admin / 04.08.2018
Распределенные вычисления заработок
.
Содержание
- Самые опасные распределенные вычисления
- Как происходит учет мощностей, предоставленных моими агентами?
- Как я могу посмотреть на свои агенты в MQL5 Cloud Network?
- По какой формуле рассчитывается стоимость пользования агентом?
- Какова стоимость одной единицы PR в единицу времени?
- Какой процент заработанного я получу за своих агентов?
- Цена установлена слишком высоко/низко, её нужно изменить
- Как начисляются средства, как продавать мощности своих агентов?
- Как я могу купить доступ в сети MQL5 Cloud Network?
- Какие платежные системы вы поддерживаете?
- Мои агенты несколько часов выполняли задания для MQL5 Cloud Network, но я не вижу начисления за них у себя в Профиле в разделе «Расчеты».
- Мои агенты загружены вычислениями, а средства на счет в MQL5.com не поступают.
- Как мне узнать стоимость расчетов, которые я хочу запустить в MQL5 Cloud Network? Не окажется ли сумма слишком большой?
- Системы распределенных вычислений
- Лучший способ сдать вычислительную мощность компьютера в аренду?
- Часто задаваемые вопросы
- С миру по нитке…
- Заработок на процессинге
- История развития распределенных вычислений
- распределенные вычисления за деньги
Могу ли я бесплатно предоставить свои агенты?
Да, конечно. Мы приветствуем энтузиастов и приглашаем всех желающих создавать проекты по распределенным вычислениям. Чтобы предоставить мощности своего компьютера бесплатно, вам достаточно скачать и установить агенты тестирования.
Самые опасные распределенные вычисления
Подробно об этом можно прочитать в разделе Справка.
Как происходит учет мощностей, предоставленных моими агентами?
Каждый агент тестирования имеет свой собственный рейтинг производительности PR (Performance Rating). Показатель PR периодически рассчитывается и обновляется с тем, чтобы иметь актуальные данные. При выполнении задачи работа, выполненная агентом тестирования, учитывается как произведение его PR на потраченное время Time.
Как я могу посмотреть на свои агенты в MQL5 Cloud Network?
Количество агентов, их текущий PR и количество выполненных задач можно посмотреть в закладке Aгенты своего профиля на MQL5.community. Там же вы можете временно отключить или удалить свои агенты из MQL5 Cloud Network.
По какой формуле рассчитывается стоимость пользования агентом?
Стоимость аренды агента зависит от его PR и времени его работы на заказчика. В общем виде оплата за выполненную агентом задачу вычисляется как произведение цены, производительности и времени: Money=Price*PR*Time, где:
- Money — оплата за выполненную задачу.
- Price — цена за единицу PR в секунду, она одинакова для всех агентов в сети MQL5 Cloud Network.
- PR — показатель производительности агента, рассчитываемый по специальной единой методике. Чем выше PR агента, тем быстрее он выполняет задачу и тем выше в итоге стоимость его аренды в единицу времени.
- Time — время, затраченное агентом на выполнение задачи. Чем выше PR агента, тем быстрее он выполнит задачу.
Для заказчика стоимость расчета задач не будет зависеть от PR выполняющих ее агентов, так как оплата за выполненную работу учитывает одновременно время выполнения и PR.
Какова стоимость одной единицы PR в единицу времени?
Стоимость работы агента тестирования с PR=100 в течение часа установлена в размере 0,02 USD. За единицу работы принимается один квант, который определен как работа агента с PR=1 в течение 1 ms (1 миллисекунды). Таким образом, стоимость одного кванта составляет:
QuantPrice=0,02 USD/(100PR*3 600 000 ms)=5,55556E-11 [USD/(PR*ms)]
В таблице представлены стоимость непрерывной работы в течение 1 часа и в течение 1 месяца одноядерного агента тестирования с PR=100.
| Интервал | QuantPrice, USD/(PR*ms) | PR агента | Time, ms | Сумма, USD |
|---|---|---|---|---|
| 1 час | 5.55556E-11 | 100 | 3 600 000 | 0.02 |
| 1 месяц | 5.55556E-11 | 100 | 2 592 000 000 | 14.40 |
Оптимальное количество агентов тестирования равно количеству ядер. Если компьютер имеет процессор с 4 ядрами, то по умолчанию установится 4 агента, соответственно стоимость будет в 4 раза больше.
Не рекомендуется ставить количество агентов больше, чем количество ядер. Увеличения заработка это не даст, так как в этом случае упадет PR каждого установленного агента.
Какой процент заработанного я получу за своих агентов?
Владелец агентов тестирования получает оплату за предоставленные вычислительные ресурсы на основе указанной формулы за вычетом комиссии размером 10%. Это означает, что из каждых 10 USD, которые заплатил заказчик за потребленные ресурсы, на ваш аккаунт будет перечислено 9 USD, что составляет 90% от оплаты.
Цена установлена слишком высоко/низко, её нужно изменить
Вопрос справедливой цены, которая устраивает и покупателей и продавцов вычислительных ресурсов, находится пока в стадии решения. Мы ищем баланс интересов заказчиков и владельцев агентов тестирования. Главный упор делается на то, что простаивающие процессорные мощности могут давать небольшой, но постоянный доход.
Без участия в сети MQL5 Cloud Network компьютер и так потребляет ресурсы, но 99% времени ничего не производит. Так заставьте его быть немного полезным!
Как начисляются средства, как продавать мощности своих агентов?
Учет и оплата задач, выполненных агентами в сети MQL5 Cloud Network, производятся автоматически. Необходимо в настройках MetaTester 5 Agents Manager на закладке MQL5 Cloud Network указать корректный логин в MQL5.community, на который будут начисляться заработанные средства.
Вы можете поменять логин в настройках и указать другой, тогда деньги начнут зачисляться на новый логин. Начисления производятся через нашу платежную систему.
Как я могу купить доступ в сети MQL5 Cloud Network?
Для этого необходимо сделать несколько шагов:
Какие платежные системы вы поддерживаете?
В текущий момент возможны операции с использованием PayPal и WebMoney. Список будет расширяться, более подробно вы можете почитать в статье Платежная система MQL5.community.
