admin / 29.06.2018
Объединение серверов в кластер
Содержание
- Кластер серверов
- Основные возможности кластера серверов
- Общая схема клиент-серверного варианта работы
- Состав простейшего кластера серверов
- Масштабируемость кластера серверов
- Работа кластера серверов под управлением различных операционных систем
- Утилита администрирования кластера серверов
- Создание виртуализированных отказоустойчивых кластеров
- Кластер серверов
- Объединение серверов в кластеры
- Кластер (группа компьютеров)
- Объединение серверов в кластеры
Кластер серверов
Кластер серверов 1С:Предприятия 8 является логическим понятием и представляет собой множество рабочих процессов, обслуживающих один и тот же набор информационных баз.
 Основные возможности кластера серверов
Основные возможности кластера серверов
- кластер серверов может функционировать на одном или нескольких компьютерах (рабочих серверах);
- на каждом рабочем сервере может функционировать один или несколько рабочих процессов, обслуживающих клиентские соединения в рамках данного кластера;
- подключение новых клиентов к рабочим процессам кластера выполняется на основе анализа долгосрочной статистики загруженности рабочих процессов;
- взаимодействие процессов кластера с клиентскими приложениями, между собой и с сервером баз данных осуществляется по протоколу TCP/IP;
- процессы кластера сервера могут быть запущены как приложение, или как сервис.
Общая схема клиент-серверного варианта работы
В клиент-серверном варианте работы клиентское приложение взаимодействует с кластером серверов, который, в свою очередь, осуществляет взаимодействие с сервером баз данных.
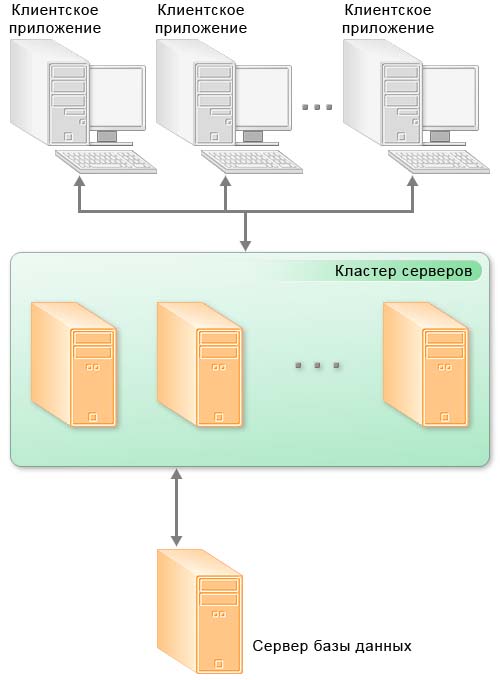
Один из компьютеров, входящих в состав кластера серверов, является центральным сервером кластера. Центральный сервер, помимо обслуживания клиентских соединений, управляет работой всего кластера и хранит реестр кластера.
Для клиентского соединения кластер адресуется по имени центрального сервера и номеру IP порта. Если используется стандартный IP порт, то достаточно указания одного имени центрального сервера.
При установке соединения клиентское приложение обращается к центральному серверу кластера. Центральный сервер, на основе анализа статистики загруженности рабочих процессов, направляет клиентское приложение к конкретному рабочему процессу, который будет его обслуживать. Этот процесс может находиться как на центральном сервере, так и на любом рабочем сервере кластера.
Рабочий процесс выполняет аутентификацию пользователя и обслуживает соединение до окончания сеанса работы клиента с данной информационной базой.
Состав простейшего кластера серверов
Простейший кластер серверов может располагаться на одном компьютере и содержать один рабочий процесс:
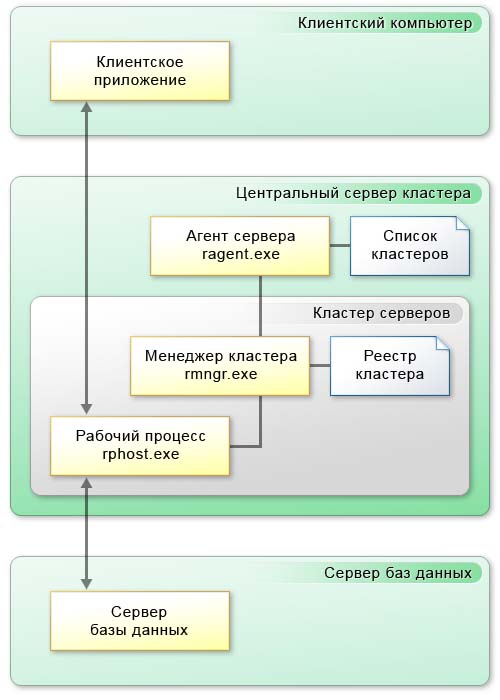
На рисунке представлены все элементы, которые задействованы в работе кластера серверов, а именно:
- процессы кластера серверов:
- ragent.exe;
- rmngr.exe;
- rphost.exe;
- хранилища данных:
- список кластеров;
- реестр кластера.
