admin / 28.09.2018
Кодировка в командной строке
.
| RomaH
23.01.07 — 14:41 |
Еще в четверг с успехом пользовал такой cmd файл: сегодня при выполнении в окне консоли все русские буквы отображаются … (в общем — не правильно они отображаются) вернее 1с говорит что такой базы нет — хотите новую? что случилось и как исправить ?  |
| ul_tim
1 — 23.01.07 — 14:57 |
напиши в начале cmd файла |
| RomaH
2 — 23.01.07 — 14:58 |
а без этого ? |
| RomaH
3 — 23.01.07 — 15:00 |
chcp 1251 /ConfigurationRepositoryNЛобанов /ConfigurationRepositoryP1 ну типа — не помогло |
| ul_tim
4 — 23.01.07 — 15:17 |
файл должен быть сохранен в формате ANSI, |
| RomaH
5 — 23.01.07 — 15:18 |
вопрос в том что в четверг я это дело запускал — и все работало |
| RomaH
6 — 23.01.07 — 15:20 |
как из блокнота сохранить не ANSI ? |
| ul_tim
7 — 23.01.07 — 15:31 |
там есть кодировка внизу можно выбрать другую |
| ul_tim
8 — 23.01.07 — 15:33 |
может действительно там базы нет? пользователя, пароль путь проверял? |
| Ковычки
9 — 24.01.07 — 06:04 |
Вы че пытаетесь в кмд в 1251 работать ? Не корректно отображается Русский текст в CMD? Решение есть!только в 866 или утф-16 (но это отдельный разговор) |
| RomaH
10 — 24.01.07 — 07:23 |
(9) я не только пытался, но и работал |
| bse
11 — 24.01.07 — 08:09 |
(7) и это в каком-же блокноте ты нашел смену кодировки??? |
| ul_tim
12 — 24.01.07 — 08:38 |
winXP sp2 да и в Win 2003, 2000 тоже есть обычный блокнот внизу выбор кодировок, |
| DSatan
13 — 24.01.07 — 14:19 |
(12) тебя обманули — это не Блокнот 🙂 |
| Ковычки
14 — 24.01.07 — 15:00 |
(12) неужто пакетники в 1251 ? канечно можно, но не смаху… |

Наведи порядок в своей работе используя конфигурацию 1C "Управление IT-отделом 8"
ВНИМАНИЕ! Если вы потеряли окно ввода сообщения, нажмите Ctrl-F5 или Ctrl-R или кнопку «Обновить» в браузере.
Ветка сдана в архив. Добавление сообщений невозможно.
Но вы можете создать новую ветку и вам обязательно ответят!
Каждый час на Волшебном форуме бывает более 2000 человек.
Как поменять кодировку в Денвере.

При работе с локальным сервером (установленном на своем компьютере), возникает проблемма с кодировкой страниц. Сам Денвер по умолчанию, запрограммирован обычно под windows 1251, может быть и другая кодировка, что в данном случае не столь важно, а при верстке сайта, рекомендовано устанавливать кодировку charset=utf-8, особенно при разработке сайтов на PHP и в результате в окне браузера можно будет увидеть очень веселую кряко-абра-кадабру. Но такая проблемма решается очень просто. Я покажу на основе своего Денвера, а отличия могут быть не значительные и легко находимы.
Путь для смены кодировки на локальном сервере:
Z -> usr -> local -> apache -> conf -> httpd.conf:
- заходим в диск Z и открываем папку usr
- в папке usr открываем папку local
- дальше нужно открыть папку apache и в ней открыть папку conf.
- в папке conf найти файл httpd.conf и открыть его программой Блокнот.
- найти строку AddDefaultCharset windows-1251 и изменить, например на AddDefaultCharset utf-8.

