admin / 31.03.2018
Диаграмма потоков данных
Содержание
- Практикум 2.1. Классические методы анализа. Структурный анализ на основе DFD — диаграмм
- Задание 1. Общие сведения
- Задание 2. Знакомство с компонентами диаграммы потоков данных (DFD) в BPwin
- Задание 3. Знакомство со средствами создания DFD в среде BPwin
- Задание 4. Создание компонентов контекстной диаграммы.
- Задание 5. Декомпозиция контекстной диаграммы
- Задание 6. Самостоятельная работа
- Задание 7. Оформление отчета
- Задание 8. Анализ информационных процессов при снятии денег со счета в банке.
- Задание 9. Декомпозиция контекстной диаграммы.
- Задание 10. Альтернативные процессы.
- Контрольные вопросы
- Версия для печати
- Моделирование потоков данных. Диаграммы DFD.
- Версия для печати
- Studepedia.org — это Лекции, Методички, и много других полезных для учебы материалов
- СИСТЕМА СПЕЦИАЛЬНЫХ УПРАЖНЕНИЙ ДЛЯ ОТРАБОТКИ ПОЛНОЦЕННЫХ НАВЫКОВ ЧТЕНИЯ И ПИСЬМА (Педагогика)
- Обучаем читать и писать без ошибок: Комплекс упражнений (Педагогика)
- ИСТОРИЯ ПСИХОЛОГИИ от античности до середины ХХ в. 1 страница (Психология)
- СОЦИОЛОГИЯ (Социология)
- Методика развития связной речи у детей с системным недоразвитием речи (Педагогика)
- Жизнь Галилея 1 страница (Философия)
- Чудо голодания 1 страница (Медицина, Здоровье)
- Эрих Фромм. Мужчина и женщина (Психология)
- Покупка автомобиля (Финансы, Менеджмент)
- Назначения зубчатых колес и передач. (Машиностроение)
- ЗОЛОТОЙ ЛОТОС, СБОРНИК ФАНТАСТИЧЕСКИХ ПОВЕСТЕЙ И РАССКАЗОВ (Литература)
- Живопись XX Века (Культура, Искусство)
- Проектная разработка автоматизированной линии кормления животных с использованием личинок насекомых в качестве живого корма (Агрономия, Сельское хозяйство)
- О культуре научного исследования — 1 страница (Психология)
- Жак Фреско, Роксана Медоуз — Все лучшее, что не купишь за деньги (Философия)
- Статья 5. Независимость профсоюзов (Право)
- Эрнст Неизвестный. Становление стиля. 1950-1960 гг (Культура, Искусство)
- Запрос о предоставлении сведений (Право)
- Учет анатомо-физиологических особенностей детей в организации их двигательной деятельности (Спорт)
- Пролог на небесах (Литература)
- Тема 1. Базы данных. Вопрос №14
- Семья – это мир, в котором нам уютно (Педагогика)
- ЭПИГРАФ 1 страница (Изучение языков)
- Основные характеристики электрического тока. (Электроника)
- Спроектировать локально-вычислительную сеть (ЛВС) компании (Информатика)
- Работа с записями и одномерными массивами. (Информатика)
- Простые геометрические вычисления. (Математика)
- Простые вычисления с числами целых и вещественных типов. (Информатика)
- Структура предприятия и организационная структура управления (Финансы, Менеджмент)
- Органы растений (Биология, Зоология, Анатомия)
- Моделирование бизнес-процессов средствами BPwin (часть 2)
- DFD — диаграмма потоков данных
- Диаграммы потоков данных
Практикум 2.1. Классические методы анализа. Структурный анализ на основе DFD — диаграмм
|
Цель: Ознакомиться с технологией построения DFD — диаграмм с помощью CASE – средства BPWIN Задачи:
|
Задание 1. Общие сведения
Задание 2. Знакомство с компонентами диаграммы потоков данных ( DFD ) в BPwin
Задание 3. Знакомство со средствами создания DFD в среде BPWIN
Задание 4. Создание компонентов контекстной диаграммы
Задание 5. Декомпозиция контекстной диаграммы
Задание 6. Самостоятельная работа
Задание 7. Оформление отчета
Задание 8. Анализ информационных процессов при снятии со счета в банке денег
Задание 9. Декомпозиция контекстной диаграммы
Задание 10. Альтернативные процессы
Контрольные вопросы
Задание 1. Общие сведения
Ознакомьтесь с изложенными ниже общими сведениями.
Общие сведения
Диаграммы потоков данных (DFD) являются основным средством моделирования функциональных требований к проектируемой системе. С их помощью эти требования представляются в виде иерархии функциональных компонентов (процессов), связанных потоками данных.
Источники информации (внешние сущности) порождают информационные потоки (потоки данных), переносящие информацию к подсистемам или процессам. Те, в свою очередь, преобразуют информацию и порождают новые потоки, которые переносят информацию к другим процессам или подсистемам, накопителям данных или внешним сущностям — потребителям информации.
Состав диаграмм потоков данных
Основными компонентами диаграмм потоков данных являются:
- внешние сущности;
- системы и подсистемы;
- процессы;
- накопители данных;
- потоки данных.
Внешняя сущность — это материальный объект или физическое лицо, представляющие собой источник или приемник информации, например, заказчики, персонал, поставщики, клиенты, склад. Определение некоторого объекта или системы в качестве внешней сущности указывает на то, что они находятся за пределами границ анализируемой системы.
Построение иерархии диаграмм потоков данных
Главная цель построения иерархии DFD – сделать требования к системе ясными и понятными на каждом уровне детализации, а также разбить эти требования на части с точно определенными отношениями между ними.
Для этого целесообразно:
- размещать на каждой диаграмме от 3 до 7 процессов. Верхняя граница соответствует человеческим возможностям одновременного восприятия и понимания структуры сложной системы с множеством внутренних связей, нижняя граница выбрана по соображениям здравого смысла: нет необходимости детализировать процесс диаграммой, содержащей всего один процесс или два;
- не загромождать диаграммы не существенными на данном уровне деталями;
- декомпозицию потоков данных осуществлять параллельно с декомпозицией процессов. Эти две работы должны выполняться одновременно, а не одна после завершения другой;
- выбирать понятные имена процессов и потоков, не использовать аббревиатуры.
Построение контекстных диаграмм – первый шаг построения DFD. В центре контекстной диаграммы находится главный процесс, соединенный с приемниками и источниками информации, посредством которых с системой взаимодействуют пользователи и другие внешние системы.
Перед построением контекстной DFD анализируют внешние события (внешние сущности), оказывающие влияние на функционирование системы. Количество потоков на контекстной диаграмме должно быть по возможности небольшим, поскольку каждый из них может быть в дальнейшем разбит на несколько потоков на следующих уровнях диаграммы.
Для проверки контекстной диаграммы можно составить список событий. Список событий – это описания действий внешних сущностей (событий) и соответствующих реакций системы на события. Одному (или более) потоку данных соответствует одно событие: входные потоки интерпретируются как воздействия, а выходные потоки – как реакции системы на входные потоки.
Главный процесс не раскрывает структуры сложной системы (которая имеет большое количество внешних сущностей, многофункциональна, которую можно разбить на подсистемы).
Для сложных систем строится иерархия контекстных диаграмм. При этом контекстная диаграмма верхнего уровня содержит набор подсистем, соединенных потоками данных.
Иерархия контекстных диаграмм определяет взаимодействие основных функциональных подсистем как между собой, так и с внешними входными и выходными потоками данных и внешними объектами (источниками и приемниками информации), с которыми взаимодействует система.
После построения контекстных диаграмм полученную модель следует проверить на полноту исходных данных об объектах системы и изолированность объектов (отсутствие информационных связей с другими объектами).