Функционирование компьютера в составе кластера обеспечивается процессом ragent.exe, который называется агентом сервера. Соответственно компьютер, на котором запущен агент сервера, называется рабочим сервером. Одной из функций агента сервера является ведение списка кластеров, расположенных на данном рабочем сервере.
Агент сервера и список кластеров не входят в состав кластера серверов, а лишь обеспечивают работу сервера и кластеров, которые расположены на нем.
Непосредственно кластер серверов включает в себя следующие элементы:
- процесс rmngr.exe;
- реестр кластера;
- один или несколько процессов rphost.exe.
Процесс rmngr.exe называется менеджером кластера. Этот процесс управляет функционированием всего кластера. В составе кластера этот процесс всегда существует в единственном экземпляре. Рабочий сервер, на котором функционирует менеджер кластера и располагается реестр кластера, называется центральным сервером кластера. Одной из функций менеджера кластера является ведение реестра кластера.
Процесс rphost.exe называется рабочим процессом. Рабочий процесс обслуживает непосредственно клиентские приложения, взаимодействует с сервером баз данных и в нем, в частности, могут исполняться процедуры серверных модулей конфигурации.
Масштабируемость кластера серверов
Масштабируемость кластера серверов может осуществляться несколькими способами:
- за счет увеличения количества рабочих процессов, функционирующих на конкретном рабочем сервере;
- за счет увеличения количества рабочих серверов, входящих в состав кластера.
Использование нескольких рабочих процессов, с одной стороны, позволяет снизить нагрузку на каждый конкретный рабочий процесс. С другой стороны, запуск нескольких рабочих процессов позволяет более эффективно использовать аппаратные ресурсы рабочего сервера. Кроме этого запуск нескольких рабочих процессов позволяет повысить надежность сервера, изолировав группы клиентов, работающих с разными информационными базами.
Увеличение количества рабочих серверов, входящих в кластер, позволяет использовать большее количество рабочих процессов (обслуживать большее количество клиентских соединений), не увеличивая при этом нагрузку на каждый конкретный рабочий процесс.
Работа кластера серверов под управлением различных операционных систем
Все процессы кластера серверов способны функционировать как под управлением операционной системы Windows, так и под управлением операционной системы Linux. Благодаря тому, что взаимодействие процессов между собой осуществляется по протоколу TCP/IP, в составе одного кластера могут присутствовать рабочие серверы с различными операционными системами. Подробнее…
Утилита администрирования кластера серверов
В поставку системы входит утилита администрирования клиент-серверного варианта работы, позволяющая изменять состав кластера, управлять информационными базами, подключением пользователей, а также выполнять оперативный анализ транзакционных болокировок. Подробнее…
Главная / Корпоративный отдел
Создание виртуализированных отказоустойчивых кластеров
Основные технические решения
Основываясь на анализе поставленной задачи и выбранной заказчиками концепции построения серверного узла системы с использованием виртуализации и современных высокоэффективных технологиях и разработках компаний — производителей, в составе решения предлагается рассматривать следующие элементы:
- Отказоустойчивая виртуализация серверов с использованием кластера из 2 узлов
- Хранение виртуальных машин на общей внешней отказоустойчивой системе хранения данных
- Использование ПО WMware vSphere для управления кластером и виртуальными машинами и обеспечения высокой доступности и производительности
Дополнительно
2. Предлагаемое решение
Виртуализация серверов обеспечивает создание среды отдельной ОС (VOS – Virtual Operation System environment), которая логически изолирована от среды физического сервера (POS – Physical Operation System environment). Это дает повышенную эффективность использования ресурсов (оборудование, электропитания и охлаждение, пространство размещения) путем запуска нескольких VOS на одном сервере, а также обеспечивает изоляцию сервисов и повышает безопасность.