Мои агенты несколько часов выполняли задания для MQL5 Cloud Network, но я не вижу начисления за них у себя в Профиле в разделе «Расчеты».
Начисления за выполненные задания в MQL5 Cloud Network производятся на следующий день. Это происходит утром один раз в сутки одной строкой за всех агентов в разделе «Расчеты».
Мои агенты загружены вычислениями, а средства на счет в MQL5.com не поступают.
Начисления за выполненные расчеты в MQL5 Cloud Network производятся по окончании суток, вы их увидите на следующий день в своем Профиле в разделе «Расчеты».
При бане или блокировке аккаунта MQL5.community работа агентов перестает оплачиваться, в период блокировки агенты работают бесплатно.
Как мне узнать стоимость расчетов, которые я хочу запустить в MQL5 Cloud Network? Не окажется ли сумма слишком большой?
Вы можете запустить пробную задачу со временем выполнения в несколько минут. После ее окончания вы можете увидеть в «Расчетах» размер заблокированных средств для её оплаты и оценить стоимость полной задачи. Для сравнения, стоимость оптимизации, показанной в статье «MQL5 Cloud Network ускоряет расчеты», составил ~ 0.06 USD.

Системы распределенных вычислений
12
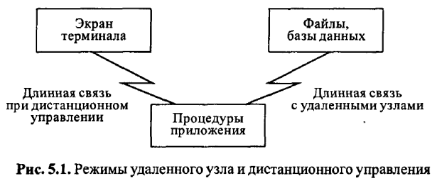
При выполнении проектных процедур с использованием более чем одного узла сети различают режимы удаленного узла и дистанционного управления (рис. 5.1).
В режиме удаленного узла основные процедуры приложения исполняются на терминальном узле. Связь с удаленным узлом используется для пересылки файлов. В большинстве случаев режим удаленного узла приводит к более заметной инерционности связи, чем режим дистанционного управления.
Дистанционное управление обеспечивает передачу клавишных команд в прямом направлении и экранных изображений (обычно лишь изменений в них) в сжатом виде в обратном направлении, поэтому задержки меньше.
Системы распределенных вычислений основаны на режиме дистанционного управления, при котором терминальный узел используется преимущественно для интерфейса с пользователем и передачи команд управления, а основные процедуры приложения исполняются на удаленном узле (сервере). Поэтому в сетях распределенных вычислений должны быть выделены серверы приложений.
Программное обеспечение организации распределенных вычислений называют ПО промежуточного слоя (Middleware). Современная организация распределенных вычислений в сетях Internet /Intranet основана на создании и использовании программных средств, которые могут работать в различных аппаратно-программных средах. Совокупность таких средств называют также многоплатформенной распределенной средой — MFC (Crossware).
Находят применение технологии распределенных вычислений RPC (Remote Procedure Call), ORB (Object Request Broker), DCE (Distributed Computing Environment), мониторы транзакций ТРМ (Transaction Processing Monitors) и др.
Средства RPC входят во многие системы сетевого ПО. Процедурная блокирующая синхронная технология RPC предложена фирмой Sun Microsystems. Вызов удаленных программ подобен вызову функций в языке С. При пересылках на основе транспортных протоколов TCP или UDP данные представляются в едином формате обмена. Синхронность и блокирование означают, что клиент, обратившись к серверу, для продолжения работы ждет ответа от сервера.
Для систем распределенных вычислений разработаны специальные языки, например для RPC — язык IDL (Interface Definition Language), который позволяет пользователю оперировать различными объектами безотносительно к их расположению в сети. На этом языке описываются интерфейсы к распределенным по сети компонентам в виде списка выполняемых компонентами процедур, типов аргументов и результатов процедур. С помощью компилятора языка IDL описание интерфейса преобразуется в программные модули, называемые стабами. Стаб на стороне клиента предназначен для упаковки параметров процедуры и обращения к системному вызову ≪послать≫, который позволяет передать параметры серверу. Стаб на стороне сервера распаковывает параметры и вызывает запрошенную процедуру. После выполнения процедуры аналогичным образом стабы участвуют в передаче клиенту результатов процедуры.
Формат RPC-сообщения:
- идентификатор сообщения;
- тип сообщения (запрос или ответ);
- идентификатор клиента;
- идентификатор удаленной процедуры;
- аргументы.
В идентификатор процедуры входят: имя узла, номер программы (часто номер означает совокупность программ определенного назначения), версия программы (версия — это идентификатор копии программы, например, версия — это время создания копии, копии создаются для использования в многопользовательском режиме), имя процедуры в программе. Имя сервера указывается в аргументах сгенерированного стаба. При компиляции стаба это имя уже известно или благодаря широковещательной рассылке информации сервером, или с помощью специальной программы — агента связывания.
ORB — технология объектно-ориентированного подхода, базирующаяся на спецификациях CORBA. Спецификации CORBA (Common Object Request Broker Architecture) устанавливают способы использования удаленных объектов (серверных компонентов) в клиентских программах. Взаимодействие клиента с сервером происходит с помощью программы-посредника (брокера) ORB. В случае применения ORB (в отличие от RPC) хранить сведения о расположении серверных объектов в узле-клиенте не нужно, достаточно знать расположение в сети брокера ORB. Поэтому доступ пользователя к различным объектам (программам, данным, принтерам и т.п.) существенно упрощен. Брокер должен определять, в каком месте сети находится запрашиваемый ресурс, и инициализировать серверную программу. После этого клиент может направлять запрос в серверный узел, а после выполнения запроса сервер будет возвращать результаты пользователю.
Для описания интерфейсов распределенных объектов используют язык ГОЬ, предложенный в CORBA. Этот язык отличается от языка IDL технологии RPC, в нем имеются средства описания интерфейсов, но нет средств описания операций.
При использовании ORB может увеличиться нагрузка на сеть, однако имеется и ряд преимуществ: обеспечивается взаимодействие разных платформ, не требуется дублирования прикладных программ во многих узлах, упрощаются программирование сетевых приложений и поддержка мультимедиа.
В CORBA создан протокол IIОР (Internet Inter-ORB Protocol), который обеспечивает взаимодействие между брокерами разных производителей.