Для каждой подсистемы, присутствующей на контекстных диаграммах, выполняется ее детализация при помощи DFD. Это можно сделать путем построения диаграммы для каждого события. Каждое событие представляется в виде процесса с соответствующими входными и выходными потоками, накопителями данных, внешними сущностями и ссылки на другие процессы для описания связей между этим процессом и его окружением. Затем все построенные диаграммы сводятся в одну диаграмму нулевого уровня.
При детализации процессов нужно выполнять следующие правила:
• правило балансировки – детализирующая диаграмма в качестве внешних источников или приемников данных может иметь только те компоненты (подсистемы, процессы, внешние сущности, накопители данных), с которыми имеют информационную связь детализируемые подсистема или процесс на родительской диаграмме;
• правило нумерации – при детализации процессов должна поддерживаться их иерархическая нумерация. Например, процессы, детализирующие процесс с номером 12, получают номера 12.1, 12.2, 12.3 и т. д.
Спецификация процесса должна формулировать его основные функции таким образом, чтобы в дальнейшем специалист, выполняющий реализацию проекта, смог выполнить их или разработать соответствующую программу.
Спецификация является конечной вершиной иерархии DFD. Решение о завершении детализации процесса и использовании спецификации принимается аналитиком исходя из следующих критериев:
- наличия у процесса относительно небольшого количества входных и выходных потоков данных (2-3 потока);
- возможности описания преобразования данных процессом в виде последовательного алгоритма;
- выполнения процессом единственной логической функции преобразования входной информации в выходную;
- возможности описания логики процесса при помощи спецификации небольшого объема (не более 20 – 30 строк).
Спецификации должны удовлетворять следующим требованиям:
- для каждого процесса нижнего уровня должна существовать одна и только одна спецификация;
- спецификация должна определять способ преобразования входных потоков в выходные;
- нет необходимости (по крайней мере на стадии формирования требований) определять метод реализации этого преобразования;
- спецификация должна стремиться к ограничению избыточности -не следует переопределять то, что уже было определено на диаграмме;
- набор конструкций для построения спецификации должен быть простым и понятным.
Фактически спецификации представляют собой описания алгоритмов задач, выполняемых процессами. Спецификации содержат номер и/или имя процесса, списки входных и выходных данных и тело (описание) процесса, являющееся спецификацией алгоритма или операции, трансформирующей входные потоки данных в выходные. Известно большое количество разнообразных методов, позволяющих описать тело процесса. Соответствующие этим методам языки могут варьироваться от структурированного естественного языка или псевдокода до визуальных языков проектирования.
Задание 2. Знакомство с компонентами диаграммы потоков данных (DFD) в BPwin
Ознакомьтесь с результатом использования DFD для описания процесса отгрузки горючего (рис.1).
На диаграмме продемонстрированы процессы, преобразующие входные данные в выходные.
 |
Рис. 1. Диаграмма потоков данных процесса отгрузки горючего
Основными компонентами диаграммы потоков данных являются:
- процессы (изображаются в виде прямоугольников). Если прямоугольник имеет в левом верхнем углу треугольную отметку – он не имеет декомпозиции. Если отметки нет, то имеется диаграмма его декомпозиции. Названия прямоугольников отображают работу процесса (рис. 2):
 |
Рис.2. Изображение процесса
- потоки данных. Изображаются в виде стрелок (рис.3), входящих и исходящих в блоки процессов и других компонентов диаграммы. Стрелки имеют название, описывающее вид информации на входе или выходе какого-то из процессов. Поток данных определяет информацию, передаваемую через некоторое соединение от источника к приемнику:
 |
Рис. 3. Потоки данных
- внешние сущности – это материальный объект или физическое лицо, представляющие собой источник или приемник информации, например, заказчики, персонал, поставщики, клиенты, склад. Определение некоторого объекта или системы в качестве внешней сущности указывает на то, что они находятся за пределами границ анализируемой системы. В процессе анализа некоторые внешние сущности могут быть перенесены внутрь диаграммы анализируемой системы, если это необходимо, или, наоборот, часть процессов может быть вынесена за пределы диаграммы и представлена как внешняя сущность. Внешняя сущность обозначает объекты или процессы внешней среды, от которых поступают запросы или данные, для которых формируются документы и выводится информация. Изображается квадратом или прямоугольником с тенью (рис. 4). Название отображает объект:
 |
Рис. 4. Внешняя сущность
- накопитель данных — это абстрактное устройство для хранения информации, которую можно в любой момент поместить в накопитель и через некоторое время извлечь, причем способы помещения и извлечения могут быть любыми. Накопитель данных может быть реализован физически в виде микрофиши, ящика в картотеке, таблицы в оперативной памяти, файла на магнитном носителе и т. д. Накопитель данных на диаграмме потоков данных идентифицируется буквой D (рис. 5) и произвольным числом. Имя накопителя выбирается из соображения наибольшей информативности для проектировщика. Накопитель данных является прообразом будущей базы данных, и описание, хранящихся в нем данных должно быть увязано с информационной моделью (ERD). Накопители данных — хранилища информации, к которым можно обратиться за данными, или куда можно поместить преобразованные данные. Изображаются в виде прямоугольника с двойной чертой:
 |
Рис. 5. Изображение хранилища данных (накопителя)
Процессы, хранилища имеют номера. Подчиненные блоки отображают уровни иерархии в номерах (рис. 6).
Задание 3. Знакомство со средствами создания DFD в среде BPwin
- Запустите BPwin. Создайте новый файл командой File / New.
 |
Рис. 6. Выбор типа диаграммы
В появившемся диалоговом окне (рис. 6) поставьте переключатель в положение DFD. Задайте имя модели в поле Name. В появившемся окне на вкладке General задайте имя автора Author.
- Внимательно рассмотрите панель инструментов и рис. 7. Ознакомьтесь с инструментами создания диаграммы потоков данных.
 |
Рис. 7. Панель инструментов среды BPwin для создания диаграмм.
Задание 4. Создание компонентов контекстной диаграммы.
- Ознакомьтесь с описанием задачи.
Администрация больницы заказала разработку информационной системы для отдела приема пациентов и медицинского секретариата. Новая система предназначена для обработки данных о врачах, пациентах, приеме пациентов и лечении. Система должна выдавать отчеты по запросу врачей или администрации. В результате предпроектного обследования составлено следующее описание деятельности подразделений.
Перед приемом в больницу проводится встреча пациента и врача. Врач сообщает в отдел приема пациентов об ожидаемом приеме больного и передает данные о нем. Если пациент принят в больницу впервые, то до его приема в больницу его регистрируют — присваивают регистрационный номер и записывают его данные (фамилия, имя и отчество, адрес и дата рождения).
Спустя некоторое время врач оформляет в отделе приема пациентов прием больного. При этом определяется порядковый номер приема и запоминаются данные приема пациента. После этого отдел приема посылает сообщение врачу для подтверждения приема больного. В это сообщение включаются регистрационный номер пациента и его фамилия, порядковый номер приема, дата начала лечения и номер палаты.
