так же, как и простой объект, иметь характеризующие его свойства. В рассматриваемом примере таким свойством является Размер поставки.
 |
Рис. 3.6. Изображение агрегированного объекта
⇐ Предыдущая12345678910Следующая ⇒
Читайте также:
Руководство пользователя о данном руководстве
1 2 3 4 5 6 7 8 9 … 23
Запуск программы PS AdminПри использовании Windows 95 или Windows NT 4.0 (или боле поздних версий Windows) для запуска программы PS Admin необходимо:
Для Windows 3.1, Windows for Workgroups 3.1x или Windows NT 3.51 последовательность следующая:
Программа PS Admin после этого готова к работе. Пример вида PS Admin экрана показан ниже:
Инструкции по использованию PS Admin для осуществления начальной установки принт-серверов D-Link находится в следующем разделе «Начальная установка принт-сервера». Более подробная информация о возможности использования PS Admin для администрирования других типов принт-серверов находится в разделе Программа управления PS Admin.
|

 Начальная установка принт-сервера
Начальная установка принт-сервера
1 2 3 4 5 6 7 8 9 … 23
Похожие:
 |
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
rykovodstvo.ru
FILED UNDER : IT