Мониторы транзакций отличаются от RPC наличием готовых процедур обработки транзакций (в том числе отката транзакций), что упрощает работу программистов. Принимая запросы от клиентов и мультиплексируя их, монитор транзакций избавляет от необходимости создавать для каждого клиента отдельное соединение с базой данных.
Мониторы транзакций могут оптимально распределять нагрузку на серверы, выполнять автоматическое восстановление после сбоя и перезапуск системы.
Технология DCE разработана консорциумом OSF (Open Software Foundation). Она не противопоставляется другим технологиям (RPC, ORB), а является средой для их использования, например, в одной из реализаций DCE пакет Encina есть монитор транзакций, а пакет Orbix ORB представляет собой технологию ORB.
В DCE возможна одно- или многоячеечная структура сети. Выделение ячеек производится по функциональным, а не по территориальным признакам.
Лучший способ сдать вычислительную мощность компьютера в аренду?
В каждой ячейке должен быть главный сервер данных и возможно несколько дополнительных серверов с копиями содержимого главного сервера, причем доступ к дополнительным серверам разрешен только для чтения. Обновление данных осуществляется исключительно через главный сервер. Ячейка может занимать значительную территорию, главный сервер размещается вблизи от центра ячейки, дополнительные серверы — по периферии.
К функциям DCE относятся распределение вычислений по технологии RPC; распараллеливание вычислений (но программист сам проектирует параллельный процесс); защита данных; синхронизация (согласование времени); поддержка распределенной файловой системы.
Работая в DCE, пользователь дополнительно к своей прикладной программе пишет IDL-файл, в котором указывает свое имя, требуемые операции и типы данных. IDL-компилятор на основе этого файла создает три модуля: клиентский стаб (С1), серверный стаб (Sr), головной файл (Hd). Модуль С1 содержит вызовы процедур, Sr—обращения к базе процедур, Hd устанавливает связь между стабами.
Определение нужного сервера в DCE либо происходит автоматически с помощью ORB, либо возлагается на программиста, как в RPC.
12
Date: 2015-07-24; view: 95; Нарушение авторских прав
| Понравилась страница?
Лайкни для друзей: |
Folding@Home и Rosetta@Home
Общая информация о проектах: vk.com/boinc , tsc.overclockers.ru , www.boinc.ru , distributed.org.ua и distributed.ru
Подключайте Ваши компьютеры к проектам распределённых вычислений! Этим Вы окажете большую помощь в развитии математики, медицины и других наук, при этом это никак не скажется на скорости работы Ваших компьютеров, так как проекты работают на приоритете IDLE (то есть счёт ведётся только тогда, когда другие службы и программы не используют Ваш процессор)
Краткий обзор проектов
Проект Folding@Home — исследование фолдинга белков (то есть их "сворачивания" в уникальную пространственную структуру, определяющую функции белка), преимущественно в аспекте борьбы с некоторыми заболеваниями, порождёнными нарушениями их функций (например, болезнь Альцгеймера, отдельные виды рака, "коровье бешенство" и др.). Исследование осуществляется путём компьютерного моделирования процесса фолдинга ("сворачивания") белков на машинах добровольцев. Клиентское ПО забирает с одного из многочисленных серверов Folding@Home данные о белках и проводит на компьютере пользователя моделирование фолдинга (от нескольких часов до нескольких суток и более) и отправляет результаты обратно на сервер.
Проект Rosetta@Home — вычисление трехмерной структуры белков из их аминокислотных последовательностей. Это одна из самых больших проблем в молекулярной биологии. Одно из самых важных открытий в молекулярной биологии — то, что в пространстве белковая структура (связка аминокислот) стремится занять такое положение, чтобы энергия этой структуры была минимальна (представьте шар в трубе — шар будет всегда катиться вниз к основанию трубы, потому что это — самое устойчивое состояние). Итак, задача программы Rosetta@Home — посчитать наименьшую энергию белковой системы, если известны составляющие этой системы (аминокислоты) — при этой минимальной энергии это и будет искомый белок! Одна из сложностей заключается в том, что последовательностей аминокислот, из которых состоит белок много, в пространстве их можно соединить разными способами. Сочетание различных комбинаций соединений аминокислот дает огромные цифры — вот причина, по которой проекту так нужны большие вычислительные мощности.
По сути Rosetta — это компьютерная программа для поиска:
— структуры с наименьшей энергией для заданной аминокислотной последовательности для предсказания структуры белка
— обратная задача — поиск аминокислотной последовательности с наименьшей энергией для заданной белковой структуры
— расчета взаимодействия комплекса белок-белок.
Какой проект выбрать
Выбор проекта, который будет использоваться на Вашем компьютере зависит в первую очередь от вида подключения к Интернет/оплаты трафика.
Проект Rosetta@Home в день потребляет до 30 мегабайт входящего трафика и 500 килобайт исходящего. А вот проект Folding@Home в среднем скачивает задание размером всего 300 килобайт, считает его несколько дней и потом столько же отдаёт и закачивает новое. Так что если у Вас безлимитный Интернет и широкий канал, то лучше выбрать проект Rosetta@Home , а иначе — Folding@Home . Также выбор во многом зависит и от количества оперативной памяти компьютера. Проект Rosetta@Home занимает до 300 мегабайт ОЗУ, а Folding@Home — занимает в памяти всего 20 мегабайт (если не включен режим получения больших заданий, при котором может требоваться около 120 мегабайт ОЗУ). И все эти цифры следует умножить на число ядер у процессора.
Также в данный момент лучше при технической возможности (большой объём ОЗУ и неограниченный трафик) подключиться к проекту Rosetta@Home , поскольку сейчас в мире для проекта Rosetta@Home остро не хватает вычислительной мощности, в то время как у Folding@Home сейчас большое число считающих компьютеров, а также приставок PS3, видеокарт и т.д.
Ещё нужно придерживаться правила, что чем быстрее процессор, тем целесообразнее на нём считать Folding@Home , а чем слабее — тем выше целесообразность счёта на нём проекта Rosetta@Home . (А если процессор очень старый, менее 1 ГГц, то тогда Folding@Home вообще не целесообразно считать на нём). В таком случае лучше считать проект Rosetta@Home (если позволяет ОЗУ и интернет-трафик), а при малых количествах ОЗУ и когда нельзя позволить большой интернет-трафик — то считать либо POEM@Home либо Spinhenge@Home (см. ниже).