Использование виртуализации серверов позволяет выполнить поставленные требования и получить следующие преимущества:
- Обеспечить надежное функционирование сервисов и приложений путем кластеризации
- Обеспечить широкие возможности администрирования и мониторинга состояния серверов
- Повысить эффективность использования оборудования путем консолидации серверов
- Снизить затраты на электропитание, охлаждение, помещение
- Обеспечит непрерывное функционирование сервисов и приложений при техническом обслуживании серверов
- Использовать шаблоны виртуальных машин для быстрого развертывания новых серверов
- Обеспечить надежное резервное копирование и восстановление виртуальных серверов
Структурная схема кластера виртуализации с 2 узлами:

Кластер строится по классической схеме из 2 или более узлов с использованием разделяемого внешнего хранилища, что позволяет построить систему высокой доступности и обеспечивает консолидацию различных операционных систем и сервисов в рамках одного кластера. Для обеспечения централизованного управления необходимо наличие управляющего сервера с установленным ПО управления кластером. Кластерная система хранения может быть подключена по любой совместимой с ПО кластеризации технологии (FC, iSCSI, SAS).
Для обеспечения отказоустойчивости в кластере используется служба ПО VMware vSphere — VMware High Availability (HA). VMware HA обеспечивает высокий уровень доступности всей виртуальной ИТ-среды без затрат и сложностей, свойственных традиционным кластерным решениям. VMware HA при минимальных затратах обеспечивает высокий уровень доступности любого приложения, выполняющегося в виртуальной машине, вне зависимости от используемой операционной системы и конфигурации оборудования. Благодаря VMware HA не требуется выделенное оборудование, работающее в режиме ожидания, и дополнительное программное обеспечение. С помощью VMware HA возможно обеспечить отказоустойчивость приложений и сервисов, кластеризация которых традиционными средствами невозможна. Кластер VMware HA представляет собой пул ресурсов, созданный из физических серверов. Файлы виртуальных машин и данные приложений хранятся на системе хранения данных, к которой имеют доступ все серверы кластера. VMware HA осуществляет непрерывный мониторинг всех физических серверов кластера и перезапускает виртуальные машины в случае сбоя сервера.
Кластер серверов
Перезапуск виртуальных машин осуществляется практически немедленно без человеческого вмешательства на другом физическом сервере того же ресурсного пула.

Рисунок 1.
Схема работы VMwareHA
Кластер VMware HA может быть построен, как в пределах одного Центра Обработки Данных (ЦОД), так и между основным и резервным центрами обработки данных. Производительность кластера может быть увеличена, как путем установки дополнительных процессоров, расширения памяти в серверах, так и путем установки дополнительных серверов. Дисковое пространство может быть увеличено без остановки работы кластера путем добавления дополнительных жестких дисков в систему хранения данных.
Управление кластером VMware HA осуществляется с помощью сервера управления VMware vCentre Server.
VMware vCenter Server обеспечивает унифицированное управление всеми узлами и виртуальными машинами центра обработки данных из одной консоли. vCenter Server дает возможность улучшить контроль, упростить выполнение повседневных задач, а также снизить сложность и стоимость управления ИТ-инфраструктурой. VMware vCentre Server допускает установку на одну из виртуальных машин кластера, при значительном количестве узлов в кластере его рекомендуется устанавливать на физическую машину, например из числа уже имеющихся в компании физических серверов. Выделенного физического сервера VirtualCenter Management Server (VC) не требуется, функции сервера управления виртуальными машинами могут быть совмещены с другими ролями, выполняемыми сервером.

Рисунок 2. Сервер управления виртуальными машинами VMware vCenter Server
4. Состав решения
В зависимости от задачи , поставленной заказчиком используется соответствующее оборудование Мы отдаем предпочтение решениям на базе процессоров Intel® Xeon®:
- Гипервизор VMware ESXi
- Кластерная файловая система VMware vStorage VMFS
- Поддержка четырехпроцессорного виртуального ЦПУ vSMP для виртуальных машин
- Агент мониторинга и управления VMware vCenter Server Agent
- Технологию VMware Thin Provisioning, обеспечивающую оптимальное использование дискового пространства вашими виртуальными машинами
- VMware vStorage APIs / VMware Consolidated Backup, предоставляющие возможности по централизованному копированию виртуальных машин
- Менеджер обновлений хостов и виртуальных машин VMware vCenter Update Manager
- Единый центр управления VMware vCenter Server for Essentials, ограниченный тремя физическими хостами (до 2 6-ядерных процессоров на хосте)
- Технологию VMware HA, предоставляющую кластерную отказоустойчивость для любых виртуальных машин. Виртуальная машина автоматически перезапускается в случае отказа гостевой операционной системы или физического хоста
- Продукт VMware Data Recovery, предоставляющий графический интерфейс резервного копирования и восстановления виртуальных машин
При необходимости расширения может быть произведено обновление редакции пакета на версию с большим количеством хостов и расширенным функционалом.