В день приема пациент сообщает в отдел приема о своем прибытии и передает данные о себе (или изменения в данных). Отдел приема проверяет и при необходимости корректирует данные о пациенте. Если пациент не помнит свой регистрационный номер, то выполняется соответствующий запрос. После регистрации пациент получает регистрационную карту, содержащую ФИО пациента, адрес, дату рождения, номер телефона, группу крови, название страховой компании и номер страховки.
Во время пребывания в больнице пациент может лечиться у нескольких врачей; каждый врач назначает один или более курсов лечения, но каждый курс лечения назначается только одним врачом. Данные о курсах лечения передаются в медицинский секретариат, который занимается координацией лечения пациентов, регистрируются и хранятся там. Данные включают номер врача, номер пациента, порядковый номер приема, название курса лечения, дату назначения, время и примечания.
При необходимости врач запрашивает в медицинском секретариате историю болезни пациента, содержащую данные о курсах лечения, полученных пациентом.
Используя панель инструментов (рис.7), создайте контекстную DFD диаграмму, моделирующую потоки данных поликлиники, следуя (рис. 8).
Главная цель контекстной диаграммы потоков данных — продемонстрировать, как каждый процесс преобразует входные данные в выходные, а также выявить отношения между этими процессами.
Диаграммы верхних уровней иерархии (контекстные диаграммы) определяют основные процессы или подсистемы с внешними входами и выходами. Как видно из рис. 8, происходит обмен данными с внешними сущностями и хранилищами данных.
Отметьте, что стрелки имеют разный цвет. Это для того, чтобы после декомпозиции диаграммы на диаграмме нижнего уровня было понятно, с какой внешней сущностью происходит обмен потоками данных.
- Создайте на контекстной диаграмме процесс, выбрав на панели инструментов инструмент Процесс, представленный прямоугольником с закругленными углами.
 |
Рис. 8. Контекстная диаграмма
- Задайте в контекстном меню свойства процесса: Name (Имя) – Система приема пациентов (рис. 9); Color (цвет) – выберите фиолетовый цвет, шрифт. Введите имя – Система приема пациентов. На вкладке Fonts (рис. 10) задайте шрифт с набором кириллицы и отметьте флажки:
All activities on this diagram
All activities in this model
Change all occurences of font in model
На вкладке Color выбирается цвет диаграммы.
 |
Рис. 9. Окно свойств процесса
Укажите на вкладке Fonts
 |
Рис. 10. Задание шрифта
Полученное изображение процесса можно перемещать, изменять его размер
- Добавьте на контекстную диаграмму внешние сущности: Пациент, Врач, Администрация больницы, выбирая последовательно инструмент External ReferenceTool (Сущность рис. 7).
- Задайте имена сущностям, используя контекстное меню и соответствующую вкладку появившегося окна.
- Добавьте на контекстную диаграмму потоки данных. Стрелки создаются инструментом с изображением горизонтальной стрелки Precedence Arrow Tool.
Если стрелка выходит из сущности или другого процесса, необходимо щелкнуть стрелкой в крайней области объекта так, чтобы появился затемненный треугольник. Обозначить щелчком левой кнопки мыши начало стрелки и, не отпуская нажатую клавишу мыши, протащить стрелку до нужной части другого объекта, пока не появится затемненный сектор. Отпустить клавишу.
- Правой кнопкой вызовите контекстное меню. Задайте имя процесса, цвет стрелки.
- Таким же образом добавьте стрелки, выходящие из Процесса.
- Сохраните файл с именем Поликлиника с лабораторными работами и отчетами.
Задание 5. Декомпозиция контекстной диаграммы
Декомпозиция (процесс разбиения) продолжается до тех пор, пока не будет достигнут уровень, на котором процессы становятся элементарными и детализировать их далее невозможно.
- Перейдите на следующий уровень декомпозиции, щелкнув по кнопке «Переход к дочернему уровню» (рис. 7).
- Задайте количество подпроцессов на листе декомпозиции – 3. Назовите их, как указано на рис. 11.
- Продлите стрелки, перешедшие с контекстной диаграммы до нужного процесса (рис. 11). Источники информации (внешние сущности) порождают информационные потоки (потоки данных), переносящие информацию к подсистемам или процессам. Те, в свою очередь, преобразуют информацию и порождают новые потоки, которые переносят информацию к другим процессам или подсистемам, накопителям данных или внешним сущностям – потребителям информации.
 |
Рис. 11. Диаграмма декомпозиции
Задание 6. Самостоятельная работа
Проделайте еще одну декомпозицию процесса «Администрирование врачей и пациентов». На диаграмме декомпозиции создайте процессы «Обслужить пациента» и «Подготовить отчет о пациенте», «Зарегистрировать пациента», «Зарегистрировать врача».
Задание 7. Оформление отчета
Оформить отчет, в котором сделать описание данных, составляющих диаграммы:
|
Таблица 1. Накопители данных |
|
Название накопителя |
Атрибуты |
Откуда поступает информация |
Куда передается |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Описать данные, которые могут быть представлены для отчетов:
Данные о принятых за день пациентах; История болезни пациента.
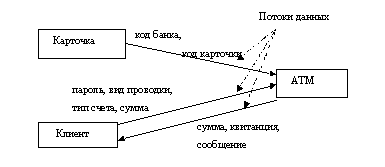
Задание 8. Анализ информационных процессов при снятии денег со счета в банке.
Создать контекстную диаграмму (DFD). Придумать ей название.
Постановка задачи: Создать диаграмму потоков данных процесса «Снятия денег клиентом со счета в банке».
Процесс происходит следующим образом:
- клиент вставляет свою карточку в банкомат;
- банкомат выдает приветствие и предлагает клиенту ввести свой персональный идентификационный номер;
- клиент вводит номер;
- банкомат выводит список доступных действий:
- снять деньги со счета;
- проверить счет;
- клиент выбирает пункт «Снять деньги»;
- банкомат запрашивает, сколько денег нужно снять;
- Клиент вводит требуемую сумму;
- банкомат определяет, достаточно ли на счету денег;
- банкомат вычитает требуемую сумму из счета клиента;
- банкомат выдает клиенту требуемую сумму наличными;
- банкомат возвращает клиенту его карточку.
Задание 9. Декомпозиция контекстной диаграммы.
- Придумать, на какие процессы разбить контекстную диаграмму.
- Определить накопители, участвующие в процессе и описать атрибуты данных, хранящихся в них.
- Процессы на подчиненном уровне обозначить разным цветом.
Задание 10. Альтернативные процессы.
Измените созданную диаграмму с учетом следующих условий:
банкомат подтверждает введенный клиентом номер. Если номер не подтверждается, выполняется альтернативный поток событий.
Ввод неправильного идентификационного номера:
- клиент получает информацию о том, что введен неправильный пин-код;
- банкомат возвращает клиенту его карточку.
Если денег на счету меньше суммы, затребованной клиентом, то выполняется следующий поток событий:
Сумма на счету меньше требуемой:
- банкомат информирует клиента, что денег на его счету недостаточно;
- банкомат возвращает клиенту его карточку.
Контрольные вопросы
- Какова цель создания диаграммы потоков данных DFD?
- Как можно использовать результат конечной декомпозиции?
- Что такое внешняя сущность? Привести примеры.
- Зачем используются цвета на диаграмме?
- Что такое накопитель данных?
- Опишите компоненты диаграммы потоков данных, их вид и назначение.
Версия для печати