После перезагрузки Денвера и очистки кэша браузера, все будет работать как вам нужно.
Можно сделать еще по-другому. Найти в том-же файле httpd.conf строку с установкой кодировки,
и закомментировать — #AddDefaultCharset windows-1251,
тогда будут действовать установки сайта, прописанные в
< meta http-equiv=»content-type» content=»text/html; charset=utf-8″ /> ,
что бывает очень удобно.
Сбилась кодировка в командной строке. Как исправить
Я так делаю и вам советую.
копирование со ссылкой на источник. 1 07 2011
Поделитесь ссылкой на статью…
Всего комментариев — 6. Можете оставить свой комментарий.
arc 2012-09-20 07:06:33 сайт автора —
Спасибо за пояснения по денверу не мог кодировку исправить
Alex 2012-09-22 12:41:26 сайт автора —
В первом случае кракозябры вылазят при запуске локалхоста
figaro 2013-05-27 05:35:41 сайт автора — http://html.svoymaster.com
Спасибо за статью, очень помогла…а то пол дня потратил на разбирание кодировок сайта!
vliga 2013-06-11 12:09:50 сайт автора —
Спасибо, помогло
Max 2013-10-12 18:27:04 сайт автора — maxcentral.ru
Помогло! Спасибо!
ivan 2013-11-29 12:16:36 сайт автора —
СПАСИБО! ПОМОГЛО))))
Иногда по неизвестным причинам некоторые команды русскоязычной версии Windows выводят русский текст в нечитаемой кодировке, кракозябрами.
Например, команда help выводит нормальный текст:
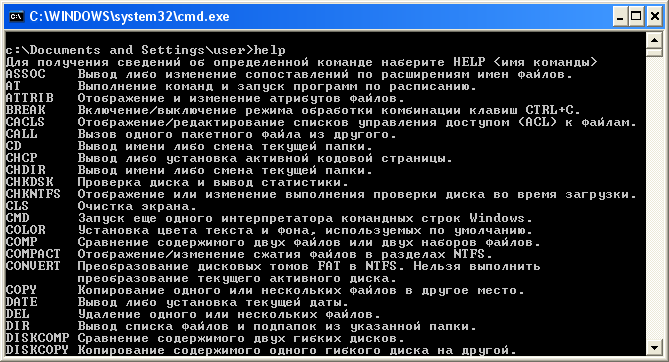
Но при этом подсказка telnet выводит в ответ кракозябры.
Так может происходить, к примеру, если текущая кодировка консоли 866, а утилита telnet.exe почему-то выводит текст в кодировке 1251.
Кракозябры в командной строке cmd. Проблемы с кодировкой cmd.exe
Вывести текст в нужной кодировке поможет команда chcp, которая устанавливает нужную кодировку.
Вот так можно посмотреть текущую кодировку консоли:
А вот так можно поменять кодировку на 1251, после чего вывод подсказки telnet будет отображаться нормально:
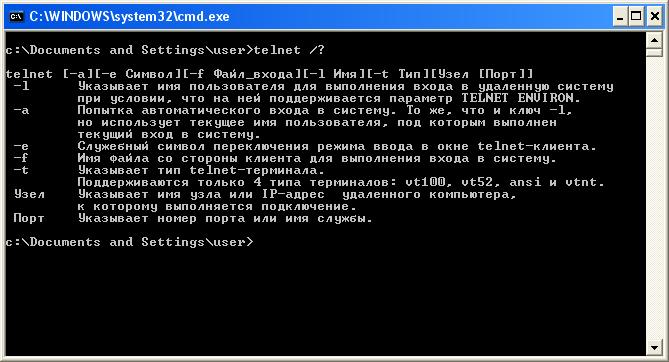
К сожалению, заранее угадать, к какой кодировке выводится текст, невозможно, поэтому проще попробовать установить командой chcp разные кодировки, чтобы добиться правильного отображения русского текста. Обычно используются кодировки 866 (кодировка русского текста DOS), 1251 (кодировка русского текста Windows), 65001 (UTF-8).
[Шрифт cmd.exe]
Иногда кракозябры можно убрать, если выбрать в свойствах окна cmd.exe шрифт Lucida Console (по умолчанию там стоит «Точечные шрифты»).
[Ссылки]
1. Универсальный декодер — конвертер кириллицы.
На днях пришлось решать небольшую проблему с плохой восприимчивостью комплекта Denwer к кодировки UTF-8. Проблема, честно говоря, оказалась пустяковая, и была решена минут за 15, 10 из которых заняло использование Гугла. В этом время, исследуя различные форумы, я заметил, что для многие не могут разобраться с этой проблемой достаточно долго. Кроме того, понял, что многих интересует зачем вообще использовать UTF-8, если есть прекрасная такая “русская” кодировка Windows-1251. Вот и решил написать пару постов на эту тему. Начну я с общего описания данных кодировок, а продолжу, непосредственно, описанием решения проблемы использования UTF-8 на пакете Denwer.
