admin / 01.02.2018
Как посмотреть кэш память 🚩 увеличение кэша второго уровня 🚩 Компьютеры и ПО 🚩 Другое
 Здравствуйте читатели блога MoyiZametki.ru. Времена идут, а вместе с ними и информационные технологии шагают по планете. Шагают, так, что тока смотри. И вот однажды приходит такой момент, когда технические характеристики ПК начинают не удовлетворять пользователя. Например однажды придёт такой момент, когда очередная версия любимой игры не сможет работать на компьютере. Её не удовлетворят параметры процессора, видеокарты, объем оперативной памяти. Это я только основные компоненты перечислил. Но не стоит паниковать и выкидывать на помойку ПК. Его можно модернизировать, т.е. заменить некоторые устаревшие части. Нужно знать лишь знать до каких пределов можно производить апгрейт (модернизацию). Сегодня я поведаю вам об одной утилитке, которая всё знает о процессоре.
Здравствуйте читатели блога MoyiZametki.ru. Времена идут, а вместе с ними и информационные технологии шагают по планете. Шагают, так, что тока смотри. И вот однажды приходит такой момент, когда технические характеристики ПК начинают не удовлетворять пользователя. Например однажды придёт такой момент, когда очередная версия любимой игры не сможет работать на компьютере. Её не удовлетворят параметры процессора, видеокарты, объем оперативной памяти. Это я только основные компоненты перечислил. Но не стоит паниковать и выкидывать на помойку ПК. Его можно модернизировать, т.е. заменить некоторые устаревшие части. Нужно знать лишь знать до каких пределов можно производить апгрейт (модернизацию). Сегодня я поведаю вам об одной утилитке, которая всё знает о процессоре.
Содержание
Посмотреть процессор изнутри
Поможет в этом программа CPU-Z. Скачать её можно с сайта разработчиков, вот по этой ссылке. Или тут. Она на английском, но это не проблема, т.к. там всё ясно как день. Хотя кое что я всё же поясню.
Итак, после установки и запуска видим вот такое окошко.

На первой вкладке CPU, отображается вся техническая информация о центральном процессоре. А именно:
- Производитель и модель изделия
- Очень полезный параметр — Soket. Это разъём под процессор. Именно он покажет до какого уровня можно модернизировать проц.
- Кеш память (Cache) — это внутренняя память процессора
- Количество ядер (Cores)
Единственный параметр, который я не нашёл тут — это частота процессора в МГЦ. Частоту можно посмотреть при помощи программы Speccy, она тоже отображает достаточно подробную информацию, но всё же анализ двумя утилитами лишним не будет.
Вкладка Caches. Более подробная информация о кеше.

Вкладка Maindord. Всё о материнской плате.

На остальных вкладках вы найдёте характеристики ОЗУ и видеокарты.
Для лучшего понимания надо сказать, что кэш память – это специальная память, которая используется для быстрого доступа к информации, также по её показателям можно сказать про быстродействие вашего процессора. Находится кэш на процессоре, прямо на основном кристалле. Часто задаваемым вопросом является такой: как узнать кэш? Если вы имеете документацию об установленном на вашем компьютере оборудовании, то это не сложно взять и просмотреть в характеристиках процессора.
Не имея таких подробных данных про ваш процессор, как узнать, какой кэш вы используете? На помощь вам придёт специальная утилита под названием CPU – Z. Она предназначена для отображения всех характеристик, сведений про процессор, его память и кэш. Данная программа очень проста и удобна, имеет небольшой размер и легкий интерфейс.
Кэш-память процессора. Уровни и принципы функционирования
Установив её, выберите вкладку «Caches». После этого в окне программы вы увидите ваш кэш, он разделён на три уровня. Первый — самый быстрый и имеет маленький размер, остальные, как правило, имеют меньшее быстродействие, но больший объем памяти.
Предоставляю ссылку на скачивание CPU – Z. Кстати, ваш кэш можно просмотреть также и в программе «Everest».
Наборно-ассоциативный кэш
Наборно-ассоциативная архитектура кэша позволяет каждому блоку кэшируемой памяти претендовать на одну из нескольких строк кэша, объединенных в набор (set).