Оценка и аудит

Подготовка к сертификации

Описание бизнесс-процессов

Тренинги и обучение
Моделирование потоков данных. Диаграммы DFD.
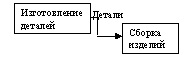
Одним из важнейших способов описания процесса являются диаграммы потоков данных (информации) DFD (Data Flow Diagram). Подобные диаграммы содержат, как правило, два типа графических объектов: четырехугольники и стрелки. Первые описывают функции (работы, процессы), вторые — потоки данных между этими функциями. Простейшая схема процесса в формате DFD показана ниже.

На диаграмме DFD функции обычно располагаются слева направо в порядке, соответствующем последовательности их выполнения во времени, хотя это не является обязательным. Если придерживаться указанного требования, то полученная схема — это описание процесса, которое схоже с описанием процесса в нотации IDEF3. К описанию процессов в DFD применимы типовые правила декомпозиции. Что касается сторон четырехугольников, то в нотации DFD они не имеют того значения, как в IDEF0.
Часто нотацию DFD путают с простым описанием потоков информации между подразделениями. Это далеко не одно и то же. Почему нельзя рассматривать простое описание потоков между подразделениями организации как схему процесса? В каждом большом подразделении (например, отдел сбыта крупного предприятия) выполняются различные бизнес-процессы. Часто у этих процессов существуют различные внутренние и внешние клиенты.
Версия для печати
Именно поэтому схема потоков информации между подразделениями, описывает только потоки данных, пересекающие границы подразделений, но не содержит всей информации о внешних и внутренних изменениях потока информации. То есть диаграмма DFD содержит шаги модификаций/изменений информации от одного действия к другому. При этом, описание потоков информации между подразделениями является практически важным и широко используемым инструментом.
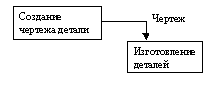
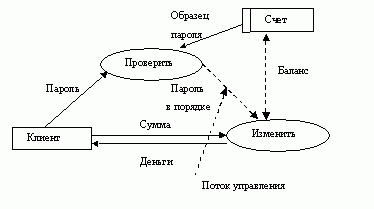
Пример описания процесса в DFD можно усложнить, используя понятие «хранилище данных». Под этим понимается любой носитель информации, например, бумажный документ, электронный файл, промышленная база данных на сервере организации и т.д. При построении модели процесса с использованием хранилищ данных, необходимо помнить, что данные (информация) не могут перемещаться между функциями процесса сами по себе. Их можно передавать только через определенных посредников — носителей информации или, что то же самое, хранилищ данных. Ниже представлена модель процесса в нотации DFD, построенная с использованием понятия «хранилище данных».

Для чего служат нотации DFD? В первую очередь они нужны для описания реально существующих в организации потоков данных. Описания могут создаваться как по процессному, так и по функциональному признаку. В первом случае мы получаем модели бизнес-процессов в формате DFD, во втором — схему обмена данными между подразделениями. Созданные модели потоков Данных организации могут быть использованы при решении таких задач, как:
- определение существующих хранилищ данных (текстовые документы, файлы, Система управления базой данных — СУБД);
- определение и анализ данных, необходимых для выполнения каждой функции процесса;
- подготовка к созданию модели структуры данных организации, так называемая ERD-модель (IDEF1X);
- выделение основных и вспомогательных бизнес-процессов организации.
Следует отметить что нотация DFD может быть эффективно применена для описания потоков документов или потоков материальных ресурсов.
Более того, нотация DFD может быть несколько модернизирована таким образом, чтобы на одной диаграмме можно было бы показать как потоки данных, так и потоки материальных ресурсов.

На практике при создании моделей процессов часто бывает полезно использовать несколько способов описания. Сначала, например, мы создаем модель в нотации IDEF0, выявляем функции, входящие в процесс. Затем проводим декомпозицию процесса. При достижении некоторого уровня детализации (три-четыре) становится целесообразно сформировать для каждого детального процесса несколько схем в различных форматах: управление — IDEF0, а потоки данные и материалов — в DFD.
Studepedia.org — это Лекции, Методички, и много других полезных для учебы материалов
Studepedia.org — это постоянно обновляющаяся большая база учебных материалов (на даный момент 166 тыс. 848 статей) для студентов и учителей.
Последнее поступление — 5 Марта, 2018
СИСТЕМА СПЕЦИАЛЬНЫХ УПРАЖНЕНИЙ ДЛЯ ОТРАБОТКИ ПОЛНОЦЕННЫХ НАВЫКОВ ЧТЕНИЯ И ПИСЬМА (Педагогика)
Обучаем читать и писать без ошибок: Комплекс упражнений (Педагогика)
ИСТОРИЯ ПСИХОЛОГИИ от античности до середины ХХ в. 1 страница (Психология)
СОЦИОЛОГИЯ (Социология)
Методика развития связной речи у детей с системным недоразвитием речи (Педагогика)
Жизнь Галилея 1 страница (Философия)
Чудо голодания 1 страница (Медицина, Здоровье)
Эрих Фромм. Мужчина и женщина (Психология)
Покупка автомобиля (Финансы, Менеджмент)
Назначения зубчатых колес и передач. (Машиностроение)
ЗОЛОТОЙ ЛОТОС, СБОРНИК ФАНТАСТИЧЕСКИХ ПОВЕСТЕЙ И РАССКАЗОВ (Литература)
Живопись XX Века (Культура, Искусство)
Проектная разработка автоматизированной линии кормления животных с использованием личинок насекомых в качестве живого корма (Агрономия, Сельское хозяйство)
О культуре научного исследования — 1 страница (Психология)
Жак Фреско, Роксана Медоуз — Все лучшее, что не купишь за деньги (Философия)
Статья 5. Независимость профсоюзов (Право)
Эрнст Неизвестный. Становление стиля. 1950-1960 гг (Культура, Искусство)
Запрос о предоставлении сведений (Право)
Учет анатомо-физиологических особенностей детей в организации их двигательной деятельности (Спорт)
Пролог на небесах (Литература)
Тема 1.
Базы данных. Вопрос №14
Введение. Роль науки и техники в истории человечества (Естествознание)
Семья – это мир, в котором нам уютно (Педагогика)
ЭПИГРАФ 1 страница (Изучение языков)
Основные характеристики электрического тока. (Электроника)
Спроектировать локально-вычислительную сеть (ЛВС) компании (Информатика)
Работа с записями и одномерными массивами. (Информатика)
Простые геометрические вычисления. (Математика)
Простые вычисления с числами целых и вещественных типов. (Информатика)
Структура предприятия и организационная структура управления (Финансы, Менеджмент)
Органы растений (Биология, Зоология, Анатомия)
Первая | Предыдущая |1 | 2 | 3 | Следующая | Последняя
Лабораторная работа № 6.
Построение диаграммы декомпозиции в нотации DFD
Цель работы:
- построить диаграмму декомпозиции в нотации DFD одной из работ диаграмм IDEF0, построенных в предыдущих лабораторных работах
Диаграммы потоков данных (Data flow diagram, DFD) используются для описания документооборота и обработки информации. Подобно IDEF0, DFD представляет моделируемую систему как сеть связанных между собой работ. Их можно использовать как дополнение к модели IDEF0 для более наглядного отображения текущих операций документооборота в корпоративных системах обработки информации. Главная цель DFD — показать, как каждая работа преобразует свои входные данные в выходные, а также выявить отношения между этими работами.
Любая DFD-диаграмма может содержать работы, внешние сущности, стрелки (потоки данных) и хранилища данных.
Работы. Работы изображаются прямоугольниками с закругленными углами (рис. 1), смысл их совпадает со смыслом работ IDEF0 и IDEF3. Так же как работы IDEF3, они имеют входы и выходы, но не поддерживают управления и механизмы, как IDEF0. Все стороны работы равнозначны. В каждую работу может входить и выходить по несколько стрелок.
Внешние сущности. Внешние сущности изображают входы в систему и/или выходы из нее. Одна внешняя сущность может одновременно предоставлять входы (функционируя как поставщик) и принимать выходы (функционируя как получатель). Внешняя сущность представляет собой материальный объект, например заказчики, персонал, поставщики, клиенты, склад. Определение некоторого объекта или системы в качестве внешней сущности указывает на то, что они находятся за пределами границ анализируемой системы. Внешние сущности изображаются в виде прямоугольника с тенью и обычно располагаются по краям диаграммы (рис. 2).