Также перед выбором проекта — см. ветку форума http://forums.overclockers.ru/viewforum.php?f=21
Если Вы используете сеть "ВКонтакте", в ней группа команды распределённых вычислений следующая: http://vkontakte.ru/club186520 в ней много полезной справочной информации, можно задавать вопросы по проекту Folding@Home . По BOINC-проектам группа такая: http://vkontakte.ru/club11963359
http://my.mail.ru/community/cranch — группа о распределённых вычислениях в сети "Мой мир" на Mail.Ru.
http://my.mail.ru/community/fhclub/ — группа о проекте Folding@Home в сети "Мой мир" на Mail.Ru.
http://www.facebook.com/group.php?gid=12646995655 — группа о распределённых вычислениях в сети "Facebook".
http://minskfoldingteam.at.tut.by/ — форум в Минске.
http://vip.karelia.ru/viewtopic.php?t=51525 — форум в Петрозаводске.
distributedcomputing.info — Самая свежая информация о текущих активных проектах распределённых вычислений.
www.gridrepublic.org — Статистика и описание проектов распределённых вычислений на платформе BOINC
http://blog.karelia.ru/yura8/ — Новости про науку, образование, распределённые вычисления
http://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D1%81%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D1%91%D0%BD%D0%BD%D1%8B%D0%B5_%D0%B2%D1%8B%D1%87%D0%B8%D1%81%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F — статья в энциклопедии о распределённых вычислениях.
Новые интересные статьи про распределённые вычисления. Интересно прочитать всем:
1) Распределенные вычисления: волонтеры на службе науки (статья из журнала): http://www.vechnayamolodost.ru/pages/drugienaukiozhizni/rasvyvonaslnab6.html
2) Интернет-журнал «Распределенные вычисления»: самые свежие новости проектов и их результаты и достижения: http://new-distributed.livejournal.com/
3) Статья «Распределенные вычисления: домашний компьютер как научная лаборатория»: http://prostonauka.com/raspredelennye-vychislenija
Всем кому интересно — по адресу http://boinc.gorlaeus.net/FinishedProjects.php полное описание (файлы в формате PDF, PPT, XLS) уже завершённых решённых задач по классической динамике (с помощью проекта Leiden Classical . Там на нидерландском языке, но всё равно, много графиков и иллюстраций, на которые интересно посмотреть, чтобы понять ценность и важность применения распределённых вычислений для решения различных задач из различных областей физики.
Также есть сайт сравнительно новый сайт (недавно появился): http://boinc.netsoft-online.com/ где можно посмотреть различную подробную статистику по текущим BOINC проектам (и завершённым BOINC проектам)
Платформа BOINC и проект Rosetta@Home
Установка BOINC, регистрация аккаунта для проекта Rosetta@Home настолько просты, что подробно здесь описываться не будут.
Иллюстрация процесса установки программы BOINC
На сайте www.boinc.ru есть FAQ, подробная информация по установке, проекту Rosetta@Home и другим проектам. Саму программу BOINC можно загрузить с сайта http://boinc.berkeley.edu/ . Для подключения к проекту — адрес: http://boinc.bakerlab.org/rosetta
Кстати, для более надёжной работы проектов в BOINC необходимо в "Настройки клиента…" — "диск и память" — поставить галку "Оставлять неактивные приложения в памяти".
Ещё в настройках BOINC нужно в "Настройки клиента…" — "процессор" — "В многопроцессорных системах использовать" ___ % процессоров — обязательно поставить 100 % (иначе будут использоваться не все ядра процессора).
Другие, наиболее интересные проекты на платформе BOINC, которые также полезны для науки и медицины:
1) Проект LHC@Home — научно-исследовательский BOINC-проект распределенных вычислений, изучающий движение заряженных частиц в Большом Адронном Коллайдере. Присоединиться к проекту — http://lhcathomeclassic.cern.ch/sixtrack/
2) Ещё один полезный проект, к которому также можно подключиться пользователям BOINC — это RALPH@Home который занимается тестированием новых счётных модулей для проекта Rosetta@Home .
Присоединиться к проекту — http://ralph.bakerlab.org/
Требования к компьютеру и Интернету у RALPH@Home точно такие же, как и у проекта Rosetta@Home , поэтому если Вы подключились к Rosetta@Home , то желательно подключиться одновременно и к RALPH@Home . Участвовать в RALPH@Home как только в одном проекте нет смысла, поскольку задания для него бывают раз в 3 или 4 недели (когда выходит новый счётный модуль).
3) Asteroids@home — проект изучает форму и параметры вращения астероидов по фотометрическим данным. Присоединиться к проекту — http://asteroidsathome.net/boinc/
4) Проект POEM@Home — в проекте используется метод моделирования структуры белка. Комбинированный подход в изучении строении белка, дальние цели этого проекта — разработать метод моделирования белковых молекул, которые уже могут использовать фармацевты, врачи, ученые, а также детально изучить структуру мебранных белков. Присоединиться к проекту — http://boinc.fzk.de/poem/
boincstats.com — просмотр статистики, состояния всех BOINC-проектов.
boincsynergy.com — просмотр статистики, новости BOINC-проектов.
http://boincstats.com/stats/project_graph.php?pr=bo — статистика BOINC проектов за последний день, месяц, и т.д.
Проект Folding@Home
установка на компьютер клиента
Здесь будет рассмотрен самый простой и распространённый случай, когда устанавливается консольный клиент в качестве службы (без задействования видеокарт ATI / NVIDIA или нескольких процессоров, для которых совсем другие клиенты).
Необходимо войти на компьютер с правами администратора (поддерживаются системы Windows 2000/XP/2003).