Не так давно, в связи со сложившимися обстоятельствами, решил отказаться от кодировки Windows-1251, с которой работал очень давно, и целиком и полностью перейти на UTF-8. Все причины перехода раскрывать не буду, но основные из них:
- большинство современных веб-платформ по-умолчанию работают именно на ней;
- её очень удобно использовать для создания мультиязычных проектов;
- набор используемых в кодировки символов около 100000;
- кодировка универсальная, т.е. русские символы и в Никарагуа остаются русскими.
Далее постараюсь написать несколько слов об основных отличиях кодировок Windows-1251 и UTF-8, а так же, в качестве бонуса, примеры объявления кодировки в HTML, PHP и для работы с базами данных MySQL.
Немного теории
Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста; она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Основные отличия кодировок
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251.
Настройка кодировки шрифтов в cmd.exe.
Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (©), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Плюсы UTF-8:
- UTF-8 позволяет работать одновременно с несколькими языками, т.е. выдавать тексты, в которых используются символы разных алфавитов и даже иероглифы. С использованием кодировки 1251 это невозможно;
- использование UTF-8 позволяет отказаться от кодовых таблиц, трансляций символов и всех прочих извращений, что были ранее с однобайтовыми кодировками;
- Нет кучи кодировок для одного и того же языка, как это было ранее для русского: cp1251, cp866, koi8r, iso8859-5.
Минусы UTF-8…
А есть ли они у этой кодировки вообще? Я знаю только разных мифах и легендах на эту тему, вот некоторые из них: “У UTF-8 есть проблемы со старыми браузерами” – маловероятно… Во всяком случае, если под старыми не подразумевают Lynx и Mosaic _); “С UTF-8 возникают проблемы на сервере” – ну да, если сервер по-умолчанию пытается определить другую кодировку. Но это не минус кодировки, уж точно…
Проблема: в консоли кириллические символы отображаются в неверной кодировке (в народе «кракозябры»):

При этом, если выполнить команду
chcp 866
кириллица становится читаемой только для текущего сеанса.
А при перезапуске командной строки кодировка снова сбивается. Если у вас ситуация выглядит так же, то это означает, что неверные параметры кодовой страницы берутся из реестра и решать проблему нужно именно там.
Как установить правильную кодировку в консоли
Запустите редактор реестра:

Откройте раздел HKEY_CURRENT_USER\Console и проверьте значение параметра CodePage (должно быть 866).
В нашем примере на картинке мы видим, что в параметре по какой-то причине указана кодировка 1251, что бесспорно и является причиной появления абракадабры.
Если у вас значение этого параметра отличается от 866, нажмите два раза по параметру CodePage:

Установите переключатель в положение Десятичная.
В поле Значение введите 866.
Нажмите OK:

Перезапустите командную строку (закройте окно и запустите его заново — Win+R, cmd, enter). Вы должны увидеть корректное отображение кириллицы:

Относится к рубрикам:Windows 7Windows 8, 8.1
Метки:866кодировкаконсоль
Возможно, будет интересно:
FILED UNDER : IT