Стрелки (потоки данных).Стрелки описывают движение объектов из одной части системы в другую (отсюда следует, что диаграмма DFD не может иметь граничных стрелок). Поскольку все стороны работы в DFD равнозначны, стрелки могут могут начинаться и заканчиваться на любой стороне прямоугольника. Стрелки могут быть двунаправлены.
Хранилище данных. В отличие от стрелок, описывающих объекты в движении, хранилища данных изображают объекты в покое (рис. 3). Хранилище данных — это абстрактное устройство для хранения информации, которую можно в любой момент поместить в накопитель и через некоторое время извлечь, причем способы помещения и извлечения могут быть любыми. Оно в общем случае является прообразом будущей базы данных, и описание хранящихся в нем данных должно соответствовать информационной модели (Entity-Relationship Diagram).

Декомпозиция работы IDEF0 в диаграмму DFD. При декомпозиции работы IDEF0 в DFD необходимо выполнить следующие действия:
- удалить все граничные стрелки на диаграмме DFD;
- создать соответствующие внешние сущности и хранилища данных;
- создать внутренние стрелки, начинающиеся с внешних сущностей вместо граничных стрелок;
- стрелки на диаграмме IDEF0 затоннелировать
Строго придерживаться правил нотации DFD не всегда удобно, поэтому BPWin позволяет создавать в DFD диаграммах граничные стрелки.
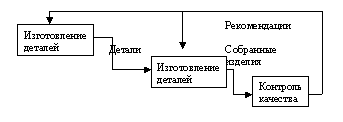
Построение диаграммы декомпозиции. Проведем декомпозицию работы Отгрузка и снабжение диаграммы А0 «Деятельность предприятия по сборке и продаже компьютеров и ноутбуков». В этой работе мы выделили следующие дочерние работы:
- снабжение необходимыми комплектующими — занимается действиями, связанными с поиском подходящих поставщиков и заказом у них необходимых комплектующих
- хранение комплектующих и собранных компьютеров
- отгрузка готовой продукции — все действия, связанные с упаковкой, оформлением документации и собственно отгрузкой готовой продукции
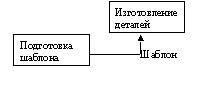
Выделим работу Отгрузка и снабжение диаграммы А0 «Деятельность предприятия по сборке и продаже компьютеров и ноутбуков», нажмем на кнопку «Go to Child Diagram» панели инструментов и выберем нотацию DFD. При создании дочерней диаграммы BPWin переносит граничные стрелки родительской работы, их необходимо удалить и заменить на внешние сущности. Стрелки механизмов, стрелки управления «Правила и процедуры», «Управляющая информация» и стрелку выхода «Отчеты» на дочерней диаграмме задействованы не будут, чтоб не загромождать диаграмму менее существенными деталями. Остальные стрелки заменим на внешние сущности — кнопка «External Reference Tool» на панели инструментов, в появившемся окне выбрать переключатель «Arrow» и выбрать из списка нужное название (рис. 4):

Далее разместим дочерние работы, свяжем их со внешнеми сущностями и между собой (рис.
Моделирование бизнес-процессов средствами BPwin (часть 2)
5):

Центральной здесь является работа «Хранение комплектующих и собранных компьютеров». На ее вход поступают собранные компьютеры и полученные от поставщиков комплектующие, а также список необходимых для сборки компьютеров комплектующих. Выходом этой работы будут необходимые комплектующие (если они есть в наличии), список отсутствующих комплектующих, передаваемый на вход работы «Снабжение необходимыми комплектующими» и собранные компьютеры, передаваемые на отгрузку. Выходами работ «Снабжение необходимыми комплектующими» и «Отгрузка готовой продукции» будут, соответственно, заказы поставщикам и готовая продукция.
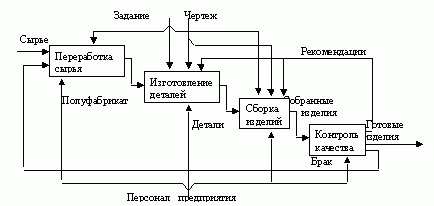
Следующим шагом необходимо определить, какая информация необходима для каждой работы, т.е. необходимо разместить на диаграмме хранилища данных (рис. 6).
Работа «Снабжение необходимыми комплектующими» работает с информацией о поставщиках и с информацией о заказах, сделанных у этих поставщиков. Стрелка, соединяющая работу и хранилище данных «Список поставщиков» двунаправленная, т.к. работа может как получать информацию о имеющихся поставщиках, так и вносить данные о новых поставщиках. Стрелка, соединяющая работу с хранилищем данных «Список заказов» однонаправленная, т.к. работа только вносит информацию о сделанных заказах.
Работа «Хранение комплектующих и собранных компьютеров» работает с информацией о получаемых и выдаваемых комплектующих и собранных компьютеров, поэтому стрелки, соединяющая работу с хранилищами данных «Список комплектующих» и «Список собранных компьютеров» двунаправленные. Также эта работа при получении комплектующих должна делать отметку о том, что заказ поставщикам выполнен. Для этого она связана с хранилищем данных «Список заказов» однонаправленной стрелкой. Обратите внимание, что на DFD диаграммах одно и тоже хранилище данных может дублироваться.
Наконец, работа «Отгрузка готовой продукции» должна хранить информацию по выполненным отгрузкам. Для этого вводится соответствующее хранилище данных — «Данные по отгрузке».
Последним действием необходимо стрелки родительской работы затуннелировать (рис. 7):