Далее создать каталог C:\WINDOWS\system32\FAH\ в который поместить файлы FAH504-Console.exe, client.cfg, FoldinGL.exe и дать команду:
sc create FAH type= own start= auto error= normal binPath= «C:\WINDOWS\system32\FAH\FAH504-Console.exe -svcstart» obj= LocalSystem DisplayName= FAH
Внимание, если используется версия 6.хх консольного клиента, то сам файл будет называться не FAH504-Console.exe, а Folding@home-Win32-x86.exe и в параметрах сервиса надо указывать путь к каталогу, куда он устанавливается, то есть команда для установки сервиса будет такой:
sc create FAH type= own start= auto error= normal binPath= "C:\WINDOWS\system32\FAH\Folding@home-Win32-x86.exe -svcstart -d C:\WINDOWS\system32\FAH" obj= LocalSystem DisplayName= FAH
Теперь можно открыть сервисы Windows и запустить сервис FAH (либо вообще просто дать команду sc start FAH ). И всё, клиент подключится к серверам Folding@Home — проекта, скачает задание и счётное ядро и будет считать в течении нескольких дней. Всё будет далее работать незаметно для пользователя.
Вот назначение файлов:
FAH504-Console.exe или Folding@home-Win32-x86.exe — собственно сам сервис
client.cfg — настройки клиента
FoldinGL.exe — программа для 3D просмотра обрабатываемых молекул
Сейчас конечно лучше ставить саму последнюю версию, а информация о 5.04 приведена только потому, что она была с ноября 2005 и по август 2008 повсеместно используемой и не менялась за эти 3 года, что говорит о её проверенной стабильности.
Структура файла client.cfg
[settings] username=Colombia team=47191 asknet=no bigpackets=no machineid=1 local=0 [http] active=no usereg=no usepasswd=no proxy_name= proxy_passwd= host= port= [core] priority=0 cpuusage=99 disableassembly=no checkpoint=15 ignoredeadlines=no [power] battery=no [clienttype] memory=480 type=0
Теперь краткое описание файла client.cfg:
username= Ваше имя, которое будет отображаться на серверах статистики
team=47191 — номер команды
bigpackets= Для 5.04 и 6.хх версий этот параметр может принимать разные значения. В версии 5.04 — no — получать из Интернет задания размером до 20 килобайт (в ОЗУ будут занимать до 10 мегабайт), yes — получать из Интернет задания размером до 3 мегабайт (в ОЗУ будут занимать до 120 мегабайт). В версиях 6.хх — small получать меньше 5 Мб, normal — получать до 10 Мб, а big — получать более 10 Мб.
Часто задаваемые вопросы
Реально же, если указать small, то задания пока выдаются меньше 300 килобайт.
priority=0 — ставьте priority всегда равным 0 (иначе Folding не будет вытесняться при сканировании дисков антивирусом Symantec или Kaspersky).
cpuusage=99 — ставить 100 не рекомендуется (при 100 были сообщения о проблемах с Nero).
memory=480 — сколько ОЗУ не жалко для проекта (хотя на данный момент максимум будет расходоваться 120 Мб).
Вот готовый архив для быстрого запуска: fah-client.zip — в этом архиве самая свежая консольного клиента (на данный момент — 6.23). Архив нужно распаковать в каталог C:\WINDOWS\system32\ (получится каталог C:\WINDOWS\system32\FAH\). Из него надо просто запустить 1 раз файл Run.cmd — он установит в систему сервис FAH. И всё, можно дать команду sc start FAH — и сервис запустится.
Если у Вас процессор с Hyper Threading или с несколькими ядрами, то тогда следует установить несколько копий клиента на компьютер. Второй — в папку например C:\WINDOWS\system32\FAH1\ и только не забыть в файле Run.cmd перед его запуском в 4 местах слово FAH заменить на FAH1 и в файле client.cfg вместо machineid=1 поставить machineid=2
На всякий случай — архив с предыдущей 5.04 версией клиента: old-fah-client-504.zip — эта версия уже устарела, но на всякий случай может кому и потребуется (ведь она была с ноября 2005 и по август 2008 повсеместно используемой и не менялась за эти 3 года, что говорит о её проверенной стабильности).
Ещё одна важная причина, по которой на странице до сих пор выложена версия 5.04, — это то, что было замечено, что новые версии клиента (6.20, 6.23 и т.д.) при ВСЕХ значениях параметра bigpackets= выдают задания случайных размеров, когда большие, когда маленькие. Так что на компьютерах с малым количеством ОЗУ и где платный интернет до сих пор актуальна версия клиента 5.04, так как при значении bigpackets=no она точно выдаёт короткие задания (до 300 килобайт), которые требуют мало ОЗУ.
Внимание! Концы строк в файле client.cfg должны быть только символом $0A (если Ваш редактор сделает $0D$0A, то при запуске программы файл client.cfg не только не будет прочитан, но и всё его содержимое будет стёрто). Используйте для редактирования client.cfg только FAR Manager (после редактирования — проверьте, какие концы строк). Чтобы принудительно сделать концы строк $0A следует использовать плагин trucr104 для FAR ( ftp://info.elf.stuba.sk/pub/pc/utilfile/trucr104.rar ).
Программа FoldinGL.exe — программа для 3D просмотра обрабатываемых молекул, однако она может работать не на всех видеокартах.
FoldinGL НЕ работает на Intel 810 и ниже, RAGE XL PCI Family (если драйвера встроенные в Windows), SiS 661FX и ниже
FoldinGL работает на Intel 815 (если драйвера от Intel) и выше, NVidia Vanta LT и выше, S3 Graphics ProSavageDDR
Также в случае если задание для нового ядра FahCore_7c.exe то программа FoldinGL зависает.
http://fah-web.stanford.edu/cgi-bin/main.py?qtype=osstats — быстрый просмотр статистики по Folding@Home (сколько компьютеров, процессоров занято для проекта во всём мире).
Выбор проектов в случае многоядерных процессоров
Если у Вас достаточно мощный современный компьютер с двуядерным процессором (или технологией Hyper Threading) или несколько процессоров, всегда надо помнить, что клиент Folding@Home использует только одно ЯДРО. GPU клиент Folding@Home в случае видеокарты ATI также использует только одно ядро центрального процессора. А вот видеокарты NVidia вообще не используют центральный процессор при расчётах.
Исключение составляет лишь SMP клиент для Folding@Home , который специально предназначен для многоядерных систем и использует все ядра.