Кэш-память процессора
Можно считать, что в этой архитектуре есть несколько параллельно и согласованно работающих каналов прямого отображения, где контроллеру кэша приходится принимать решение о том, в какую из строк набора помещать очередной блок данных. В простейшем случае каждый блок памяти может помещаться в одну из двух строк (Two Way Set-Associative Cache — двухканальный наборно – ассоциативный кэш). Такой кэш должен содержать два банка памяти тегов. Номер набора (индекс), в котором может отображаться затребованный блок данных, однозначно определяется средней частью адреса (как номер строки в кэше прямого отображения). Строка набора, отображающая требуемый блок, определяется сравнением тегов (как и в ассоциативном кэше), параллельно выполняемым для всех каналов кэша. Кроме того, с каждым набором должен быть связан признак, определяющий строку набора, подлежащую замещению новым блоком данных в случае кэш-промаха (на рисунке 3.26 в ее сторону указывает стрелка). Кандидатом на замещение обычно выбирается строка, к которой дольше всего не обращались (алгоритм LRU — Least Recently Used). При относительно большом количестве каналов (строк в наборе) прибегают к некоторому упрощению — алгоритм Pseudo-LRU для четырех строк (Four Way Set Associative Cache) позволяет принимать решения, используя всего 3 бита.
Возможно также применение алгоритма замещения FIFO (первым вошел — первым вышел) или даже случайного (random) замещения, что проще, но менее эффективно. Наборно-ассоциативная архитектура широко применяется для первичного кэша современных процессоров.
 |
| Рисунок 3.26 – Двухканальный наборно – ассоциативный кэш |
Объем кэшируемой памяти определяется так же, как и в предыдущем варианте, но здесь фигурируют объем одного банка (а не всего кэша) и разрядность относящихся к нему ячеек тега.
Ассоциативный кэш
В отличие от предыдущих, у полностью ассоциативного кэша любая его строка может отображать любой блок памяти, что существенно повышает эффективность использования его ограниченного объема. При этом все биты адреса кэшированного блока, за вычетом битов, определяющих положение (смещение) данных в строке, хранятся в памяти тегов. В такой архитектуре для определения наличия затребованных данных в кэш-памяти требуется сравнение со старшей частью адреса тегов всех строк, а не одной или нескольких, как при прямом отображении или наборно-ассоциативной архитектуре. Естественно, последовательный перебор ячеек памяти тегов отпадает — на это может уйти слишком много времени. Остается параллельный анализ всех ячеек, что является сложной аппаратной задачей, которая пока решена только для небольших объемов первичного кэша в некоторых процессорах.
Лекция 12
Предыдущая33343536373839404142434445464748Следующая
Дата добавления: 2016-02-24; просмотров: 280;
ПОСМОТРЕТЬ ЕЩЕ:
На главную -> MyLDP -> Тематический каталог -> Аппаратное обеспечение
Что каждый программист должен знать о памяти.
Часть 2: Кэш-память процессора
Оригинал: «Memory part 2: CPU caches»
Автор: Ulrich Drepper
Дата публикации: October 1, 2007
Перевод: Н.Ромоданов
Дата перевода: апрель 2012 г.
3.3 Подробности реализации кэш-памяти процессора
Разработчики кэш-памяти столкнулись с проблемой, состоящей в том, что потенциально в кэш-памяти может оказаться любая ячейка огромной основной памяти. Если рабочий набор данных, используемых в программе, достаточно большой, то это означает, что за каждое место в кэш-памяти будут соревноваться многие фрагменты основной памяти. Как ранее уже сообщалось, нередко соотношение между кэш-памятью и основной памятью составляет 1 к 1000.
3.3.1 Ассоциативность
Можно было бы реализовать кэш-память, в которой каждая кэш-строка может хранить копию любой ячейки памяти. Это называется полностью ассоциативной кэш-памятью (fully associative cache). Чтобы получить доступ к кэш-строке, ядро процессора должно было бы сравнить теги всех до единой кэш-строк с тегом запрашиваемого адреса. Тег должен будет хранить весь адрес, который не будет указываться смещение в кэш-строке (это означает, что значение S, показанное на рисунке в разделе 3.2, будет равно нулю).
Есть кэш-память, которая реализована подобным образом, но взглянуть на размеры кэш-памяти L2, используемой в настоящее время, то видно, что это непрактично. Учтите, что 4 Мб кэш-памяти с кэш-строками размером в 64Б должна иметь 65 536 записей. Чтобы получить адекватную производительность, логические схемы кэш-памяти должны быть в состоянии в течение нескольких циклов выбрать из всех этих записей ту, которая соответствует заданному тегу. Затраты на реализацию такой схемы будут огромными.