Содержание отчета:
- краткое описание декомпозируемой работы
- диаграмма декомпозиции
Методология функционального моделирования работ SADT
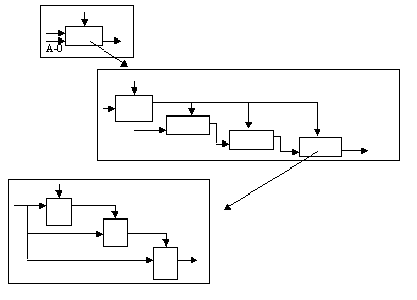
Методология SADT (Structured Analisys and Design Technique — технология структурного анализа и проектирования) разработана Дугласом Т. Россом в 1969-1973 годах. Технология изначально создавалась для проектирования систем более общего назначения по сравнению с другими структурными методами, выросшими из проектирования программного обеспечения. SADT — одна из самых известных и широко используемых методик проектирования. Новое название методики, принятое в качестве стандарта — IDEF0 (Icam DEFinition) — часть программы ICAM (Integrated Computer-Aided Manufacturing — интегрированная компьютеризация производства), проводимой по инициативе ВВС США.
Процесс моделирования в SADT включает сбор информации об исследуемой области, документирование полученной информации и представление ее в виде модели и уточнение модели. Кроме того, этот процесс подсказывает вполне определенный путь выполнения согласованной и достоверной структурной декомпозиции, что является ключевым моментом в квалифицированном анализе системы. SADT уникальна в своей способности обеспечить как графический язык, так и процесс создания непротиворечивой и полезной системы описаний.
В IDEF0 система представляется как совокупность взаимодействующих работ (или функций). Связи между работами определяют технологический процесс или структуру взаимосвязи внутри организации. Модель SADT представляет собой серию диаграмм, разбивающих сложный объект на составные части.
Каждый блок IDEF0-диаграммы может быть представлен несколькими блоками, соединенными интерфейсными дугами, на диаграмме следующего уровня. Эти блоки представляют подфункции (подмодули) исходной функции. Каждый из подмодулей может быть декомпозирован аналогичным образом. Число уровней не ограничивается, зато рекомендуется на одной диаграмме использовать не менее 3 и не более 6 блоков.
Работы (activity) обозначают поименованные процессы, функции или задачи, которые происходят в течение определенного времени и имеют распознаваемые результаты (изображается в виде прямоугольников). Каждая из работ на диаграмме может быть впоследствии декомпозирована.
Как отмечалось выше, в терминах IDEF0 система представляется в виде комбинации блоков и дуг. Блоки представляют функции системы, дуги представляют множество объектов (физические объекты, информация или действия, которые образуют связи между функциональными блоками). Взаимодействие работ с внешним миром и между собой описывается в виде стрелок или дуг. С дугами связываются метки на естественном языке, описывающие данные, которые они представляют. Дуги показывают, как функции системы связаны между собой, как они обмениваются данными и осуществляют управление друг другом. Дуги могут разветвляться и соединяться. Ветвление означает множественность (идентичные копии одного объекта) или расщепление (различные части одного объекта). Соединение означает объединение или слияние объектов. Пять типов стрелок допускаются в диаграммах:
Вход (Input) — материал или информация, которые используются работой для получения результата (стрелка, входящая в левую грань).
Управление (Control) — правила, стратегии, стандарты, которыми руководствуется работа (стрелка, входящая в верхнюю грань). В отличии от входной информации управление не подлежит изменению.
Выход (Output) — материал или информация, которые производятся работой (стрелка, исходящая из правой грани). Каждая работа должна иметь хотя бы одну стрелку выхода, т.к. работа без результата не имеет смысла и не должна моделироваться.
Механизм (Mechanism) — ресурсы, которые выполняют работу (персонал, станки, устройства — стрелка, входящая в нижнюю грань).
Вызов (Call) — стрелка, указывающая на другую модель работы (стрелка, исходящая из нижней грани).
Различают в IDEF0 пять типов связей работ.
Связь по входу (input-output), когда выход вышестоящей работы направляется на вход следующей работы.
Связь по управлению (output-control), когда выход вышестоящей работы направляется на управление следующей работы.
Связь показывает доминирование вышестоящей работы.
Обратная связь по входу (output-input feedback), когда выход нижестоящей работы направляется на вход вышестоящей. Используется для описания циклов.
Обратная связь по управлению (output-control feedback), когда выход нижестоящей работы направляется на управление вышестоящей. Является показателем эффективности бизнес-процесса.
Связь выход-механизм (output-mechanism), когда выход одной работы направляется на механизм другой и показывает, что работа подготавливает ресурсы для проведения другой работы.
Из перечисленных блоков, как из отдельных кирпичиков, строится диаграмма. Пример SADT-диаграммы:
Диаграммы потоков данных DFD (Data Flow Diagrams)
Диаграммы потоков данных используются для описания движения документов и обработки информации как дополнение к IDEF0. В отличие от IDEF0, где система рассматривается как взаимосвязанные работы и стрелки представляют собой жесткие взаимосвязи, стрелки в DFD показывают лишь то, как объекты (включая данные) движутся от одной работы к другой. DFD отражает функциональные зависимости значений, вычисляемых в системе, включая входные значения, выходные значения и внутренние хранилища данных. DFD — это граф, на котором показано движение значений данных от их источников через преобразующие их процессы к их потребителям в других объектах.
DFD содержит процессы, которые преобразуют данные, потоки данных, которые переносят данные, активные объекты, которые производят и потребляют данные, и хранилища данных, которые пассивно хранят данные.
Процессы. Процесс преобразует значения данных. Процессы самого нижнего уровня представляют собой функции без побочных эффектов (примерами таких функций являются вычисление суммы двух чисел, вычисление комиссионного сбора за выполнение проводки с помощью банковской карточки и т.п.). Весь граф потока данных тоже представляет собой процесс (высокого уровня). Процесс может иметь побочные эффекты, если он содержит нефункциональные компоненты, такие как хранилища данных или внешние объекты. На DFD процесс изображается в виде эллипса, внутри которого помещается имя процесса; каждый процесс имеет фиксированное число входных и выходных данных, изображаемых стрелками.
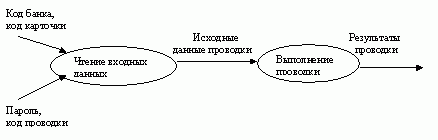
Потоки данных. Поток данных соединяет выход объекта (или процесса) с входом другого объекта (или процесса). Он представляет промежуточные данные вычислений. Поток данных изображается в виде стрелки между производителем и потребителем данных, помеченной именами соответствующих данных. Дуги могут разветвляться или сливаться, что означает, соответственно, разделение потока данных на части, либо слияние объектов.
Активные объекты. Активным называется объект, который обеспечивает движение данных, поставляя или потребляя их. Активные объекты обычно бывают присоединены к входам и выходам DFD.
Хранилища данных. Хранилище данных — это пассивный объект в составе DFD, в котором данные сохраняются для последующего доступа. Хранилище данных допускает доступ к хранимым в нем данным в порядке, отличном от того, в котором они были туда помещены. Агрегатные хранилища данных, как, например, списки и таблицы, обеспечивают доступ к данным в порядке их поступления, либо по ключам.
Потоки управления. DFD показывает все пути вычисления значений, но не показывает в каком порядке значения вычисляются. Решения о порядке вычислений связаны с управлением программой, которое отражается в динамической модели. Эти решения, вырабатываемые специальными функциями, или предикатами, определяют, будет ли выполнен тот или иной процесс, но при этом не передают процессу никаких данных, так что их включение в функциональную модель необязательно. Тем не менее, иногда бывает полезно включать указанные предикаты в функциональную модель, чтобы в ней были отражены условия выполнения соответствующего процесса. Функция, принимающая решение о запуске процесса, будучи включенной в DFD, порождает в DFD поток управления и изображается пунктирной стрелкой.
Первым шагом при построении иерархии DFD является построение контекстных диаграмм. Обычно при проектировании относительно простых информационных систем строится единственная контекстная диаграмма со звездообразной топологией, в центре которой находится так называемый главный процесс, соединенный с приемниками и источниками информации, посредством которых с системой взаимодействуют пользователи и другие внешние системы.
Если же для сложной системы ограничиться единственной контекстной диаграммой, то она будет содержать слишком большое количество источников и приемников информации, которые трудно расположить на листе бумаги нормального формата, и, кроме того, главный единственный процесс не раскрывает структуры распределенной системы.
Для сложных информационных систем строится иерархия контекстных диаграмм. При этом контекстная диаграмма верхнего уровня содержит не главный единственный процесс, а набор подсистем, соединенных потоками данных. Контекстные диаграммы следующего уровня детализируют контекст и структуру подсистем.