Предположим, такой случай. У Вас четырёхядерный процессор и современная видеокарта ATI. Тогда самый лучший выбор будет такой — поставить один GPU клиент и один SMP клиент (не забывать, конечно с разными machineid в настройках client.cfg). Причём для SMP клиента сделать доступ не ко всем 4, а только к 3 ядрам. Тогда одно ядро будет для GPU клиента. В этом случае у компьютера будут для расчётов задействованы все ядра процессора + видеокарта и будет достигнута максимальная вычислительная мощь. А случае видеокарты NVidia, в SMP клиенте даже не надо закрывать доступ к одному ядру (т.к.
в случае видеокарт NVidia центральный процессор не используется вообще).
Выбор проектов для современных
видеокарт ATI и NVidia
Если у компьютера имеется современная видеокарта ATI (24xx и выше) или NVidia (GeForce 8ххх и выше), то тогда имеет смысл задействовать её для распределённых вычислений. Причём следует учитывать, что видеокарта ATI при расчётах целиком использует одно ядро центрального процессора. А вот видеокарты NVidia вообще не используют центральный процессор при расчётах. Таким образом, например, если у Вас двуядерный процессор и современная видеокарта NVidia, то можно использовать на компьютере не 2, а 3 клиента Folding@Home (два — консольных однопроцессорных и один — графический)!!!

Работают сразу 3 клиента на двуядерном процессоре!
Кстати, в случае если у Вашего компьютера видеокарта от NVidia, большой объём ОЗУ и безлимитный интернет (и к тому же компьютер долго не выключается), то в таком случае лучше всего центральный процессор целиком отдать проекту Rosetta@Home , а видеокарту NVidia отдать проекту GPUGRID (который тоже потребляет большой интернет трафик). Основная направленность проекта GPUGRID — моделирование молекул.
Некоторые картинки, иллюстрации:

Как надо правильно устанавливать BOINC в Windows,
чтобы он запускался без участия пользователя в качестве службы.
Однако, если Вы будете участвовать в проектах, которые используют видеокарту, то тогда эту галку устанавливать нельзя, иначе BOINC не будет видеть видеокарту!
Иллюстрация процесса установки программы BOINC
Иллюстрации по проекту Folding@Home :
1) Одна из обрабатываемых молекул (ядро Gromacs — FahCore_78.exe) (получен программой FoldinGL) при bigpackets=no
2) Одна из обрабатываемых молекул (ядро Gromacs — FahCore_78.exe) (получен программой FoldinGL) при bigpackets=yes
3) Одна из обрабатываемых молекул (ядро Gromacs — FahCore_78.exe) (получен программой FoldinGL) при bigpackets=yes
4) Одна из обрабатываемых молекул (ядро Gromacs — FahCore_78.exe) (получен программой FoldinGL) при bigpackets=yes
5) Одна из обрабатываемых молекул (ядро Gromacs 33 — FahCore_a0.exe) (получен программой FoldinGL) при bigpackets=yes
В файле projects_sep_okt_2009.xls представлены данные за 2 месяца (сентябрь и октябрь 2009 года) про продвижение проекта Rosetta@Home , а также в этом файле находятся 26 листов, на которых представлены данные о продвижении и состоянии 15 самых активных проектов за соответствующий день (по данным сайта http://boincstats.com/).
Эта страничка последний раз обновлялась 26 января 2013 года.
Смотрите также специальную методичку по настройкам BIOS компьютера и другим настройкам Windows.
< < < На главную страничку < < <
Republica de Colombia, Informacion de Colombia, Distrito Capital, Historia de Colombia, Cultura de Colombia, Musica de Colombia, Educacion en Colombia, Vallenato, Colombiana, Informacion general de Colombia, Bogota, Medellin, Cali, Barranquilla, Cartagena, Cucuta, Bucaramanga, Ibague, Soledad, Pereira, Antioquia, Valle del Cauca, Norte de Santander, Tolima, Risaralda, distributed computing project, proyecto de computacion distribuida, NVidia, CUDA, NVidia CUDA
12.04.2007
Анна Нозик
С миру по нитке…
Распределенные вычисления: цели, проекты и участники
 |
Современный мир развивается очень динамично. Новые технологии, рекламные и программные уловки приводят к тому, что мы регулярно меняем свой компьютер, покупая с каждым разом все более мощный. Многие из нас никогда не задумываются о том, что значительную часть времени ресурсы нашего компьютера используются не более чем на 5%.
С другой стороны, перед современной наукой стоит множество задач, для решения которых нужна мощная вычислительная техника. Суперкомпьютеров в мире не очень много, они дороги и не всегда доступны, а также их мощности часто бывает недостаточно. Таким образом, возникает ситуация, при которой 95% ресурсов достаточно мощных домашних машин никогда не используются, а решать глобальные задачи исследователям не на чем.
Идея распределенных вычислений возникла довольно давно, однако широкое распространение она получила лишь тогда, когда Интернет стал повсеместно доступен. Под распределенными вычислениями понимается способ выполнения расчетов путем их разделения между множеством компьютеров, которые разбросаны по всему миру. Идея заключается в том, что любую задачу, требующую большого объема вычислений, можно поделить на много маленьких частей, каждая их которых окажется по зубам любой домашней машине.
Существующие на сегодняшний день проекты, которые используют методы распределенных вычислений, радуют своим многообразием. Физики, химики, математики, астрономы, биологи и даже компьютерщики всего мира нуждаются в ресурсах для решения своих задач.
Пожертвовать частичку своего компьютера для науки может любой пользователь, подключенный к Интернету
Пожертвовать частичку своего компьютера для науки может любой пользователь, подключенный к Интернету.
Для этого необходимо выбрать проект, в котором интересно было бы принять участие. После этого необходимо установить на компьютер клиентскую программу, которая периодически связывается с центральным сервером проекта и получает задание. Задание выполняется в тот момент, когда процессор не занят полезной нагрузкой. На обсчитывание каждой части уходит от нескольких минут до нескольких недель в зависимости от задачи. После выполнения задания программа связывается с сервером и передает результат. Полученные от пользователей части задания склеиваются в общий результат.