Объединение серверов в кластеры
Кластер – это группа компьютеров, которые работают вместе и составляют единый унифицированный вычислительный ресурс. Хотя кластер и состоит из множества машин, операционных систем и приложений, пользователи «видят» его как одну систему. Объединение в кластеры позволяет создавать высокопроизводительные и надежные системы с использованием стандартных структурных компонентов.
Возникновение кластеров было обусловлено ростом популярности интернета – стандартные серверные процессоры и системы, рассчитанные на обработку больших объемов данных, начали использоваться для обслуживания внешних приложений (хотя каждая система, как правило, управлялась отдельно, имела собственную операционную систему и прикладное ПО), что обеспечивало более высокую надежность.
Разработка кластерных версий основных приложений уровня предприятия (таких как Oracle 9i с Real Application Clusters (RAC)) и компонентного программного обеспечения (такого как виртуальная машина Java J2EE), позволяющих распределять ПО между несколькими серверами, способствовала повышению интенсивности использования кластеров на уровне предприятия.
В результате кластеры на базе процессоров Intel начали вытеснять мейнфреймы и большие многопроцессорные серверы в качестве средства обслуживания внутренних приложений благодаря более эффективному соотношению «цена – качество», а также лучшим показателям масштабируемости и готовности.
Для корпорации Intel это означает, что процессоры на базе архитектуры Intel будут все шире использоваться для обслуживания приложений в вычислительных центрах, что до недавнего времени оставалось прерогативой мейнфреймов и больших многопроцессорных RISC-серверов.
Объединение в кластеры начинает практиковаться и в сфере высокопроизводительных вычислений. Высокоскоростные межкомпонентные соединения в сочетании с двухпроцессорными системами, обладающими прекрасными показателями производительности при выполнении операций с целыми числами и плавающей запятой, делают возможным создание очень больших кластеров для решения таких задач, как моделирование катастроф, вычисления в области гидроаэродинамики и финансовое моделирование. Ряд коммерческих и научных организаций (таких как CERN и TeraGrid) уже используют кластеры из двухпроцессорных серверов на базе процессора Intel Itanium 2 для решения задач, требующих высокой производительности.
Следующий этап развития высокопроизводительных вычислений – так называемые матричные вычисления. Эта технология позволяет объединять свободные ресурсы процессора и устройств хранения данных и использовать их совместно в глобальной сети серверов, обеспечивая распределенную параллельную обработку данных.
Объединение в кластеры – путь в вычислительные центры
Технология объединения в кластеры применяется уже более 20 лет.
Кластер (группа компьютеров)
Традиционно она использовалась для обеспечения надежности, готовности, удобства в обслуживании, эксплуатации и управлении – за счет таких функций, как горячее резервирование и переключение при отказе. Хотя эта технология и позволяла повысить надежность и готовность малых систем до уровня больших систем, весь потенциал производительности таких кластеров из-за ограничений программного обеспечения реализовать все равно было невозможно.
Особенно популярно объединение в кластеры тех серверов, которые обслуживают внешние приложения (web-серверы, межсетевые защитные экраны и прокси-серверы), а в последнее время – и серверов среднего уровня (обслуживающих приложения для бизнеса).
Научные организации – например, CERN (Европейский центр ядерных исследований), который переводит крупный кластер рабочих станций на базе процессоров Intel Xeon на процессоры Intel Itanium, уже давно использует кластеры для выполнения самых сложных научных расчетов.
Новая же тенденция заключается в том, что благодаря эффективному соотношению «цена – производительность» систем на базе процессоров семейств Intel Xeon и Intel Itanium коммерческие предприятия начинают менять большие компьютеры-мейнфреймы и крупные единые многопроцессорные системы, обслуживающие корпоративные базы данных, на кластеры из высокопроизводительных компьютеров на базе процессоров Intel. Распространению технологии объединения в кластеры в среде внутренних вычислений способствует применение таких приложений, как Oracle 9i с Real Application Clusters, оптимизированных под архитектуру Intel.