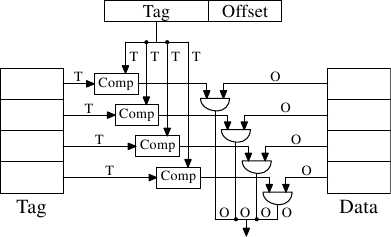
Рис.3.5: Схематическое изображение полностью ассоциативной кэш-памяти
Для каждой кэш-строки требуется, чтобы компаратор выполнил сравнение тега большого размера (заметьте, S равно нулю). Буква, стоящая рядом с каждым соединением, обозначает ширину соединения в битах. Если ничего не указано, то ширина соединения равна одному биту. Каждый компаратор должен сравнивать два значения, ширина каждого из которых равна Т бит. Затем, исходя из результата, должно выбираться и стать доступным содержимое соответствующей кэш-строки. Для этого потребуется объединить столько наборов линий данных О, сколько есть сегментов кэш-памяти (cache buckets). Число транзисторов, необходимых для реализации одного компаратора будет большим в частности из-за того, что компаратор должен работать очень быстро. Итеративный компаратор использовать нельзя. Единственный способ сэкономить на количестве компараторов, это снизить их число с помощью итеративного сравнения тегов. Это не подходит по той же самой причине, по которой не подходят итеративные компараторы: на это потребуется слишком много времени.
Полностью ассоциативная кэш-память практична для кэш-памяти малого размера (например, кэш-память TLB в некоторых процессорах Intel является полностью ассоциативной), но эта кэш-память должна быть небольшой — действительно небольшой. Речь идет максимум о нескольких десятках записей.
Для кэш-памяти L1i, L1d и кэш-памяти более высокого уровня необходим другой подход. Все, что можно сделать, это ограничить поиск. В самом крайнем случае каждый тег отображается точно в одну кэш-запись.
Как узнать кэш процессора?
Расчет прост: для кэш-памяти 4MB/64B с 65 536 записями мы можем напрямую обращаться к каждому элементу и использовать для этого с 6-го по 21-й биты адреса (16 битов). Младшие 6 битов являются индексом кэш-строки.
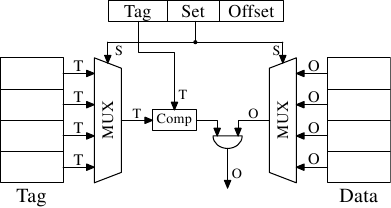
Рис.3.6: Схематическое изображение кэш-памяти с прямым отображением
Как видно из рисунка 3.6 реализация такой кэш-памяти с прямым отображением (direct-mapped cache) может быть быстрой и простой. Для нее требуется только один компаратор, один мультиплексор (на этой схеме приведены два, поскольку тег и данные разделены, но это не является строгим конструктивным требованием) и некоторая логическая схема для выбора контента, содержащего действительно допустимые кэш-строки. Компаратор сложный из-за требований, касающихся скорости, но теперь он только один; в результате можно потратить больше усилий, чтобы сделать его более быстрым. Реальная сложность такого подхода заключена в мультиплексорах. Количество транзисторов в простом мультиплексоре растет по закону O(log N), где N является количеством кэш-строк. Это приемлемо, но может получиться медленный мультиплексор, и в этом случае скорость можно увеличить, если потратиться на транзисторы в мультиплексорах и для увеличения скорости распараллелить часть работы. Общее количество транзисторов будет расти медленное в сравнении с ростом размера кэш-памяти, что делает это решение очень привлекательным. Но у такого подхода есть недостаток: он работает только в случае, если адреса, используемые в программе, равномерно распределены относительно битов, используемых для прямого отображения. Если это не так, и это обычно бывает, некоторые кэш-записи используются активно и, поэтому, неоднократно высвобождаются, в то время как другие практически вообще не используются, либо остаются пустыми.
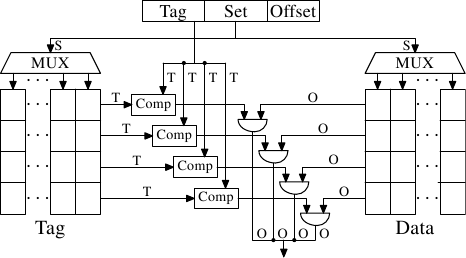
Рис.3.7: Схематическое изображение кэш-памяти с множественной ассоциативностью
Эту проблему можно решить с помощью кэш-памяти с множественной ассоциативностью (set associative). Кэш-память с множественностью ассоциативностью сочетает в себе черты кэш-памяти с полной ассоциативностью и кэш-памяти с прямым отображением, что позволяет в значительной степени избежать недостатков этих решений. На рис.3.7 показана схема кэш-памяти с множественной ассоциативностью. Память под теги и под данные разделена на наборы, выбор которых осуществляется в соответствие с адресом. Это похоже на кэш-память с прямым отображением. Но вместо того, чтобы для каждого значения из набора использовать отдельный элемент, один и тот же набор используется для кэширования некоторого небольшого количества значений. Теги для всех элементов набора сравниваются параллельно, что похоже на функционирование полностью ассоциативной кэш-памяти.