Для организации распределенных вычислений используются различные инструменты. На сегодняшний день для упрощения процесса организации и управления распределенными вычислениями создано несколько программных комплексов, среди которых есть как коммерческие, так и абсолютно бесплатные. Самый известный из комплексов — BOINC — Berkeley Open Infrastructure for Network Computing (Открытая инфраструктура для распределенных вычислений университета Беркли), он используется в значительной части существующих исследований.
Рассмотрим несколько интересных проектов.
Самый первый проект, в котором был использован метод распределенных вычислений, — это проект SETI@Home. Его целью ставился поиск внеземных цивилизаций (Search for Extraterrestrial Inteliegence), для чего исследователями обрабатывается космический шум, записываемый радиотелескопом Arecibo. Сигналы, полученные радиотелескопом, исследуются на предмет наличия особых характеристик — признаков разумной радиоактивности. Программа-клиент выглядит как скринсейвер.
 |
Проект Climate Prediction занимается прогнозированием изменений климата на Земле, чтобы определить, насколько точны существующие методы долговременного предсказания погоды и насколько сильно на их точность влияют погрешности в исходных данных. Проект призван помочь в предсказании погоды на 50 лет вперед. Вычисления, связанные с климатом Земли, настолько ресурсоемки (в них может фигурировать до 100 миллионов переменных), что при работе с суперкомпьютером в ходе сеанса симуляции одновременно можно изменять лишь несколько параметров. Система распределенных вычислений позволяет запускать сразу множество симуляций одновременно, но с различными параметрами. Каждая программа-клиент работает на компьютерах участников несколько месяцев, прежде чем отправит обработанные данные обратно на центральный сервер. Так как все участники получат немного разные входные данные, то результат работы каждого из них уникален. Затем среди полученных результатов выбираются те, которые наиболее точно отражают реально происходившие в мире климатические события, и делаются выводы о наиболее вероятных изменениях, ожидающих нас в будущем.
Участники проекта Einstein@Home занимаются составлением атласа излучаемых звездами-пульсарами гравитационных полей для всего неба. Это делается с целью проверки одной из гипотез Эйнштейна, которая предсказывает теоретическую возможность существования гравитационных волн, возникающих при столкновениях черных дыр и взрывах звезд. Однако пока никому из ученых так и не удалось зафиксировать эти загадочные волны. Данные для анализа поступают с Лазерно-интерферометрной обсерватории гравитационных полей (LIGO).
Проект Rosetta@Home позволяет его участникам присоединиться к решению одной из самых больших проблем в молекулярной биологии — вычислению трехмерной структуры белков из их аминокислотных последовательностей. В случае успешного моделирования белковых комплексов и структур появляется шанс победить такие болезни, как рак, малярия, болезнь Альцгеймера, сибирская язва, и другие генетические и вирусные заболевания.
Участники проекта Folding@home занимаются получением более точного представления о болезнях, вызываемых дефектными белками.
Заработок на процессинге
С помощью их компьютеров изучаются белки, имеющие отношение к болезни Альцгеймера, Паркинсона, диабету типа II, коровьему бешенству и склерозу. Результаты этого проекта выкладываются в свободный доступ и могут сразу же использоваться учеными по всему миру.
Проект Grid.org Cancer Research позволяет нам присоединиться к поиску лекарства от рака. Программа моделирует взаимодействие миллиардов возможных молекул с белками, участвующими в развитии этой болезни. Цель проекта — определить, не является ли одна из этих молекул возможной основой для нового лекарственного средства.
 |
Потенциальных задач для вашего простаивающего процессора имеется множество. Исследователи, использующие в решении своих задач методы распределенных вычислений, при небольших затратах на создание программного обеспечения получают огромные вычислительные мощности. Поэтому среди исследователей существует определенная конкуренция за добровольцев. А для чего простые обыватели тратят свое время, платят за электричество и за трафик?
К проектам присоединяются по разным причинам. Среди основных можно выделить следующие.
Материальный или моральный стимул. Многие исследователи разыгрывают среди добровольцев ценные призы, крупные денежные суммы или обещают сделать соавтором научного труда того человека, на чьем компьютере будет получен ценный результат.
Помощь науке. Чувство сопричастности к серьезной научной деятельности — достаточно важный стимул. Кроме этого, подобная деятельность может быть единственным доступным способом для тех, кто потерял родных от тяжелой болезни, оказать помощь больным всего мира.
Дух соревнований. По каждому из проектов ведется статистика. Причем как по отдельным пользователям, так и по командам, в которые они объединяются, и даже по странам. Командные соревнования увлекают, стимулируют привлекать друзей и знакомых. Зарегистрированных российских команд, участвующих в распределенных вычислениях, — более 100. Среди них есть как крупные, так и состоящие всего из 1-2 человек. Несмотря на то что Интернет в России распространен еще не повсеместно, российские команды в большинстве проектов занимают места в первой двадцатке.
Возможно, когда-нибудь каждый из нас сможет с гордостью заявить, что он помог изобрести лекарство от рака, доказать гипотезу Эйнштейна или услышать позывные инопланетян. Нам есть к чему стремиться!
Все статьи | Интернет | Сервисы
История развития распределенных вычислений
⇐ ПредыдущаяСтр 3 из 16Следующая ⇒
Проблема выбора между централизованной и распределенной моделями предоставления вычислительных ресурсов является одной из ключевых проблем организации вычислительных систем.
распределенные вычисления за деньги
Примером этого может являться статья «Централизованные и децентрализованные вычислительные системы: организационные соображения и варианты управления», опубликованная еще 1983 г. [43].
С того момента, как появилась возможность соединять компьютеры между собой, многие группы исследователей занялись изучением возможностей, предоставляемых системами распределенных вычислений, создавая множество библиотек и промежуточного программного обеспечения.
Разработанное ППО предназначалось для того, чтобы обеспечить организацию и управление гео- графически-распределенными ресурсами таким образом, чтобы они представ- ляли собой единую виртуальную параллельную вычислительную машину.
До середины 70-х годов прошлого века по причине высокой стоимости те- лекоммуникационного оборудования и относительно слабой мощности вычис- лительных систем доминировала централизованная модель.
В конце 70-х годов появление систем разделения времени и удаленных терминалов, явилось предпосылкой возникновения клиент-серверной архитектуры, обеспечивающей предоставление ресурсов мейнфреймов (больших вычислительных машин) конечным пользователям посредством удаленного соединения.