При построении иерархии DFD переходить к детализации процессов следует только после определения содержания всех потоков и накопителей данных, которое описывается при помощи структур данных. Структуры данных конструируются из элементов данных и могут содержать альтернативы, условные вхождения и итерации. Условное вхождение означает, что данный компонент может отсутствовать в структуре. Альтернатива означает, что в структуру может входить один из перечисленных элементов. Итерация означает вхождение любого числа элементов в указанном диапазоне. Для каждого элемента данных может указываться его тип (непрерывные или дискретные данные). Для непрерывных данных может указываться единица измерения (кг, см и т.п.), диапазон значений, точность представления и форма физического кодирования. Для дискретных данных может указываться таблица допустимых значений.
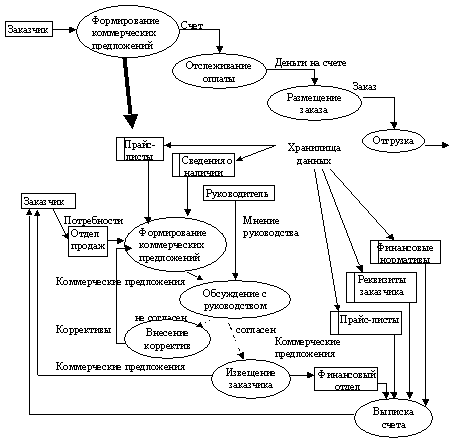
Ниже приведена диаграмма потоков данных верхнего уровня с ее последующим уточнением:
Методология объектного проектирования на языке UML (UML-диаграммы)
Унифицированный язык моделирования (Unified Modeling Language — UML) — это язык для специфицирования, визуализации, конструирования и документирования на основе объектно-ориентированный подхода разные виды систем: программных, аппаратных, программно-аппаратных, смешанных, явно включающие деятельность людей и т. д.
Помимо прочего, язык UML применяется для проектирования реляционных БД. Для этого используется небольшая часть языка (диаграммы классов), да и то не в полном объеме. С точки зрения проектирования реляционных БД модельные возможности не слишком отличаются от возможностей ER-диаграмм
Диаграммой классов в терминологии UML называется диаграмма, на которой показан набор классов (и некоторых других сущностей), не имеющих явного отношения к проектированию БД), а также связей между этими классами. Ограничения могут неформально задаваться на естественном языке или формулироваться на языке объектных ограничений OCL (Object Constraints Language).
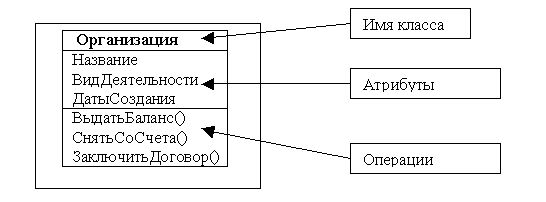
Классом называется именованное описание совокупности объектов с общими атрибутами, операциями, связями и семантикой. Графически класс изображается в виде прямоугольника. Имя (текстовая строка), служит для идентификации класса.
Атрибутом класса называется именованное свойство класса, описывающее множество значений, которые могут принимать экземпляры этого свойства. Класс может иметь любое число атрибутов (в частности, не иметь ни одного атрибута).
Операцией класса называется именованная услуга, которую можно запросить у любого объекта этого класса. Операция — это абстракция того, что можно делать с объектом. Класс может содержать любое число операций (в частности, не содержать ни одной операции). Набор операций класса является общим для всех объектов данного класса.
В диаграмме классов могут участвовать связи трех разных категорий: зависимость (dependency), обобщение (generalization) и ассоциация (association).
Зависимостью называют связь по применению, когда изменение в спецификации одного класса может повлиять на поведение другого класса, использующего первый класс. Если интерфейс второго класса изменяется, это влияет на поведение объектов первого класса. Зависимость показывается прерывистой линией со стрелкой, направленной к классу, от которого имеется зависимость.
Связью-обобщением называется связь между общей сущностью, называемой суперклассом, или родителем, и более специализированной разновидностью этой сущности, называемой подклассом, или потомком. Обобщения иногда называют связями «is a», имея в виду, что класс-потомок является частным случаем класса-предка.
Класс-потомок наследует все атрибуты и операции класса-предка, но в нем могут быть определены дополнительные атрибуты и операции.
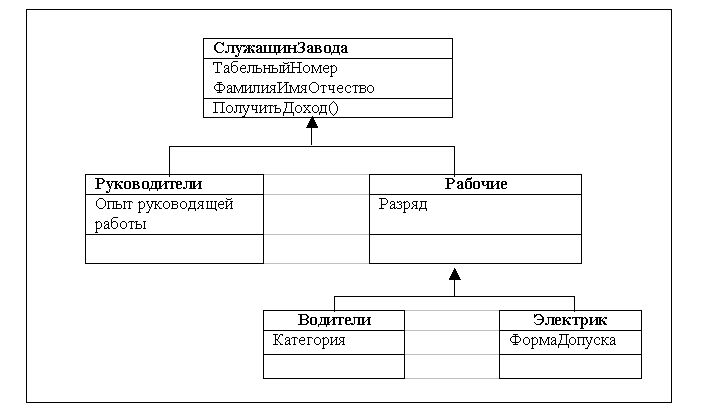
Одиночное наследование, когда у каждого подкласса имеется только один суперкласс) является достаточным в большинстве случаев применения связи-обобщения. Однако в UML допускается и множественное наследование, когда один подкласс определяется на основе нескольких суперклассов.
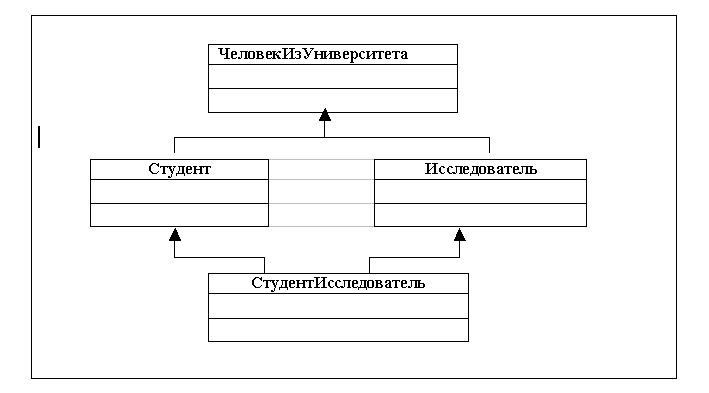
На этой диаграмме классы Студент и Исследователь порождены из одного суперкласса ЧеловекИзУниверситета. К классу Студент относятся те объекты класса ЧеловекИзУниверситета, которые соответствуют студентам, а к классу Исследователь — объекты класса ЧеловекИзУниверситета, соответствующие исследователям. Часто случается, многие студенты уже в студенческие годы начинают участвовать в исследовательских проектах, так что могут существовать такие два объекта классов Студент и Исследователь, которым соответствует один объект класса ЧеловекИзУниверситета. Таким образом среди объектов класса Студент могут быть исследователи, а некоторые исследователи могут быть студентами. Тогда можно определить класс СтудентИсследователь путем множественного наследования от суперклассов Студент и Исследователь. Объект класса СтудентИсследователь обладает всеми свойствами и операциями классов Студент и Исследователь и может быть использован везде, где могут применяться объекты этих классов. Так что полиморфизм по включению продолжает работать. Однако это влечет за собой ряд проблем. Например, при образовании подклассов Студент и Исследователь в них обоих может быть определен атрибут с именем Ip_адресКомпьютера. Для объектов класса Студент значениями этого атрибута будут ip-адрес компьютера терминального класса, а для объектов класса Исследователь — ip-адрес компьютера исследовательской лаборатории. При этом для объекта класса СтудентИсследователь могут быть существенны оба одноименных атрибута (у студента-исследователя могут иметься и ip-адрес компьютера терминального класса и ip-адрес компьютера исследовательской лаборатории). На практике применяется одно из следующих решений:
- запретить образование подкласса СтудентИсследователь, пока в одном из суперклассов не будет произведено переименование атрибута Ip_адресКомпьютера;
- наследовать это свойство только от одного из суперклассов, так что, например, значением атрибута Ip_адресКомпьютера у объектов класса СтудентИсследователь всегда будут ip-адресом компьютера исследовательской лаборатории;
- унаследовать в подклассе оба свойства, но автоматически переименовать оба атрибута, чтобы прояснить их смысл; назвать их, например, Ip_адресКомпьютераСтудента и Ip_адресКомпьютераИсследователя.
Каждое из указанных решений имеет недостатки, поэтому при использовании UML для проектирования реляционных БД нужно очень осторожно использовать наследование классов вообще и стараться избегать множественного наследования.
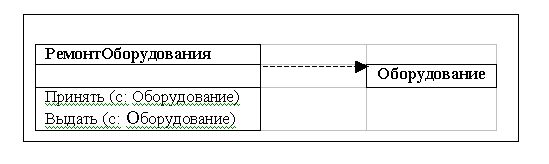
Ассоциацией называется структурная связь, показывающая, что объекты одного класса некоторым образом связаны с объектами другого или того же самого класса.
Допускается, чтобы оба конца ассоциации относились к одному классу. В ассоциации могут связываться два класса, и тогда она называется бинарной. Допускается создание ассоциаций, связывающих сразу n классов (они называются n-арными ассоциациями).1) Графически ассоциация изображается в виде линии, соединяющей класс сам с собой или с другими классами.
С понятием ассоциации связаны четыре важных дополнительных понятия: имя, роль, кратность и агрегация. Ассоциации может быть присвоено имя, характеризующее природу связи. Другим способом именования ассоциации является указание роли каждого класса, участвующего в этой ассоциации. Роль класса, как и имя конца связи в ER-модели, задается именем, помещаемым под линией ассоциации ближе к данному классу.
В общем случае, для ассоциации могут задаваться и ее собственное имя, и имена ролей классов. Связано это с тем, что класс может играть одну и ту же роль в разных ассоциациях, так что в общем случае пара имен ролей классов не идентифицирует ассоциацию. В простых случаях, когда между двумя классами определяется только одна ассоциация, можно вообще не связывать с ней дополнительные имена.
Кратностью (multiplicity) роли ассоциации называется характеристика, указывающая, сколько объектов класса с данной ролью может или должно участвовать в каждом экземпляре ассоциации.
Наиболее распространенным способом задания кратности роли ассоциации является указание конкретного числа или диапазона.
DFD — диаграмма потоков данных
Указание «1» говорит о том, что каждый объект класса с данной ролью должен участвовать в некотором экземпляре данной ассоциации, причем в каждом экземпляре ассоциации может участвовать только один объект класса с данной ролью.
Указание диапазона «0..1» говорит о том, что не все объекты класса с данной ролью обязаны участвовать в каком-либо экземпляре данной ассоциации, но в каждом экземпляре ассоциации может участвовать только один объект. Аналогично, указание диапазона «1..*» говорит о том, что все объекты класса с данной ролью должны участвовать в некотором экземпляре данной ассоциации, и в каждом экземпляре ассоциации должен участвовать хотя бы один объект (верхняя граница не задана). В более сложных случаях определения кратности можно использовать списки диапазонов.