Результатом является кэш-память, которая достаточно устойчива к промахам из-за неудачного или преднамеренного выбора адресов с одними и теми же номерами наборов в одно и то же время, а размер кэш-памяти не ограничен количеством компараторов, которые могут работать параллельно. Если кэш-память увеличивается (смотрите рисунок), то увеличивается только количество столбцов, а не количество строк. Число строк увеличивается только в том случае, если повышается ассоциативность кэш-памяти. Сегодня процессоры для кэш-памяти L2 используют уровни ассоциативности до 16 и выше. Для кэш-памяти L1 обычно используется уровень, равный 8.
Таблица 3.1: Влияние размера кэш-памяти, ассоциативности и размера кэш-строки
| Размер кэш-памяти L2 |
Ассоциативность | |||||||
|---|---|---|---|---|---|---|---|---|
| Прямое отображение | 2 | 4 | 8 | |||||
| CL=32 | CL=64 | CL=32 | CL=64 | CL=32 | CL=64 | CL=32 | CL=64 | |
| 512k | 27 794 595 | 20 422 527 | 25 222 611 | 18 303 581 | 24 096 510 | 17 356 121 | 23 666 929 | 17 029 334 |
| 1M | 19 007 315 | 13 903 854 | 16 566 738 | 12 127 174 | 15 537 500 | 11 436 705 | 15 162 895 | 11 233 896 |
| 2M | 12 230 962 | 8 801 403 | 9 081 881 | 6 491 011 | 7 878 601 | 5 675 181 | 7 391 389 | 5 382 064 |
| 4M | 7 749 986 | 5 427 836 | 4 736 187 | 3 159 507 | 3 788 122 | 2 418 898 | 3 430 713 | 2 125 103 |
| 8M | 4 731 904 | 3 209 693 | 2 690 498 | 1 602 957 | 2 207 655 | 1 228 190 | 2 111 075 | 1 155 847 |
| 16M | 2 620 587 | 1 528 592 | 1 958 293 | 1 089 580 | 1 704 878 | 883 530 | 1 671 541 | 862 324 |
Если у нас кэш-память 4MB/64B и 8-канальная ассоциативность, то в кэш-памяти у нас будет 8192 наборов и для адресации кэш-наборов потребуется только 13 битов тега. Чтобы определить, какая из записей (если таковая имеется) содержит в кэш-наборе адресуемую кэш-строку, потребуется сравнить 8 тегов. Это можно сделать за очень короткое время. Как видно из практики, в этом смысл есть.
В таблице 3.1 показано количество промахов кэш-памяти L2 для некоторой программы (в данном случае — для компилятора gcc, который, по мнению разработчиков ядра Linux, является наиболее важным бенчмарком) при изменении размера кэш-памяти, размера кэш-строки, а также значения множественной ассоциативности. В разделе 7.2 мы познакомимся с инструментальным средством, предназначенным для моделирования кэш-памяти, которое необходимо для этого теста.
Просто, если это еще не очевидно, взаимосвязь всех этих значений в том, что размер кэш-памяти равен
размер кэш-строки х ассоциативность х количество множеств
Отображение адресов в кэш-память вычисляется как
O = log2 от размера кэш-строки
S = log2 от числа наборов
согласно рисунку в разделе 3.2.
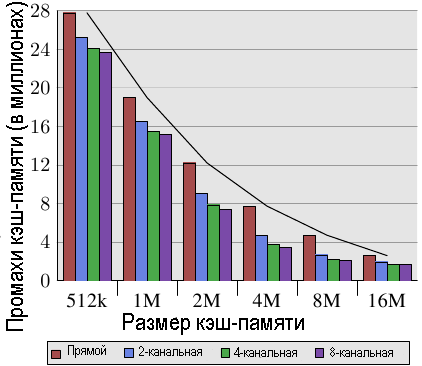
Рис.3.8: Размер кэш-памяти и уровень ассоциативности (CL=32)
Рис. 3.8 делает данные таблицы более понятными. На рисунке приведены данные для кэш-строки фиксированного размера, равного 32 байта. Если посмотреть на цифры для заданного размера кэш-памяти, то видно, что ассоциативность действительно может существенно помочь сократить число промахов кэш-памяти. Для кэш-памяти размером 8 МБ при переходе от прямого отображения на кэш-память с 2-канальной ассоциативностью экономится почти 44% кэш-памяти. В случае, если используется кэш-память со множественной ассоциативностью, то процессор может хранить в кэш-памяти рабочий набор большего размера, чем в случае кэш-памяти с прямым отображением.