Дальнейшее развитие телекоммуникационных систем и появление персональных компьютеров дало толчок развитию клиент-серверной парадигмы обработки данных. На по- следующих этапах произошло уточнение и переосмысление задачи распреде- ленных вычислений.
В 2000-м году Ян Фостер определил задачу распределенных вычислительных систем как «гибкое, безопасное, координированное распределение ре- сурсов среди динамических наборов пользователей, организаций и ресурсов» [31].
Он предложил называть такие распределенные вычислительные системы термином грид.
Коммерческие разработчики, развивая идею грид, в 2007-2008 годах представили концепцию «облачных вычислений», в основе ко торой было предоставление высокомасштабируемых виртуальных вычисли- тельных ресурсов конечному пользователю через интернет в виде услуг. На текущий момент, использование распределенных вычислений в виде технологий грид и облачных вычислений набирает обороты. Они применяются для решения различных задач, их использование становится все проще. Распре- деленные вычисления становятся неотъемлемой частью научных и коммерческих высокопроизводительных вычислений.
1 Ян Фостер – директор института вычислений, старший научный сотрудник Арагонской национальной лаборатории (США). Является автором множества научных работ, посвященных параллельным и распределен- ным вычислениям. Руководил разработкой нескольких международных распределенных вычислительных си- стем. Автор концепции грид.
Первое поколение систем распределенных вычислений
Первые проекты по распределенным вычислениям, появившиеся в начале 1990-х годов, основывались на объединении вычислительных возможностей суперкомпьютеров.
Основной целью данных проектов было предоставление вычислительных ресурсов для определенного ряда высокопроизводительных приложений. В качестве типичных проектов того времени можно рассмотреть проекты FAFNER [34] и I-WAY [61]. Эти проекты стали базовыми, для всей от- расли распределенных вычислений в дальнейшем. На них основывались первые попытки стандартизации распределенных вычислений в гетерогенных вычис- лительных средах.
Проект FAFNER
Проект FAFNER был создан для решения задачи разложения больших чисел на основе мощностей географически-распределенных вычислительных систем. Нахождение простых множителей больших чисел является позволяет расшифровать данные, зашифрованные на основе алгоритма RSA.
Для шифрования секретной информации широко используется метод ко- дирования, основанный на публичном ключе RSA (аббревиатура из первых букв фамилий разработчиков данного метода: Rivest, Shamir и Adleman). Метод работы данного ключа основан на том, что разложение на множители больших чисел (сто и более знаков) – чрезвычайно сложная вычислительная задача.
В марте 1991 корпорация RSA Data Security основала конкурс по поиску и реали- зации методов разложения больших чисел на множители.
Это состязание обес- печило создание крупнейшей библиотеки по методикам поиска простых множителей от крупнейших ученых со всего земного шара. Все алгоритмы поиска простых множителей, известные на сегодняшний день, требуют чрезвычайно большого количества вычислений (поэтому этот метод и используется для шифрования).
Но особенность параллельной реализации этих алгоритмов состоит в том, что процессы поиска делителей вычислительно независимы, и не требуют обмена информации во время расчета. Первые попытки реализовать подобный алгоритм на распределенных вычисли- тельных системах основывались на обмене электронными письмами.
В 1995 г.
консорциумом организаций в области информационных техноло- гий был запущен проект FAFNER – Factoring via Network-Enabled Recursion (Сетевое разложение на множители посредством рекурсии) по решению задачи разложения больших чисел посредством Веб-серверов.
Можно выделить следующие особенности, отличавшие этот проект от многих других [34]:
реализация NFS – Network File System (Сетевая Файловая Система) позво- ляла даже малым рабочим станциям (с 4 Мб оперативной памяти) выпол- нять полезную работу, рассчитывая свой маленький фрагмент задачи;
проект FAFNER поддерживал анонимную регистрацию участников. Поль- зователи могли поделиться своими вычислительными ресурсами без бояз- ни раскрытия своей личной информации;
консорциум сайтов, представлявших костяк вычислительной системы, формировали иерархическую структуру веб-серверов, что уменьшало воз- можность возникновения «узкого места» в вычислительной системе. Данная система доказала свою надежность и качественность, заняв первое место по производительности в конкурсе, проводимом в рамках конференции Supercomputing’95.
Проект I-WAY
I-WAY – Information Wide Area Year (Год Информации Глобальных Сетей) – экспериментальная высокопроизводительная сеть, которая объединила мно- жество высокопроизводительных компьютеров и передовые средства визуали- зации в США.
Она была спроектирована в начале 1995, с целью объединения высокоскоростных сетей, существующих на тот момент. Данные и компьютер- ные ресурсы были распределены по 17-и локациям в США и объединены 10-ю сетями, с различной пропускной способностью, различными протоколами со- единения и с использованием различных сетевых технологий для их построе- ния [23].
В рамках проекта, была построена аппаратная инфраструктура, посред- ством которой осуществлялся доступ к ресурсам сети I-WAY. Она состояла из базовых рабочих станций под управлением операционной системы UNIX, на которые было установлено специальное ППО (сервер I-POP).
Система I-POP брала на себя функции шлюза к ресурсам сети I-WAY. Каждый такой сервер поддерживал стандартные процедуры аутентификации, резервирования ресур- сов создания процессов и коммуникации. Также, в рамках данного проекта был разработан планировщик ресурсов, известный как «Брокер Вычислительных Ресурсов» (CRB – Computing Resources Broker). Он обеспечивал выполнения функций управления очередями задач, распределения заданий между компьютерами и слежения за ходом реше- ния. Для поддержки пользовательских приложений была адаптирована библио- тека передачи данных Nexus.
В нее были включены механизмы, поддерживаю- щие автоматическое конфигурирование работы пользовательского приложения, в зависимости от методов передачи данных, базовой операционной системы и т. п.
Проект I-WAY использовался для решения следующих задач [23]:
суперкомпьютерные вычисления;
доступ к удаленным ресурсам;
задачи виртуальной реальности.
⇐ Предыдущая12345678910Следующая ⇒
Читайте также:
FILED UNDER : IT