Обычная ассоциация между двумя классами характеризует связь между равноправными сущностями: оба класса находятся на одном концептуальном уровне. Но иногда в диаграмме классов требуется отразить тот факт, что ассоциация между двумя классами имеет специальный вид «часть-целое». В этом случае класс «целое» имеет более высокий концептуальный уровень, чем класс «часть». Ассоциация такого рода называется агрегатной.

В каждом терминальном классе должны быть установлены компьютеры. Поэтому класс Компьютер является «частью» класса ТерминальныйКласс. Роль класса Компьютер необязательна, поскольку принципиально могут существовать терминальные классы без компьютеров. При этом, хотя терминальные классы, не оснащенные компьютерами, не выполняют своей функции, объекты классов ТерминальныйКласс и Компьютер существуют независимо.
Бывают случаи, когда связь «части» и «целого» настолько сильна, что уничтожение «целого» приводит к уничтожению всех его «частей». Агрегатные ассоциации, обладающие таким свойством, называются композитными, или просто композициями.

Любой факультет является частью одного университета, и ликвидация университета приводит к ликвидации всех существующих в нем факультетов, хотя во время существования университета отдельные факультеты могут ликвидироваться и создаваться.
В диаграммах классов могут указываться ограничения целостности, которые должны поддерживаться в проектируемой БД. В UML допускаются два способа определения ограничений: на естественном языке и на языке OCL (Object Constraints Language).
С точки зрения определения ограничений целостности баз данных более важны средства определения инвариантов классов.
Под инвариантом класса в OCL понимается условие, которому должны удовлетворять все объекты данного класса. Если говорить более точно, инвариант класса — это логическое выражение, вычисление которого должно давать истину при создании любого объекта данного класса и сохранять истинное значение в течение всего времени существования этого объекта. При определении инварианта требуется указать имя класса и выражение, определяющее инвариант указанного класса. Синтаксически это выглядит следующим образом:
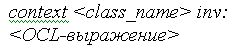
Ниже приведены примеры инвариантов для задания ограничений на языке OCL.
1. Выразить на языке OCL ограничение, в соответствии с которым в отделах с номерами больше 5 должны работать сотрудники старше 30 лет
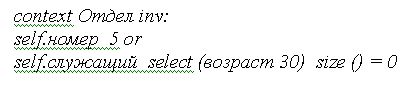
2. Определить ограничение, в соответствии с которым у каждого отдела должен быть менеджер и любой отдел должен быть основан не раньше соответствующей компании

3. Условие четвертого инварианта ограничивает максимально возможное количество сотрудников компании числом 1000
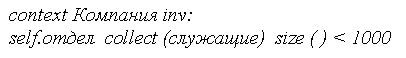
Модели «Сущность-связь» (ERD — Entity-Relationship Diagrams)
См. учебное пособие «Основы проектирования реляционных баз данных»
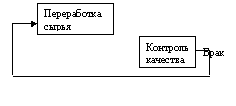
DFD — общепринятое сокращение от англ. Data Flow Diagrams — диаграммы потоков данных.
Так называется методология графического структурного анализа, описывающая внешние по отношению к системе источники и адресаты данных, логические функции, потоки данных и хранилища данных, к которым осуществляется доступ. Диаграмма потоков данных (data flow diagram, DFD) — один из основных инструментов структурного анализа и проектирования информационных систем, существовавших до широкого распространения UML.
Диаграммы потоков данных
Несмотря на имеющее место в современных условиях смещение акцентов от структурного к объектно-ориентированному подходу к анализу и проектированию систем, «старинные» структурные нотации по-прежнему широко и эффективно используются как в бизнес-анализе, так и в анализе информационных систем.
Исторически сложилось так, что для описания диаграмм DFD используются две нотации — Йордана (Yourdon) и Гейна-Сарсона (Gane-Sarson), отличающиеся синтаксисом. Информационная система принимает извне потоки данных. Для обозначения элементов среды функционирования системы используется понятие внешней сущности. Внутри системы существуют процессы преобразования информации, порождающие новые потоки данных. Потоки данных могут поступать на вход к другим процессам, помещаться (и извлекаться) в накопители данных, передаваться к внешним сущностям.
Модель DFD, как и большинство других структурных моделей — иерархическая модель. Каждый процесс может быть подвергнут декомпозиции, то есть разбиению на структурные составляющие, отношения между которыми в той же нотации могут быть показаны на отдельной диаграмме. Когда достигнута требуемая глубина декомпозиции — процесс нижнего уровня сопровождается мини-спецификацией (текстовым описанием). Кроме того, нотация DFD поддерживает понятие подсистемы — структурного компонента разрабатываемой системы.
Нотация DFD — удобное средство для формирования контекстной диаграммы, то есть диаграммы, показывающей разрабатываемую АИС в коммуникации с внешней средой. Это — диаграмма верхнего уровня в иерархии диаграмм DFD. Её назначение — ограничить рамки системы, определить, где заканчивается разрабатываемая система и начинается среда. Другие нотации, часто используемые при формировании контекстной диаграммы — диаграмма SADT, Диаграмма вариантов использования. [29, 30]
Нотация DFD предназначена для описания информационных потоков в обследуемой организации. Объекты нотации DFD показаны в табл. 1. Наличие объектов «хранилище данных» и двунаправленных стрелок позволяет наиболее эффективно описать документооборот и требования к информационной системе.
Таблица 1. Объекты нотации DFD

На рис. 1 показан пример диаграммы DFD.

Рис. 1. Пример описания документооборота в нотации DFD
FILED UNDER : IT