В литературе иногда можно прочитать, что введение ассоциативности имеет тот же самый эффект, как удвоение размера кэш-памяти. Это, как это видно для случая перехода от кэш-памяти размером 4 МБ к кэш-памяти размером 8 МБ, верно в некоторых крайних случаях. Но это, конечно, не верно при последующем увеличении ассоциативности. Как видно из данных, последующее увеличение ассоциативности дает существенно меньший выигрыш. Нам, однако, не следует абсолютно не учитывать этот факт. В программе нашего примера пик использования памяти равен 5,6 MB. Так что при размере кэш-памяти в 8 Мб, что те же самые кэш-наборы будут использоваться многократно (более, чем дважды).
С увеличением рабочего набора экономия может увеличиться, поскольку, как мы видим, при меньших размерах кэш-памяти преимущество от использования ассоциативности будет больше.
В целом, увеличение ассоциативность кэш-памяти выше 8, как кажется, дает слабый эффект при одном потоке рабочей нагрузки. С появлением многоядерных процессоров, которые используют общую кэш-память L2, ситуация меняется. Теперь у вас в основном есть две программы, которые обращаются к одной и той же кэш-памяти, в результате чего на практике эффект от использования ассоциативности должен увеличиться вдвое (или в четыре раза для четырехядерных процессоров). Таким образом, можно ожидать, что с увеличением числа ядер, ассоциативность общей кэш-памяти должна расти. Как это станет делать невозможным (16-канальную ассоциативность реализовывать уже трудно) разработчики процессоров начнут использовать общую кэш-память уровня L3 и далее, в то время как кэш-память уровня L2 будет, потенциально, совместно использоваться некоторым подмножеством ядер.
Другой эффект, который мы можем увидеть на рис.3.8, это то, как увеличение размера кэш-памяти способствует увеличению производительности. Эти данные нельзя интерпретировать без знания размера рабочего набора. Очевидно, что кэш-память такого размера, как основная память, должен привести к лучшим результатам, нежели кэш-память меньшего размера, так что в целом нет никаких ограничений на увеличение размера кэш-памяти и получения ощутимых преимуществ.
Как уже упоминалось выше, размер рабочего набора в его пиковом значении равен 5,6 Мб. Это значение не позволяет нам рассчитать размер памяти, который бы принес максимальную выгоду, но позволяет оценить этот размер. Проблема в том, что вся память используется не непрерывно и, следовательно, у нас есть конфликты даже при наличии 16M кэш-памяти и рабочего набора, размер которого равен 5,6M (вспомните преимущество 2-канальной ассоциативной кэш-памяти размером в 16 МБ над версией с прямым отображением). Но можно с уверенностью сказать, что при такой нагрузке преимущество кэш-памяти размером в 32 МБ будет несущественным. Однако кто сказал, что рабочий набор должен оставаться неизменным? С течением времени рабочие нагрузки растут и то же самое должно касаться размера кэш-памяти. Когда покупаются машины и принимается решение, за какой размер кэш-памяти требуется заплатить, стоит измерить размер рабочего набора. Почему это важно, можно увидеть на рис. 3.10.
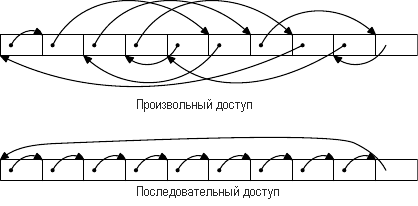
Рис.3.9: Размещение памяти, используемой при тестировании
Запускается два типа тестов. В первом тесте элементы обрабатываются последовательно. В тестовой программе используется указатель , но элементы массива связаны друг с другом, так что они обходятся в том порядке, в котором они находятся в памяти. Этот вариант показан в нижней части рис.3.9. Есть одна обратная ссылка, идущая от последнего элемента. Во втором тесте (верхняя часть рисунка) элементы массива обходятся в произвольном порядке. В обоих случаях элементы массива образуют циклический односвязный список.
Если вам понравилась статья, поделитесь ею с друзьями:
Что такое кэш-память?