Объединение серверов в кластеры имеет следующие преимущества:
- стоимость – серверы на базе архитектуры Intel, ставшей отраслевым стандартом, предлагают лучшее соотношение «цена – производительность» по сравнению с серверами на базе архитектуры RISC и мейнфреймами;
- готовность – кластеры не имеют единой «точки выхода из строя», таким образом, поломка любого сервера или его компонента не приведет к прекращению обслуживания конечного пользователя;
- масштабируемость – многие современные кластеры построены на основе стандартных структурных компонентов, рассчитанных на обработку больших объемов данных, что делает наращивание ресурсов по мере необходимости сравнительно простым и экономически эффективным.
Объединение серверов в кластеры является ключевой областью применения архитектуры Intel и прекрасным примером того, как продукция для обработки больших объемов данных, основанная на отраслевых стандартах (например, процессорах семейств Intel Xeon и Intel Itanium), может оказаться в сердце решений самых сложных вычислительных проблем.
Типы объединения в кластеры для внутренних приложений
Существует две модели объединения в кластеры, каждая из которых имеет свои преимущества и недостатки.
- «С совместным использованием диска» – все серверы в кластере используют одно устройство (массив) хранения данных.
Преимущество этой модели заключается в возможности переключения при отказе, так как все серверы используют одинаковые данные; недостаток состоит в том, что, например, при обслуживании большой базы данных обмен информацией между компьютерами в кластере (по мере того, как они «обновляют» друг друга) может негативно повлиять на производительность. Устранить этот недостаток позволяет использование таких инструментальных средств, как Oracle Cache Fusion, которое входит в состав Oracle 9i RAC.
- «Без совместного использования» – все серверы абсолютно независимы друг от друга и сами управляют своими периферийными устройствами. В случае сбоя данные перераспределяются на другие серверы. Эта модель дает широкие возможности для масштабирования и предполагает минимум «служебного» трафика между серверами, но в то же время может налагать определенные ограничения на устройство базы данных.
Корпорация Intel и будущее технологии объединения в кластеры
В одном из отчетов компании Meta Group говорится: «В течение ближайших пяти лет организации, связанные с информационными технологиями, все чаще будут использовать решения для управления базами данных на основе кластерных архитектур, стремясь снизить стоимость инфраструктуры и повысить степень доступности приложений».
Руководители отделов информационных технологий все чаще будут задаваться вопросом: «Почему мы не объединяем наши системы в кластеры?» Преимущество в стоимости уже сейчас слишком привлекательно, чтобы его игнорировать. А с учетом того, что все крупнейшие разработчики баз данных уже создают версии своего программного обеспечения для процессоров семейства Intel Itanium, показатели производительности станут еще более высокими. Кроме того, такие новые технологии ввода-вывода, как Infiniband, будут также способствовать увеличению скорости межузлового обмена данными внутри кластеров.
Дата публикации:
7 октября 2004 года
Объединение серверов в кластеры
На ноде proxmox имеем интерфейс eth0, который подключен к физическому порту коммутатора.
192.168.1.1 — gateway
192.168.1.100 — proxmox (нода)
192.168.1.102 — VPS
Необходимо создать сетевой мост vmbr0.
Мост является виртуальной реализацией физического коммутатора. Виртуальные машины подключаются к мосту как подключаются компьютеры кабелем к обычному коммутатору.
Все подключенные виртуальные машины к сетевому мосту могут обмениваться между собой данными.
Если мост подключен к физическому интерфейсу — виртуальные машины могут обмениваться данными с внешними сетевыми устройствами.

Чтобы виртуальные машины имели доступ во внешнюю физическую сеть (eth0) делаем следующее:
- В web интерфейсе выбираем нужную ноду (в категории Датацентр), выбираем System-Сеть.
- Создать — Linux Bridge
- Заполняем параметры:
— имя (например vmbr0)
— ip адрес (192.168.1.101)
— маска подсети (255.255.255.0)
— Bridge ports (eth0)
Видим такую картину:

В настройках сети виртуальной машины задаем настройки:
- Bridge (vmbr0)
- IPv4 (DHCP если IP выдаются автоматически в сети, либо Static. Пример: IPv4/CIDR 192.168.1.102/24 и gateway 192.168.1.1)

Более подробные инструкции можно посмотреть на этой странице
Tags:network, proxmox
FILED UNDER : IT