Кэш-память — это высокоскоростная память произвольного доступа, используемая процессором компьютера для временного хранения информации. Она увеличивает производительность, поскольку хранит наиболее часто используемые данные и команды «ближе» к процессору, откуда их можно быстрее получить
Кэш-память напрямую влияет на скорость вычислений и помогает процессору работать с более равномерной загрузкой. Представьте себе массив информации, используемой в вашем офисе. Небольшие объемы информации, необходимой в первую очередь, скажем список телефонов подразделений, висят на стене над вашим столом. Точно так же вы храните под рукой информацию по текущим проектам. Реже используемые справочники, к примеру, городская телефонная книга, лежат на полке, рядом с рабочим столом. Литератур
а, к которой вы обращаетесь совсем редко, занимает полки книжного шкафа.
Компьютеры хранят данные в аналогичной иерархии. Когда приложение начинает работать, данные и команды переносятся с медленного жесткого диска в оперативную память произвольного доступа (Dynamic Random Access Memory — DRAM), откуда процессор может быстро их получить. Оперативная память выполняет роль кэша для жесткого диска.
Причины внедрения кэш-памяти
Явная необходимость в кэш-памяти при проектировании массовых ЦП проявилась в начале 1990-х гг., когда тактовые частоты ЦП значительно превысили частоты системных шин, и, в частности, шины памяти. В настоящее время частоты серверных ЦП достигают почти 4 ГГц, а оперативной памяти, массово применяемой в серверах, — только 400 МГц (200 МГц с удвоением благодаря передаче по обоим фронтам сигнала). В этой ситуации при прямом обращении к памяти функциональные устройства ЦП значительную часть времени простаивают, ожидая доставки данных. В какой-то мере проблемы быстродействия оперативной памяти могут быть решены увеличением разрядности шины памяти, но даже в серверах младшего уровня нередко встречается 8-16 гнезд для модулей памяти, поэтому такое решение усложняет дизайн системной платы. Проложить же 256- или даже 512-бит шину к расположенной внутри кристалла ЦП кэш-памяти сравнительно несложно. Таким образом, эффективной альтернативы кэш-памяти в современных высокопроизводительных системах не существует.
Уровень за уровнем
Хотя оперативная память намного быстрее диска, тем не менее и она не успевает за потребностями процессора. Поэтому данные, которые требуются часто, переносятся на следующий уровень быстрой памяти, называемой кэш-памятью второго уровня. Она может располагаться на отдельной высокоскоростной микросхеме статической памяти (SRAM), установленной в непосредственной близости от процессора (в новых процессорах кэш-память второго уровня интегрирована непосредственно в микросхему процессора.
На более высоком уровне информация, используемая чаще всего (скажем, команды в многократно выполняемом цикле), хранится в специальной секции процессора, называемой кэш-памятью первого уровня. Это самая быстрая память.
Процессор Pentium III компании Intel имеет кэш-память первого уровня емкостью 32 Кбайт на микросхеме процессора и либо кэш-память второго уровня емкостью 256 Кбайт на микросхеме, либо кэш-память второго уровня емкостью 512 Кбайт, не интегрированную с процессором.
Когда процессору нужно выполнить команду, он сначала анализирует состояние своих регистров данных. Если необходимых данных в регистрах нет, он обращается к кэш-памяти первого уровня, а затем — к кэш-памяти второго уровня. Если данных нет ни в одной кэш-памяти, процессор обращается к оперативной памяти. И только в том случае, если нужных данных нет и там, он считывает данные с жесткого диска.
Когда процессор обнаруживает данные в одном из кэшей, это называют «попаданием»; неудачу называют «промахом». Каждый промах вызывает задержку, поскольку процессор будет пытаться обнаружить данные на другом, более медленном уровне. В хорошо спроектированных системах с программными алгоритмами, которые выполняют предварительную выборку данных до того, как они потребуются, процент «попаданий» может достигать 90.
Для процессоров старшего класса на получение информации из кэш-памяти первого уровня может уйти от одного до трех тактов, а процессор в это время ждет и ничего полезного не делает. Скорость доступа к данным из кэш-памяти второго уровня, размещаемой на процессорной плате, составляет от 6 до 12 циклов, а в случае с внешней кэш-памятью второго уровня — десятки или даже сотни циклов.
Внутренний кэш
Внутренне кэширование обращений к памяти применяется в процессорах, начиная с 486-го. С кэшированием связаны новые функции процессоров, биты регистров и внешние сигналы.
Процессоры 486 и Pentium имеют внутренний кэш первого уровня, в Pentium Pro и Pentium II имеется и вторичный кэш. Процессоры могут иметь как единый кэш инструкций и данных, так и общий. Выделенный кэш инструкций обычно используется только для чтения. Для внутреннего кэша обычно используется наборно-ассоциативная архитектура.
Работу кэша рассмотрим на примере четырехканального наборно-ассоциативного кэша процессора 486, его физическая структура приведена на рис.1. Кэш является несекторированным – каждый бит достоверности (Valid bit) относится к целой строке, так что стока не может являться “частично достоверной”.
Работу внутренней кэш-памяти характеризуют следующие процессы: обслуживание запросов процессора на обращение к памяти, выделение и замещение строк для кэширования областей физической памяти, обеспечение согласованности данных внутреннего кэша и оперативной памяти, управление кэшированием.
Любой внутренний запрос процессора на обращение к памяти направляется на внутренний кэш. Теги четырех строк набора, который обслуживает данный адрес, сравниваются со старшими битами запрошенного физического адреса. Если адресуемая область представлена в строке кэш-памяти (случая попадания –cache hit), запрос на чтение обслуживается только кэш-памятью, не выходя на внешнюю шину. Запрос на запись модифицирует данную строку, и в зависимости от политики записи либо сразу выходит на внешнюю шину (при сквозной записи), либо несколько позже (при использовании алгоритма обратной записи).


4 Ru
. . .
. . .
. . .
. . .
. . .
Теги действительности
Канал 1
Канал 4
Диспетчер
Рис 1. Структура первичного кэша процессора 486
В случае промаха (Cache Miss) запрос на запись направляется только на внешнюю шину, а запрос на чтение обслуживается сложнее. Если этот зарос относится к кэшируемой области памяти, выполняется цикл заполнения целой строки кэша – все 16 байт (32 для Pentium) читаются из оперативной памяти и помещаются в одну из строк кэша, обслуживающего данный адрес.
Если затребованные данные не укладываются в одной строке, заполняется и соседняя. Заполнение строки процессор старается выполнить самым быстрым способом – пакетным циклом с 32-битными передачами (64-битными для Pentium и старше).
Внутренний запрос процессора на данные удовлетворяется сразу, как только затребованные данные считываются из ОЗУ – заполнение строки до конца может происходить параллельно с обработкой полученных данных. Если в наборе, который обслуживает данный адрес памяти, имеется свободная строка (с нулевым битом достоверности), заполнена будет она и для нее установится бит достоверности. Если свободных строк в наборе нет, будет замещена строка, к которой дольше всех не было обращений.
Как узнать кэш?
Выбор строки для замещения выполняется на основе анализа бит LRU (Least Recently Used) по алгоритму “псевдо-LRU”. Эти биты (по три на каждый из наборов) модифицируются при каждом обращении к строке данного набора (кэш-попадании или замещении).
Таким образом, выделение и замещение строк выполнятся только кэш-промахов чтения, при промахах записи заполнение строк не производится. Если затребованная область памяти присутствует в строке внутреннего кэша, то он обслужит этот запрос. Управлять кэшированием можно только на этапе заполнения строк; кроме того, существует возможность их аннулирования – объявления недостоверными и очистка всей кэш-памяти.
Очистка внутренней кэш-памяти при сквозной записи (обнуление бит достоверности всех строк) осуществляется внешним сигналом FLUSH# за один такт системной шины (и, конечно же, по сигналу RESET). Кроме того, имеются инструкции аннулирования INVD и WBINVD. Инструкция INVDаннулирует строки внутреннего кэша без выгрузки модифицированных строк, поэтому ее неосторожное использование при включенной политике обратной записи может привести к нарушению целостности данных в иерархической памяти. Инструкция WBINVD предварительно выгружает модифицированные строки в основную память (при сквозной записи ее действие совпадает с INVD). При обратной записи очистка кэша подразумевает и выгрузку всех модифицированных строк в основную память. Для этого, естественно, может потребоваться и значительное число тактов системной шины, необходимых для проведения всех операций записи.
Аннулирование строк выполняется внешними схемами – оно необходимо в системах, у которых в оперативную память запись может производить не только один процессор, а и другие контроллеры шины – процессор или периферийные контроллеры. В этом случае требуются специальные средства для поддержания согласованности данных во всех ступенях памяти – в первичной и вторичной кэш-памяти и динамического ОЗУ. Если внешний (по отношению к рассматриваемому процессору) контроллер выполняет запись в память, процессору должен быть подан сигнал AHOLD. По этому сигналу процессор немедленно отдает управление шиной адреса A[31:4], на которой внешним контроллером устанавливается адрес памяти, сопровождаемый стробом EADS#. Если адресованная память присутствует в первичном кэше, процессор аннулирует строку – сбрасывает бит достоверности этой строки (она освобождается). Аннулирование строки процессор выполняет в любом состоянии.
Смешанная и разделенная кэш-память.
Внутренняя кэш-память использовалась ранее как для инструкций(команд), так и для данных. Такая память называлась смешанной, а ее архитектура – Принстонской, в которой в единой кэш-памяти, в соответствии с классическими принципами фон Неймана, хранились и команды и данные.
Сравнительно недавно стало обычным разделять кэш-память на две – отдельно для инструкций и отдельно для данных.
Преимуществом смешанной кэш-памяти является то, что при заданном объеме, ей свойственна более высокая вероятность попаданий, по сравнению с разделенной, поскольку в ней автоматически устанавливается оптимальный баланс между инструкциями и данными.
Если в выполняемом фрагменте программы обращения к памяти связаны, в основном, с выборкой инструкций, а доля обращений к данным относительно мала, кэш-память имеет тенденцию заполнения инструкциями и наоборот.
С другой стороны, при раздельной кэш-памяти, выборка инструкций и данных может производиться одновременно, при этом исключаются возможные конфликты. Последнее особенно существенно в системах, использующих конвейеризацию команд, где процессор извлекает команды с опережением и заполняет ими буфер или конвейер.
Статическая и динамическая память
В каждом современном ЦП предусмотрено некоторое количество статической памяти, работающей на частоте ядра. Именно статической, поскольку использование динамической памяти в этих целях представляется крайне нерациональным.
Одна ячейка статической памяти состоит из шести транзисторов и двух резисторов (для техпроцессов с проектными нормами до 0,5 мкм могли быть использованы только четыре транзистора на одну ячейку, с дополнительным слоем поликремния и с более жесткими ограничениями по максимальной тактовой частоте), в то время как аналогичная структура динамической памяти состоит из одного транзистора и одного конденсатора.
Быстродействие статической памяти намного выше (емкость, используемая в динамической памяти, имеет определенную скорость зарядки до требуемого уровня, определяющую «частотный потолок»), но из-за большего количества составляющих элементов она существенно дороже в производстве и отличается более высоким энергопотреблением. Битовое значение ячейки статической памяти характеризуется состоянием затворов транзисторов, а динамической — уровнем заряда конденсатора. Так как конденсаторы имеют свойство с течением времени разряжаться, то для поддержания их состояния требуется регулярная перезарядка (для современных микросхем динамической памяти — приблизительно 15 раз в секунду). Кроме того, при операции чтения из ячейки динамической памяти конденсатор разряжается, т. е. ячейка утрачивает свой первоначальный заряд, а следовательно должна быть перезаряжена.
Страницы: следующая →
12Смотреть все
Похожие страницы:
-
Типы кэш-памяти
Реферат >> Информатика
… , сочетающий достоинства прямого и ассоциативного способов. Кэш—память ( и тегов и данных) разбивается на некоторое … увеличения объема встроенного кэша может заключаться в том, что кэш—память в современных процессорах работает …
-
Память компьютера (3)
Контрольная работа >> Информатика
… быстродействующих компьютерах используется специальная, сверхбыстродействующая кэш—память, которая располагается как бы между … небольшую внутреннюю кэш—память, поэтому для однозначности терминологии в технической литературе, кэш—память, размещаемую на …
-
Устройство кэш-памяти и стратегии кэширования
Реферат >> Информатика
Оглавление Понятие кэш-памяти————————————————————————————3 Уровни кэша—————————————————————————————3 Кэш—память микропроцессоров Pentium III …
-
Зовнішні запам ятовуючі пристрої пам ять комп ютера
Реферат >> Астрономия
… ігаючи потрібну інформацію в кэшпам‘яті, робота з якої дозволяє … нформації може містити кэшпам‘ять. Чим більша кэшпам‘ять, тим більше … ситуація, коли є 1 байт кэшпам‘яті, теж не має практичного … до нуля. Практично, діапазон кэшпам‘яті, що використається, …
-
Устройства хранения информации компьютера. Внутренняя и внешняя память вомпьютера
Реферат >> Информатика
… = 4096 Мбайт = 4 Гбайт. Кэш—памятьКэш—память (cache), или сверхоперативная память, — очень быстрое ЗУ небольшого … в ближайшее время процессору, и переписывает их в кэш—память. Кэш—память реализуется на микросхемах статической памяти …
Хочу больше похожих работ…
FILED UNDER : IT